
一、HBase简介
1.1、HBase 定义
Apache HBase 是以 HDFS 为数据存储的,一种分布式、可扩展的 NoSQL 数据库。
1.2、HBase 数据模型
HBase 的设计理念依据 Google 的 BigTable 论文,论文中对于数据模型的首句介绍。
Bigtable 是一个稀疏的、分布式的、持久的多维排序 map。
之后对于映射的解释如下:
该映射由行键、列键和时间戳索引;映射中的每个值都是一个未解释的字节数组。
最终 HBase 关于数据模型和 BigTable 的对应关系如下:
HBase 使用与 Bigtable 非常相似的数据模型。用户将数据行存储在带标签的表中。数据行具有可排序的键和任意数量的列。该表存储稀疏,因此如果用户喜欢,同一表中的行可以具有疯狂变化的列。
最终理解 HBase 数据模型的关键在于稀疏、分布式、多维、排序的映射。其中映射 map指代非关系型数据库的 key-Value 结构。
1.2.1、HBase 逻辑结构
HBase 可以用于存储多种结构的数据,以 JSON 为例,存储的数据原貌为:
{
"row_key1":{
"personal_info":{
"name":"zhangsan",
"city":"北京",
"phone":"131********"
},
"office_info":{
"tel":"010-1111111",
"address":"atguigu"
}
},
"row_key11":{
"personal_info":{
"city":"上海",
"phone":"132********"
},
"office_info":{
"tel":"010-1111111"
}
}
}
HBase 逻辑结构:
存储数据稀疏,数据存储多维,不同的行具有不同的列。
数据存储整体有序,按照 RowKey 的字典序排列,RowKey 为 Byte 数组。
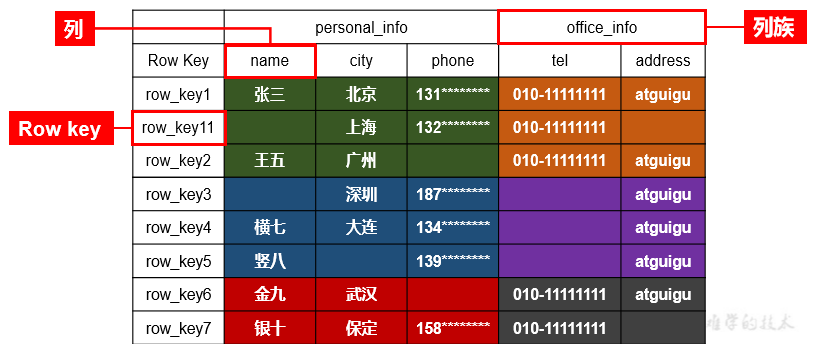
1.2.2、HBase 物理存储结构
物理存储结构即为数据映射关系,而在概念视图的空单元格,底层实际根本不存储。
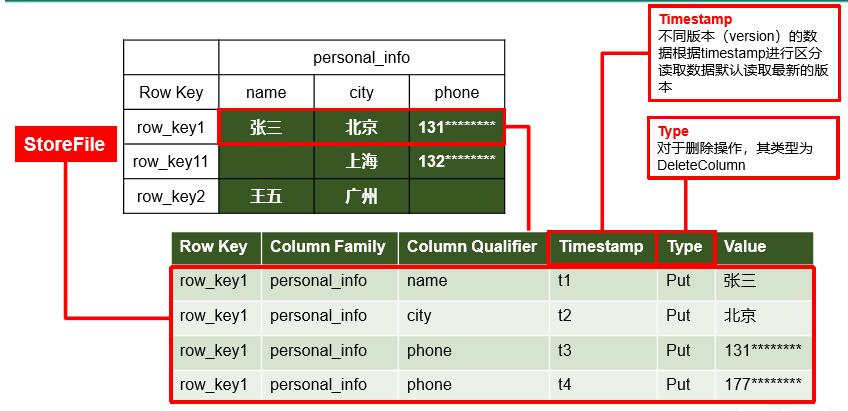
1.2.3、数据模型
1、Name Space
命名空间,类似于关系型数据库的 database 概念,每个命名空间下有多个表。HBase 两个自带的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 是用户默认使用的命名空间。
2、Table
类似于关系型数据库的表概念。不同的是,HBase 定义表时只需要声明列族即可,不需要声明具体的列。因为数据存储时稀疏的,所有往 HBase 写入数据时,字段可以动态、按需指定。因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景。
3、Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey 的字典顺序存储的,并且查询数据时只能根据 RowKey 进行检索,所以 RowKey 的设计十分重要。
4、Column
HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name , info:age。建表时,只需指明列族,而列限定符无需预先定义。
5、TimeStamp
用于标识数据的不同版本(version),每条数据写入时,系统会自动为其加上该字段,其值为写入 HBase 的时间。
6、Cell
由{rowkey, column Family:column Qualifier, timestamp} 唯一确定的单元。cell 中的数据全部是字节码形式存贮。
1.3、HBase 基本架构
Master
主要进程,具体实现类为 HMaster,通常部署在namenode上。 功能:负责通过 ZK 监控 RegionServer 进程状态,同时是所有元数据变化的接口。内部启动监控执行 region 的故障转移和拆分的线程。
RegionServer
