
一、概述
1.1、循环依赖
一个或多个对象之间存在直接或间接的依赖关系,这种依赖关系构成一个环形调用,有下面 3 种方式。
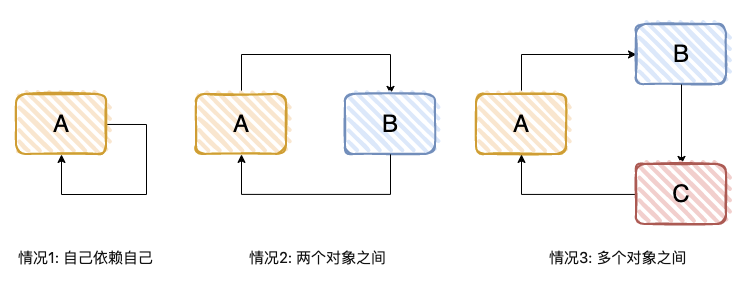
一个 demo:
@Service
public class Louzai1 {
@Autowired
private Louzai2 louzai2;
public void test1() {
}
}
@Service
public class Louzai2 {
@Autowired
private Louzai1 louzai1;
public void test2() {
}
}
这是一个经典的循环依赖,它能正常运行。
1.2、三级缓存
解读源码流程之前,spring 内部的三级缓存逻辑必须了解。
