
一、简介
HBase scan 命令用来查询全表数据,使用时只需指定表名即可。
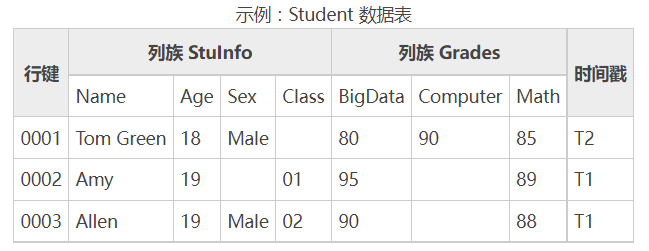
例如对于上面的 Student 表,使用下面的写法即可查询数据:
scan 'Student'
同样地,还可以指定列族和列的名称,或指定输出行数,甚至指定输出行键范围。
scan 指定条件输出时,需要使用大括号将参数包含起来。
注意指定列族和列名称使用 COLUMN 限定符;指定输出行键范围使用 STARTROW 和 ENDROW 限定符,此时输出行不包括 ENDROW 行。例如,上图中 ENDROW=>0003,只会输出行键为 0002 的记录,不会输出 0003 记录。
上述限定条件也可以联合使用,中间用逗号隔开即可。
在 HBase 中,具有相同行键的单元格,无论其属于哪个列族,都可以将整体看作一个逻辑行, 使用 count 命令可以计算表的逻辑行数。
在关系型数据库中,有多少条记录就有多少行,表中的行数很容易统计。而在 HBase 里,计算逻辑行需要扫描全表的内容,重复的行键是不纳入计数的,且标记为 tombstone 的删除数据也不纳入计数。
执行 count 命令其实是一个开销较大的进程,特别是应用在大数据场景时,可能需要持续很长时间,因此,用户一般会结合 Hadoop 的 MapReduce 架构来进行分布式的扫描计数。
二、详解
hbase 中 scan 命令是经常使用到的,而 filter 的作用尤其强大。这里简要的介绍下 scan 下 filter 命令的使用。
2.1、插入 scan 命令需要的数据
这里模拟了部分微博评论的数据,然后使用代码插入数据到 hbase。
public class Comment {
//1-->普通文章,2--->热点文章
Integer articleType;
//文章id
String articleId;
String userId;
long timestamp;
//comment content,暂时只考虑文本
String commentContent;
}
hbase 的表名称为 zy_comment,列簇info下有 articleType 以及 commentInfo 两个列。commentInfo 的 value 为上面Comment 类的 json 字符串,插入的数据如下所示。

2.2、HBase数据顺序
HBase是三维有序存储的,是指 rowkey(行键),column key(column family和qualifier)和 TimeStamp(时间戳)这个三个维度是依照 ASCII 码表排序的。(比如A排在a前面)。
1、先 rowkey 升序排序,
2、rowkey 相同则 column key 升序排序
3、rowkey、column key 相同则 timestamp 降序排序
2.3、支持的Filter
scan 命令经常会大量使用 Filter,hbase shell 提供的 filter 都可以在 hbase client 包中找到对应的类,它们都是 Filter 的子类,很多命令都是通过 filter 来进行实现的。
使用 show_filters 命令查看 shell 中定义了哪些 filter 常量,如果想要使用 shell 中未定义的常量,在使用的时候必须手动 import filter 的全路径。