主要进程,具体实现类为 HRegionServer,部署在datanode上。 功能:主要负责数据 cell 的处理。同时在执行区域的拆分和合并的时候, 由 RegionServer 来实际执行。
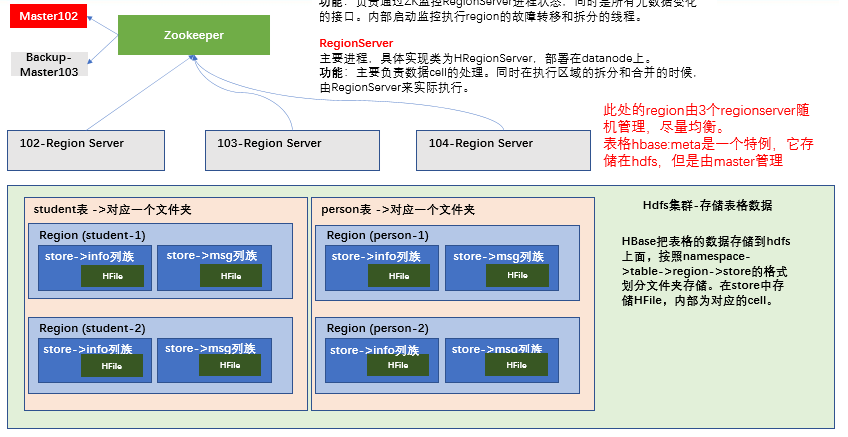
架构角色:
1.3.1、Master
实现类为 HMaster,负责监控集群中所有的 RegionServer 实例。主要作用如下:
(1)管理元数据表格 hbase:meta,接收用户对表格创建修改删除的命令并执行。
(2)监控 region 是否需要进行负载均衡,故障转移和 region 的拆分。
通过启动多个后台线程监控实现上述功能:
- 1、
LoadBalancer 负载均衡器
周期性监控 region 分布在 regionServer 上面是否均衡,由参数hbase.balancer.period控制周期时间,默认 5 分钟。 - 2、
CatalogJanitor 元数据管理器
定期检查和清理hbase:meta中的数据。meta 表内容在进阶中介绍。 - 3、
MasterProcWAL master 预写日志处理器
把 master 需要执行的任务记录到预写日志 WAL 中,如果 master 宕机,让 backupMaster 读取日志继续干。
1.3.2、Region Server
Region Server 实现类为 HRegionServer,主要作用如下:
(1)负责数据 cell 的处理,例如写入数据 put,查询数据 get 等。
(2)拆分合并 region 的实际执行者,有 master 监控,有 regionServer 执行。
1.3.3、Zookeeper
HBase 通过 Zookeeper 来做 master 的高可用、记录 RegionServer 的部署信息、并且存储有 meta 表的位置信息。
HBase 对于数据的读写操作时直接访问 Zookeeper 的,在 2.3 版本推出 Master Registry 模式,客户端可以直接访问 master。使用此功能,会加大对 master 的压力,减轻对 Zookeeper 的压力。
1.3.4、HDFS
HDFS 为 Hbase 提供最终的底层数据存储服务,同时为 HBase 提供高容错的支持。
二、HBase入门
2.1、HBase 安装部署
2.1.1、Zookeeper 正常部署
首先保证 Zookeeper 集群的正常部署,并启动之。
[atguigu@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[atguigu@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
2.1.2、Hadoop 正常部署
Hadoop 集群的正常部署并启动。
[atguigu@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
2.1.3、HBase 的解压
1)解压 Hbase 到指定目录
[atguigu@hadoop102 software]$ tar -zxvf hbase-2.4.11-bin.tar.gz -C /opt/module/
[atguigu@hadoop102 software]$ mv /opt/module/hbase-2.4.11 /opt/module/hbase
2)配置环境变量
sudo vim /etc/profile.d/my_env.sh
添加
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
3)使用 source 让配置的环境变量生效
source /etc/profile.d/my_env.sh
2.1.4、HBase 的配置文件
1)hbase-env.sh 修改内容,可以添加到最后:
# 不启用HBase自带的Zookeeper集群
export HBASE_MANAGES_ZK=false
2)hbase-site.xml 修改内容:
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
<description>The directory shared by RegionServers.