- 第一级缓存:singletonObjects,用于保存实例化、注入、初始化完成的 bean 实例;
- 第二级缓存:earlySingletonObjects,用于保存实例化完成的 bean 实例;
- 第三级缓存:singletonFactories,用于保存 bean 创建工厂,以便后面有机会创建代理对象。
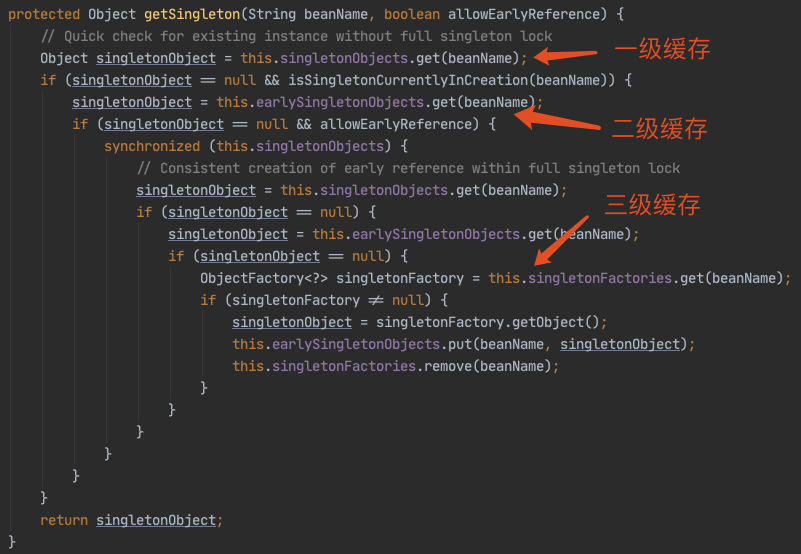
执行逻辑: - 先从“第一级缓存”找对象,有就返回,没有就找“二级缓存”;
- 找“二级缓存”,有就返回,没有就找“三级缓存”;
- 找“三级缓存”,找到了,就获取对象,放到“二级缓存”,从“三级缓存”移除。
1.3、原理执行流程
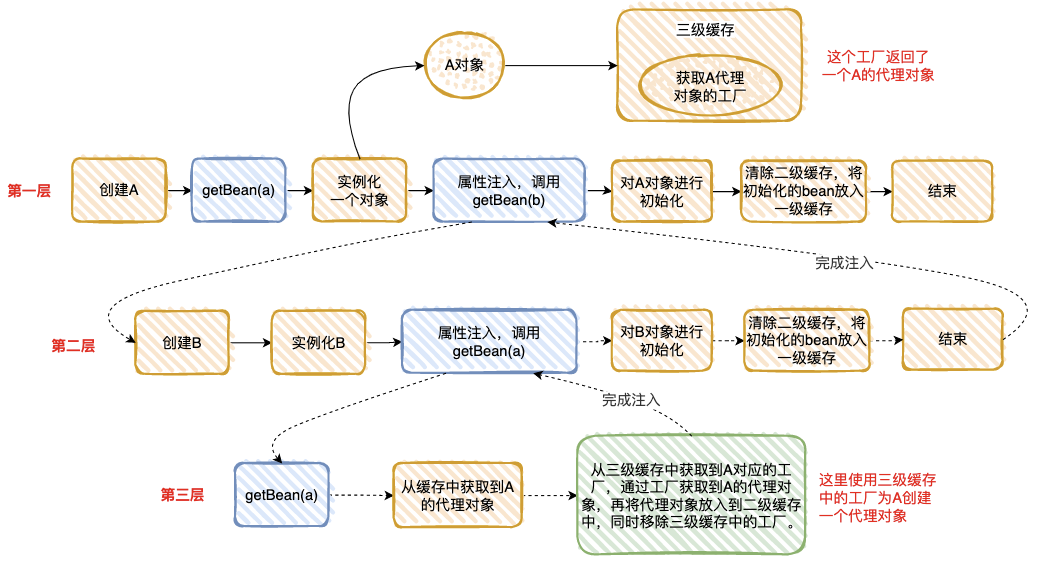
整个执行逻辑如下:
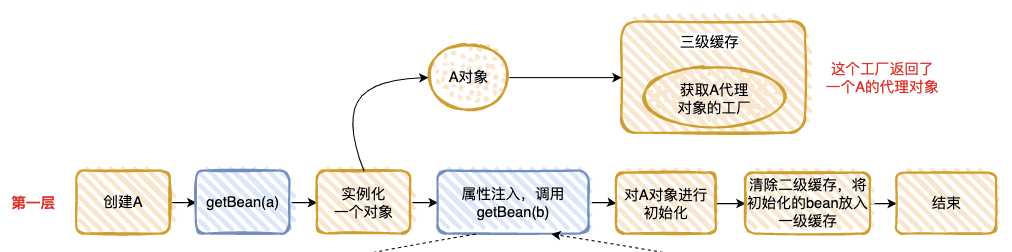