2.4、scan 的用法
使用 help 'scan' 命令可以查看 scan 的语法以及用法,关于 scan 命令中 filter 的使用规则如下:
scan 'tableName',{FILTER=>"FilterName(param1,param2,...,paramN)"}
{}中的语法是 ruby 的 map 的语法,FILTER 必须大写,filter 的参数是根据构造方法来的,也就是相当于 java 中的 new Filter(‘param1’,‘param2’) 等,这里只是省略了 new 参数而已。
当然同样可以使用 ruby 中 new 对象的方式,只是那样就必须使用全限定名称。后面会举一个全限定名称的例子。
在使用Filter的过程中部分filter会用到比较器 CompareOperator.java 以及运算比较符 ByteArrayComparable.java。
@Public
public enum CompareOperator {
LESS, // <
LESS_OR_EQUAL, // <=
EQUAL, // =
NOT_EQUAL, // <>
GREATER_OR_EQUAL, // >=
GREATER, // >
NO_OP; // 没有任何操作
private CompareOperator() {
}
}
比较器主要有以下几种:
BinaryComparator
按字节索引顺序比较指定字节数组,采用 Bytes.compareTo(byte[]),比如:binary:\x00\x00\x02BinaryPrefixComparator
跟前面相同,只是比较左端的数据是否相同,比如:binaryprefix:\x00\x00NullComparator
判断给定的是否为空,不常用BitComparator
按位比较 a BitwiseOp class 做异或,与,并操作,不常用RegexStringComparator
提供一个正则的比较器,仅支持 EQUAL 和非EQUAL,比如:regexstring:ab*addSubstringComparator
判断提供的子串是否出现在table的value中。比如:substring:great
三、scan例子
查询方式通过 rowKey 来进行查询是最快的,所以 rowkey 的设计一定要合理,如果不合理会很影响查询速率。但是有时候确实没有办法完全通过 rowkey 来查询,所以就要借助 scan。
scan 命令支持的修饰词除了列(COLUMNS)修饰词外,HBase还支持Limit(限制查询结果行数),STARTROW(ROWKEY起始行。会先根据这个key定位到region,再向后扫描)、STOPROW(结束行)、TIMERANGE(限定时间戳范围)、VERSIONS(版本数)、和FILTER(按条件过滤行)等。
1、查询 user 是zhangsan的用户的评论数据,最多只返回10条
scan 'zy_comment',{LIMIT=>10,FILTER=>"PrefixFilter('zhangsan')"}

2、通过startrow,stoprow来进行查询(这种也比较快,实际操作中如果不能通过rowkey)
scan 'zy_comment',{STARTROW=>'b',STOPROW='e',LIMIT=>10}

3、查询评论内容为666的评论有哪些
scan 'zy_comment',{LIMIT=>10,FILTER=>"ValueFilter(=,'substring:666')"}

4、查询热点文章的数据有哪些。这里binary中的数据一定要是二进制字符串而不是具体的值。
scan 'zy_comment',{LIMIT=>10,FILTER="SingleColumnValueFilter('info','articleType',=,'binary: \x00\x00\x00\x00\x00\x00\x00\x02')"}
5、查看评论包含great的热点文章评论有哪些
scan 'zy_comment',{LIMIT=>3,FILTER=>"(SingleColumnValueFilter('info','articleType',=,'binary:\x00\x00\x00\x00\x00\x00\x00\x02')) AND (ColumnPrefixFilter('commentInfo') AND ValueFilter(=,'substring:great'))"}
6、查询评论的前两条
scan 'zy_comment',{FILTER=>"PageFilter(2)"}和LIMIT有异曲同工之妙
7、查询rowkey中包含特定前缀的数据
scan 'zy_comment',{FILTER=>"RowFilter(=,'substring:zhangsan')"}
8、使用全限定名称查询articleId是123456的数据
import org.apache.hadoop.hbase.filter.SingleColumnValueFilter
import org.apache.hadoop.hbase.filter.CompareFilter
import org.apache.hadoop.hbase.filter.SubstringComparator
scan 'zy_comment', {COLUMNS=>['info:commentInfo'], FILTER =>
SingleColumnValueFilter.new(Bytes.toBytes('info'), Bytes.toBytes('commentInfo'),
CompareFilter::CompareOp.valueOf('EQUAL'), SubstringComparator.new('123456'))}
注意:
- 如果 scan 中指定了 COLUMNS,则FILTER中所使用的列需要包含在所指定的 COLUMNS 中,否则,filter 不起作用。
- HBase 中主要的操作对象是一个个的 cell,每个 cell 都可以有多个版本。如果使用过滤器 ValueFilter,就会只有那些符合条件的 cell 被查出来。跟关系数据库的查询不同,关系数据库查出来的结果中各行都有相同的列。而 HBase,查出来的结果中,不同的行会有不同的列。
- filter 不会降低服务方的 IO,它会把符合条件的子集传给客户端。即,它是在对查出的结果进行过滤,而不是象原来 sql 中的 where 子句。所以,如果要查出的结果中不包含 filter 需要的列,则 filter 就不能发挥作用。
评论