</description>
</property>
<!-- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 记得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到临时文件夹-->
<!-- </description>-->
<!-- </property>-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
3)regionservers文件
hadoop102
hadoop103
hadoop104
4)解决 HBase 和 Hadoop 的 log4j 兼容性问题,修改 HBase 的 jar 包,使用 Hadoop 的 jar 包
[atguigu@hadoop102 hbase]$ mv /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
2.1.5、HBase 远程发送到其他集群
[atguigu@hadoop102 module]$ xsync hbase/
2.1.6、HBase 服务的启动
1)单点启动
[atguigu@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[atguigu@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver
2)群启
[atguigu@hadoop102 hbase]$ bin/start-hbase.sh
3)对应的停止服务
[atguigu@hadoop102 hbase]$ bin/stop-hbase.sh
2.1.7、查看 HBase 页面
启动成功后,可以通过 http://hadoop102:16010 来访问 HBase 管理页面(HBase Master),例如:
2.1.8、高可用(可选)
在 HBase 中 HMaster 负责监控 HRegionServer 的生命周期,均衡 RegionServer 的负载,如果 HMaster 挂掉了,那么整个 HBase 集群将陷入不健康的状态,并且此时的工作状态并不会维持太久。所以 HBase 支持对 HMaster 的高可用配置。
1)关闭 HBase 集群(如果没有开启则跳过此步)
[atguigu@hadoop102 hbase]$ bin/stop-hbase.sh
2)在 conf 目录下创建 backup-masters 文件
[atguigu@hadoop102 hbase]$ touch conf/backup-masters
3)在 backup-masters 文件中配置高可用 HMaster 节点
[atguigu@hadoop102 hbase]$ echo hadoop103 > conf/backup-masters
4)将整个 conf 目录 scp 到其他节点
[atguigu@hadoop102 hbase]$ xsync conf
5)重启 hbase,打开页面测试查看http://hadooo102:16010
2.1.9、HBase单机部署
hbase-site.xml 修改内容:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/module/hbase/tmp</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>
单点启动
bin/start-hbase.sh
或者
[atguigu@hadoop102 hbase]$ bin/hbase-daemon.sh start master
[atguigu@hadoop102 hbase]$ bin/hbase-daemon.sh start regionserver
2.2、HBase Shell 操作
2.2.1、基本操作
1)进入 HBase 客户端命令行
[atguigu@hadoop102 hbase]$ bin/hbase shell
2)查看帮助命令
能够展示 HBase 中所有能使用的命令,主要使用的命令有 namespace 命令空间相关,DDL 创建修改表格,DML 写入读取数据。
hbase:001:0> help
HBase Shell, version 2.4.11, r7e672a0da0586e6b7449310815182695bc6ae193, Tue Mar 15 10:31:00 PDT 2022
Type 'help "COMMAND"', (e.g. 'help "get"' -- the quotes are necessary) for help on a specific command.
Commands are grouped. Type 'help "COMMAND_GROUP"', (e.g. 'help "general"') for help on a command group.