- 1、在第一层中,先去获取 A 的 Bean,发现没有就准备去创建一个,然后将 A 的代理工厂放入“三级缓存”(这个 A 其实是一个半成品,还没有对里面的属性进行注入),但是 A 依赖 B 的创建,就必须先去创建 B;
- 2、在第二层中,准备创建 B,发现 B 又依赖 A,需要先去创建 A;
- 3、在第三层中,去创建 A,因为第一层已经创建了 A 的代理工厂,直接从“三级缓存”中拿到 A 的代理工厂,获取 A 的代理对象,放入“二级缓存”,并清除“三级缓存”;
- 4、回到第二层,现在有了 A 的代理对象,对 A 的依赖完美解决(这里的 A 仍然是个半成品),B 初始化成功;
- 5、回到第一层,现在 B 初始化成功,完成 A 对象的属性注入,然后再填充 A 的其它属性,以及 A 的其它步骤(包括 AOP),完成对 A 完整的初始化功能(这里的 A 才是完整的 Bean)。
- 6、将 A 放入“一级缓存”。
二、源码
2.1、代码入口
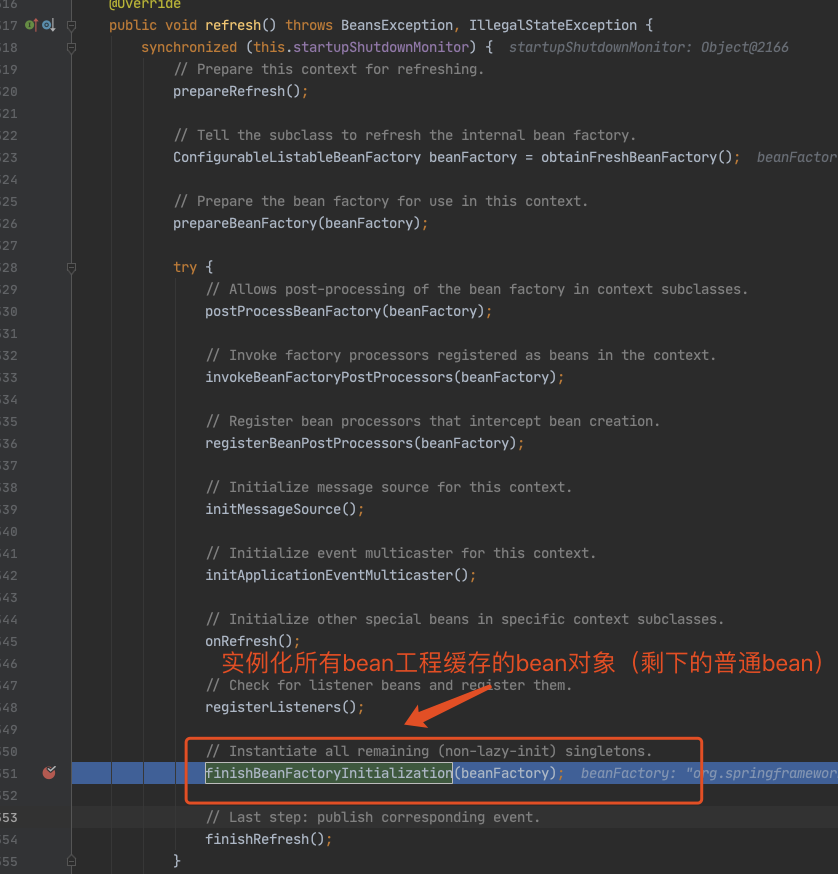
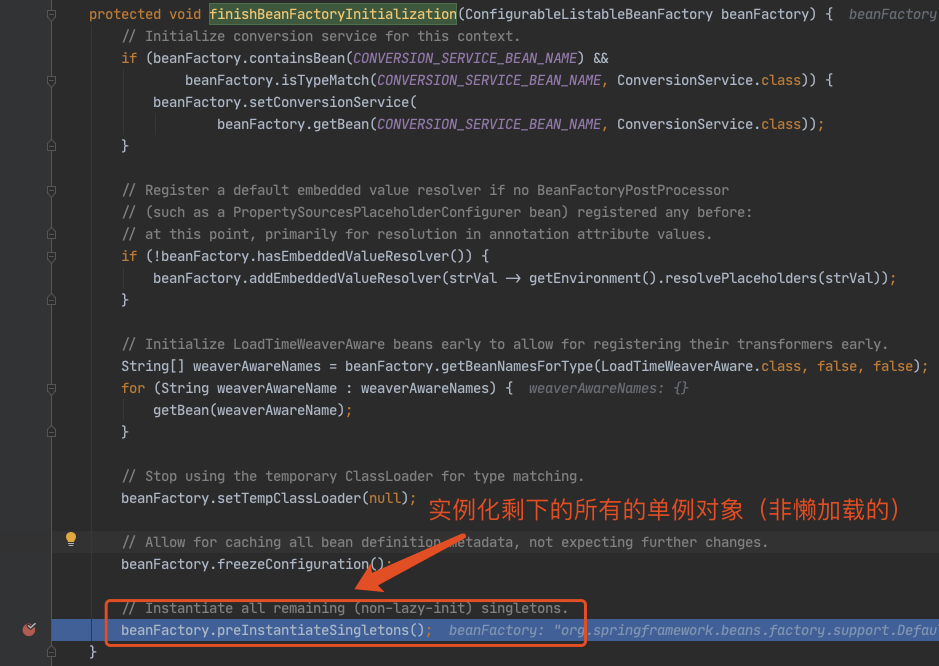
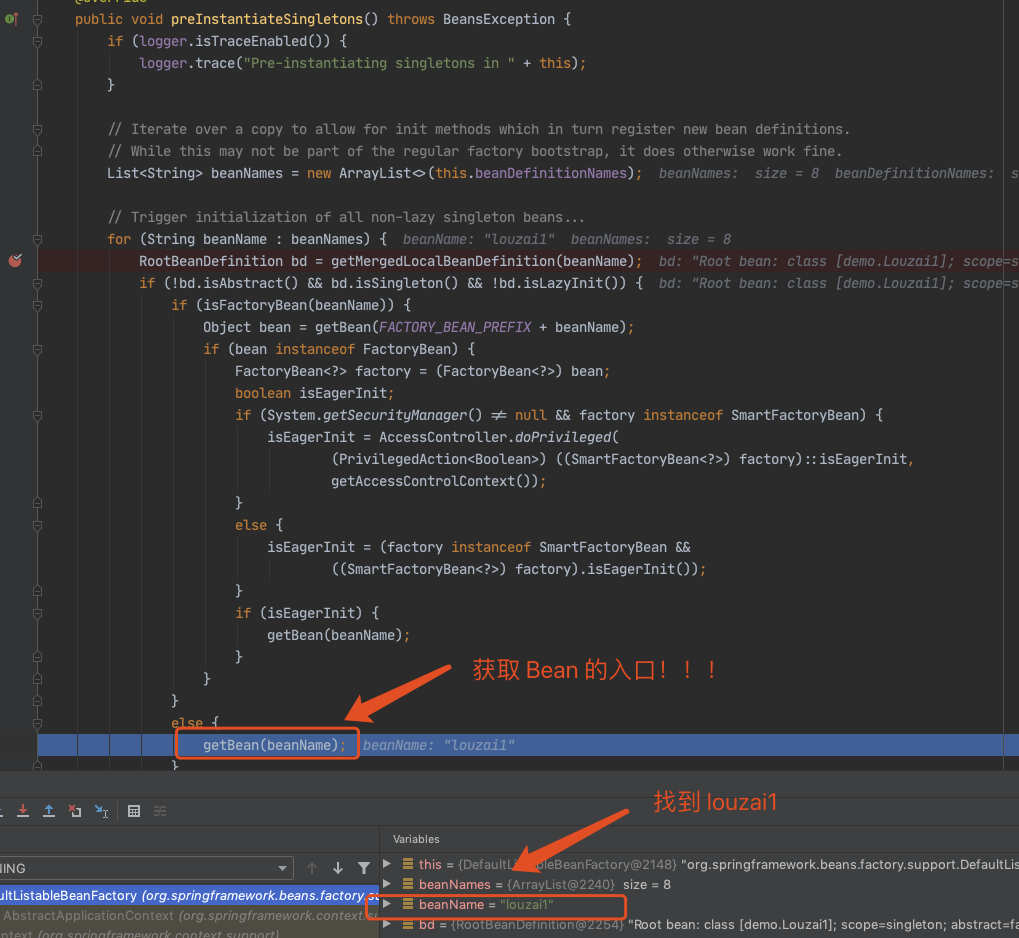
2.2、第一层
进入 doGetBean(),从 getSingleton() 没有找到对象,进入创建 Bean 的逻辑。
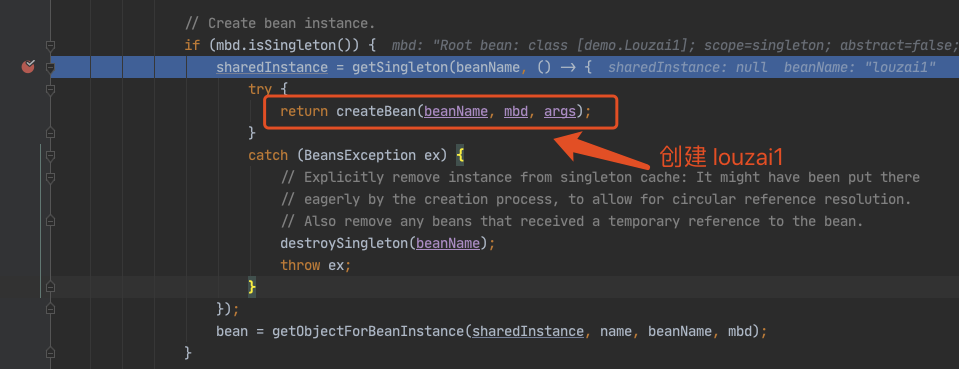
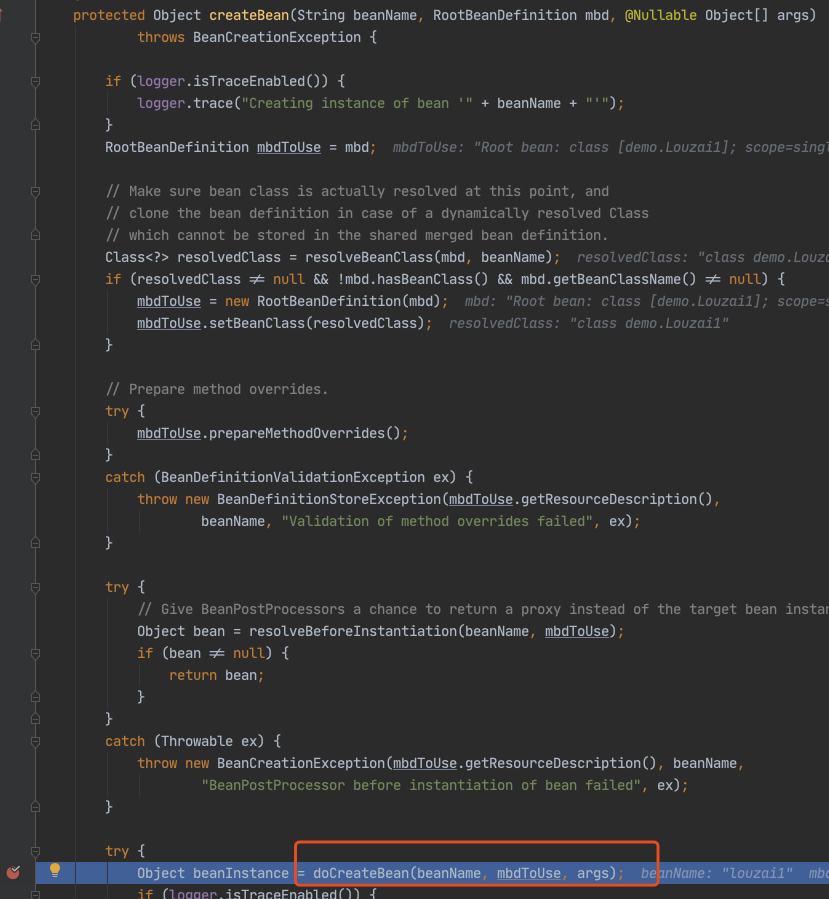
进入 doCreateBean() 后,调用 addSingletonFactory()。