COMMAND GROUPS:
Group name: general
Commands: processlist, status, table_help, version, whoami
Group name: ddl
Commands: alter, alter_async, alter_status, clone_table_schema, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filters
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables
Group name: dml
Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve
Group name: tools
Commands: assign, balance_switch, balancer, balancer_enabled, catalogjanitor_enabled, catalogjanitor_run, catalogjanitor_switch, cleaner_chore_enabled, cleaner_chore_run, cleaner_chore_switch, clear_block_cache, clear_compaction_queues, clear_deadservers, clear_slowlog_responses, close_region, compact, compact_rs, compaction_state, compaction_switch, decommission_regionservers, flush, get_balancer_decisions, get_balancer_rejections, get_largelog_responses, get_slowlog_responses, hbck_chore_run, is_in_maintenance_mode, list_deadservers, list_decommissioned_regionservers, major_compact, merge_region, move, normalize, normalizer_enabled, normalizer_switch, recommission_regionserver, regioninfo, rit, snapshot_cleanup_enabled, snapshot_cleanup_switch, split, splitormerge_enabled, splitormerge_switch, stop_master, stop_regionserver, trace, unassign, wal_roll, zk_dump
Group name: replication
Commands: add_peer, append_peer_exclude_namespaces, append_peer_exclude_tableCFs, append_peer_namespaces, append_peer_tableCFs, disable_peer, disable_table_replication, enable_peer, enable_table_replication, get_peer_config, list_peer_configs, list_peers, list_replicated_tables, remove_peer, remove_peer_exclude_namespaces, remove_peer_exclude_tableCFs, remove_peer_namespaces, remove_peer_tableCFs, set_peer_bandwidth, set_peer_exclude_namespaces, set_peer_exclude_tableCFs, set_peer_namespaces, set_peer_replicate_all, set_peer_serial, set_peer_tableCFs, show_peer_tableCFs, update_peer_config
Group name: snapshots
Commands: clone_snapshot, delete_all_snapshot, delete_snapshot, delete_table_snapshots, list_snapshots, list_table_snapshots, restore_snapshot, snapshot
Group name: configuration
Commands: update_all_config, update_config
Group name: quotas
Commands: disable_exceed_throttle_quota, disable_rpc_throttle, enable_exceed_throttle_quota, enable_rpc_throttle, list_quota_snapshots, list_quota_table_sizes, list_quotas, list_snapshot_sizes, set_quota
Group name: security
Commands: grant, list_security_capabilities, revoke, user_permission
Group name: procedures
Commands: list_locks, list_procedures
Group name: visibility labels
Commands: add_labels, clear_auths, get_auths, list_labels, set_auths, set_visibility
Group name: rsgroup
Commands: add_rsgroup, alter_rsgroup_config, balance_rsgroup, get_namespace_rsgroup, get_rsgroup, get_server_rsgroup, get_table_rsgroup, list_rsgroups, move_namespaces_rsgroup, move_servers_namespaces_rsgroup, move_servers_rsgroup, move_servers_tables_rsgroup, move_tables_rsgroup, remove_rsgroup, remove_servers_rsgroup, rename_rsgroup, show_rsgroup_config
SHELL USAGE:
Quote all names in HBase Shell such as table and column names. Commas delimit
command parameters. Type <RETURN> after entering a command to run it.
Dictionaries of configuration used in the creation and alteration of tables are
Ruby Hashes. They look like this:
{'key1' => 'value1', 'key2' => 'value2', ...}
and are opened and closed with curley-braces. Key/values are delimited by the
'=>' character combination. Usually keys are predefined constants such as
NAME, VERSIONS, COMPRESSION, etc. Constants do not need to be quoted. Type
'Object.constants' to see a (messy) list of all constants in the environment.
If you are using binary keys or values and need to enter them in the shell, use
double-quote'd hexadecimal representation. For example:
hbase> get 't1', "key\x03\x3f\xcd"
hbase> get 't1', "key\003\023\011"
hbase> put 't1', "test\xef\xff", 'f1:', "\x01\x33\x40"
The HBase shell is the (J)Ruby IRB with the above HBase-specific commands added.
For more on the HBase Shell, see http://hbase.apache.org/book.html
2.2.2、namespace
1)创建命名空间
使用特定的 help 语法能够查看命令如何使用。
hbase:002:0> help 'create_namespace'
2)创建命名空间 bigdata
hbase:003:0> create_namespace 'bigdata'
3)查看所有的命名空间
hbase:004:0> list_namespace
NAMESPACE
bigdata
default
hbase
2.2.3、DDL
1)创建表
在 bigdata 命名空间中创建表格 student,两个列族。info 列族数据维护的版本数为 5 个,如果不写默认版本数为 1。
hbase:005:0> create 'bigdata:student', {NAME => 'info', VERSIONS => 5}, {NAME => 'msg'}
如果创建表格只有一个列族,没有列族属性,可以简写。
如果不写命名空间,使用默认的命名空间 default。
hbase:009:0> create 'student1','info'
2)查看表
查看表有两个命令:list 和 describe
list:查看所有的表名
hbase:013:0> list
describe:查看一个表的详情
hbase:014:0> describe 'student1'
hbase:013:0> describe 'bigdata:student'
Table bigdata:student is ENABLED
bigdata:student
COLUMN FAMILIES DESCRIPTION
{NAME => 'info', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '5', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VE
RSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'msg', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VER
SIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
3)修改表
表名创建时写的所有和列族相关的信息,都可以后续通过 alter 修改,包括增加删除列族。
(1)增加列族和修改信息都使用覆盖的方法
hbase:015:0> alter 'student1', {NAME => 'f1', VERSIONS => 3}
(2)删除信息使用特殊的语法
hbase:015:0> alter 'student1', NAME => 'f1', METHOD => 'delete'
hbase:016:0> alter 'student1', 'delete' => 'f1'
4)删除表
shell 中删除表格,需要先将表格状态设置为不可用。
hbase:017:0> disable 'student1'
hbase:018:0> drop 'student1'
2.2.4、DML
1)写入数据
在 HBase 中如果想要写入数据,只能添加结构中最底层的 cell。可以手动写入时间戳指定 cell 的版本,推荐不写默认使用当前的系统时间。
hbase:019:0> put 'bigdata:student','1001','info:name','zhangsan'
hbase:020:0> put 'bigdata:student','1001','info:name','lisi'
hbase:021:0> put 'bigdata:student','1001','info:age','18'
如果重复写入相同 rowKey,相同列的数据,会写入多个版本进行覆盖。
2)读取数据
读取数据的方法有两个:get 和 scan。
get 最大范围是一行数据,也可以进行列的过滤,读取数据的结果为多行 cell。
hbase:022:0> get 'bigdata:student','1001'
COLUMN CELL
info:age timestamp=2023-02-26T16:59:34.149, value=18
info:name timestamp=2023-02-26T16:59:27.238, value=lisi
1 row(s)
hbase:023:0> get 'bigdata:student','1001' , {COLUMN => 'info:name'}
COLUMN CELL
info:name timestamp=2023-02-26T16:59:27.238, value=lisi
1 row(s)
也可以修改读取 cell 的版本数,默认读取一个。最多能够读取当前列族设置的维护版本数。
hbase:024:0>get 'bigdata:student','1001' , {COLUMN => 'info:name', VERSIONS => 6}
COLUMN CELL
info:name timestamp=2023-02-26T16:59:27.238, value=lisi
info:name timestamp=2023-02-26T16:59:18.745, value=zhangsan
1 row(s)
scan 是扫描数据,能够读取多行数据,不建议扫描过多的数据,推荐使用 startRow 和stopRow 来控制读取的数据,默认范围左闭右开。
hbase:025:0> scan 'bigdata:student',{STARTROW => '1001',STOPROW => '1002'}
ROW COLUMN+CELL
1001 column=info:age, timestamp=2023-02-26T16:59:34.149, value=18
1001 column=info:name, timestamp=2023-02-26T16:59:27.238, value=lisi
1 row(s)
实际开发中使用 shell 的机会不多,所有丰富的使用方法到 API 中介绍。
3)删除数据
删除数据的方法有两个:delete 和 deleteall。
delete 表示删除一个版本的数据,即为 1 个 cell,不填写版本默认删除最新的一个版本。
hbase:026:0> delete 'bigdata:student','1001','info:name'
deleteall 表示删除所有版本的数据,即为当前行当前列的多个 cell。(执行命令会标记数据为要删除,不会直接将数据彻底删除,删除数据只在特定时期清理磁盘时进行)
hbase:027:0> deleteall 'bigdata:student','1001','info:name'
三、HBase API
详见代码。
评论