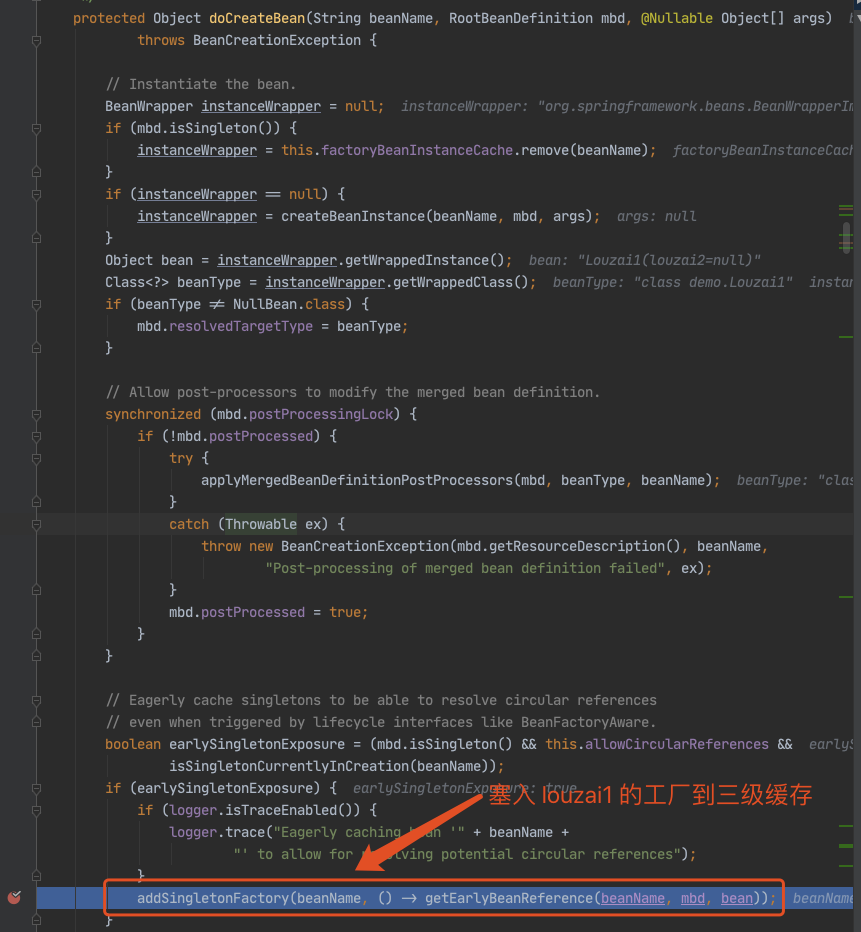
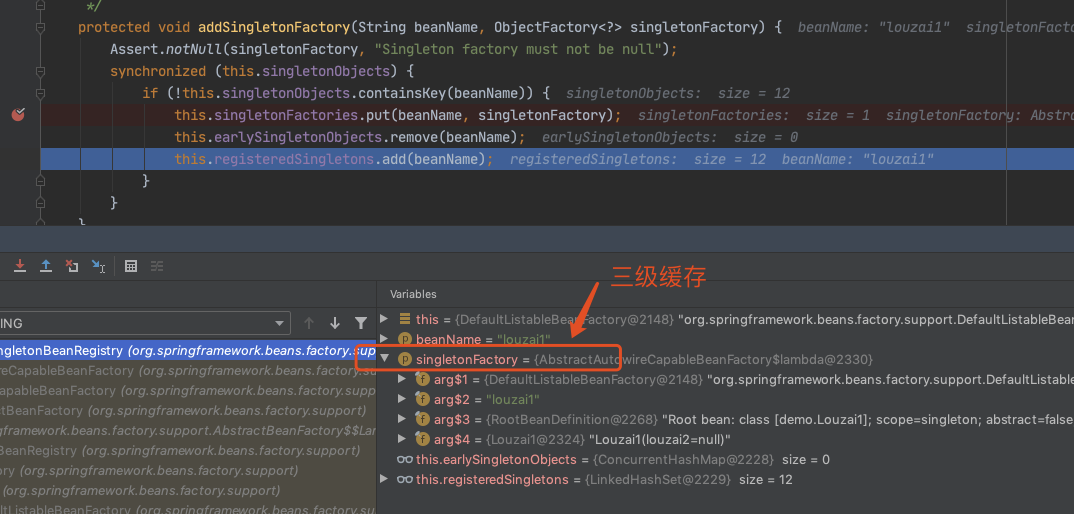
往三级缓存 singletonFactories 塞入 louzai1 的工厂对象。
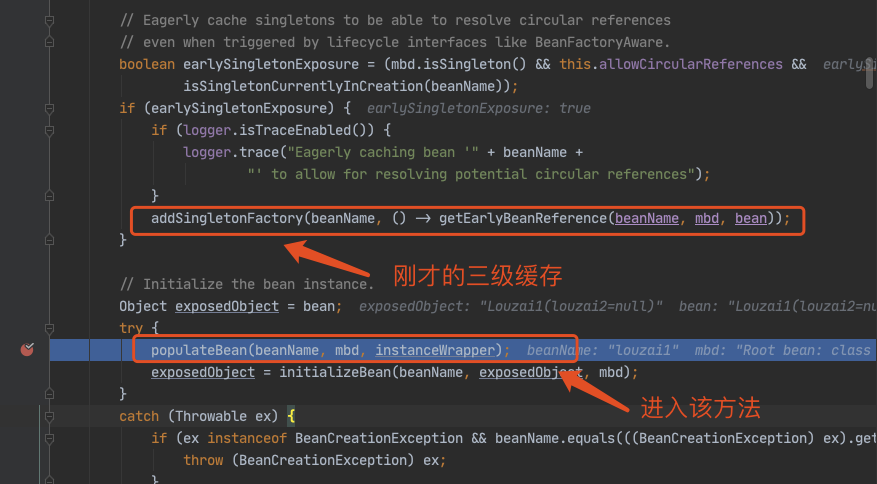
进入到 populateBean(),执行 postProcessProperties(),这里是一个策略模式,找到下图的策略对象。
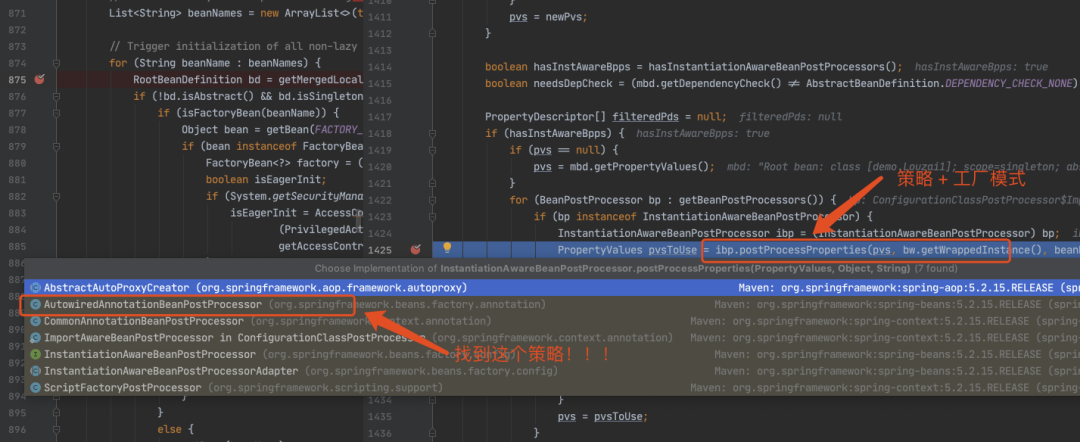
正式进入该策略对应的方法。
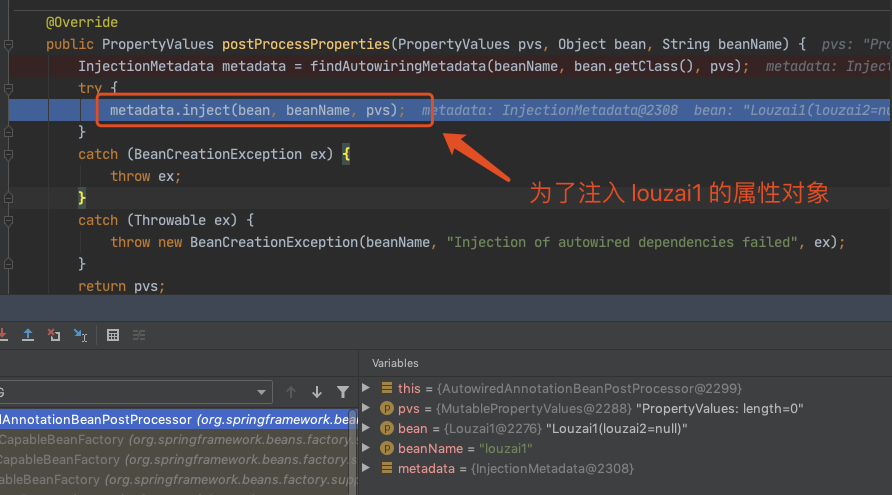
下面都是为了获取 louzai1 的成员对象,然后进行注入。
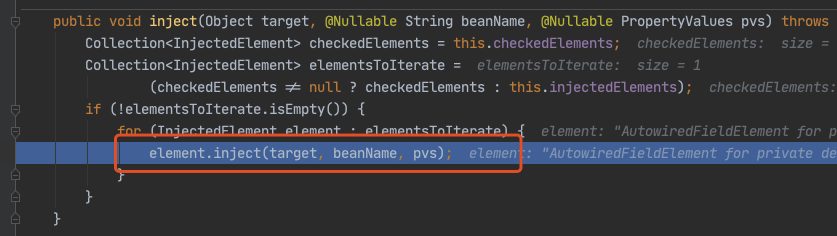
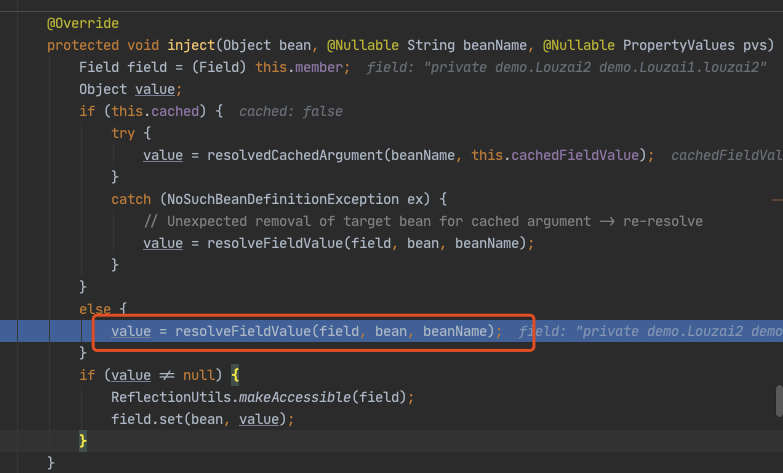
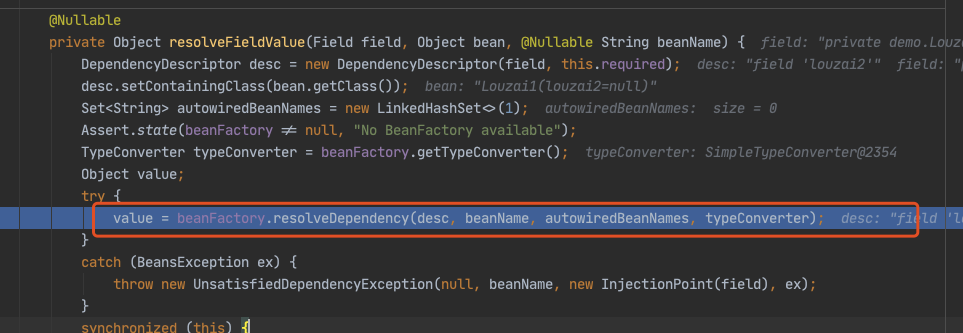
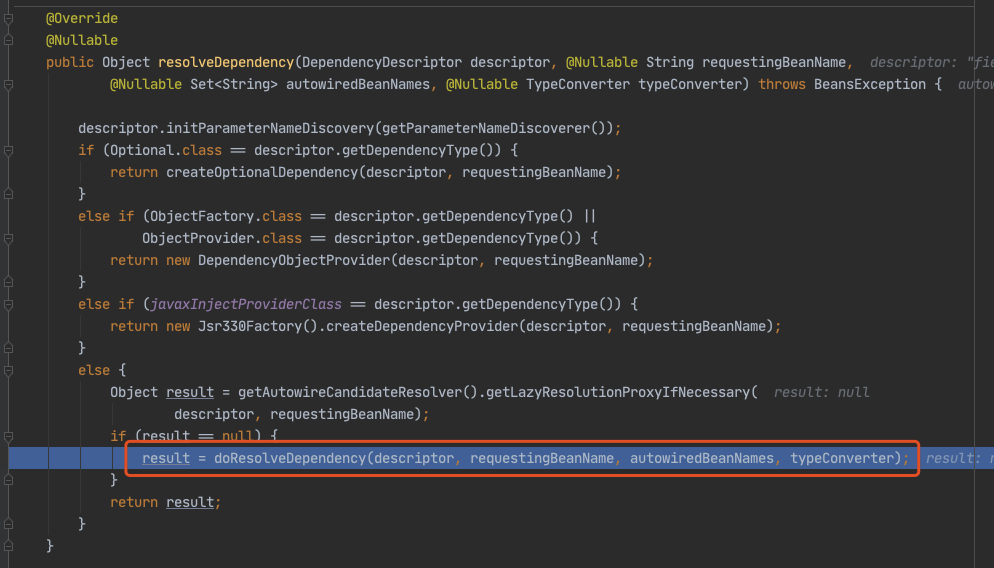
进入 doResolveDependency(),找到 louzai1 依赖的对象名 louzai2。
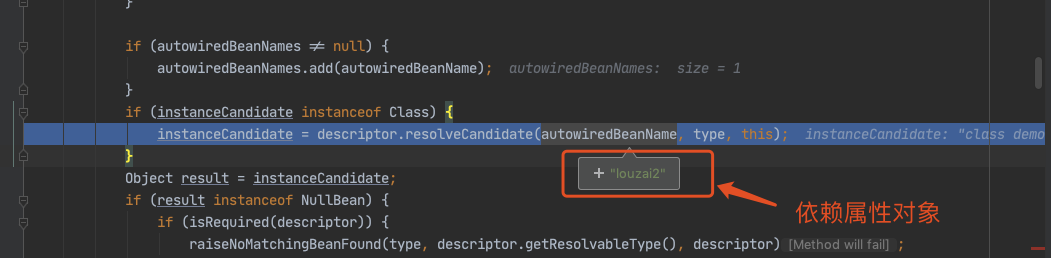
需要获取 louzai2 的 bean,是 AbstractBeanFactory 的方法。
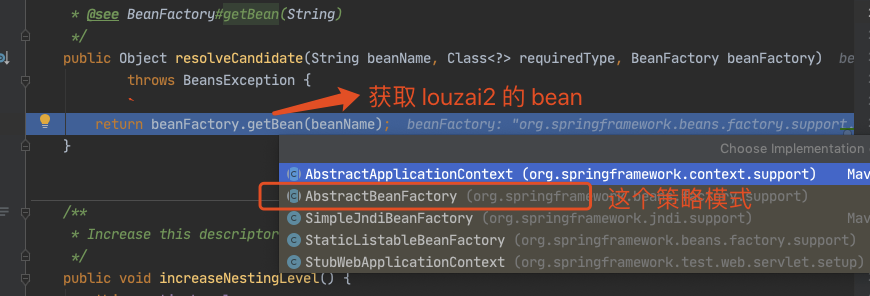
正式获取 louzai2 的 bean。

到这里,第一层套娃基本结束,因为 louzai1 依赖 louzai2,下面我们进入第二层套娃。
2.3、第二层

2.4、第三层

三、解析
“一级缓存”的作用,变量命名为 singletonObjects,结构是 Map<String, Object>,它就是一个单例池,将初始化好的对象放到里面,给其它线程使用,如果没有第一级缓存,程序不能保证 Spring 的单例属性。
“三级缓存”的作用,变量命名为 singletonFactories,结构是 Map<String, ObjectFactory<?>>,Map 的 Value 是一个对象的代理工厂,所以“三级缓存”的作用,其实就是用来存放对象的代理工厂。
那这个对象的代理工厂有什么作用呢,我先给出答案,它的主要作用是存放半成品的单例 Bean,目的是为了“打破循环”。
为什么“三级缓存”不直接存半成品的 A,而是要存一个代理工厂呢 ?答案是因为 AOP。
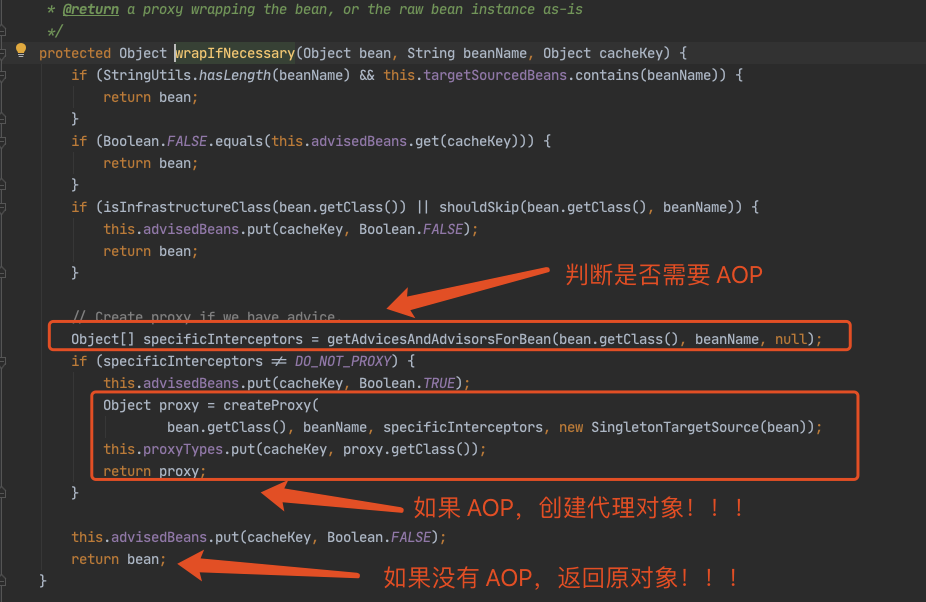
那“二级缓存”的作用就清楚了,就是用来存放对象工厂生成的对象,这个对象可能是原对象,也可能是个代理对象。
3.2、能去掉第 2 级缓存么
@Service
public class A {
@Autowired
private B b;
@Autowired
private C c;
public void test1() {
}
}
@Service
public class B {
@Autowired
private A a;
public void test2() {
}
}
@Service
public class C {
@Autowired
private A a;
public void test3() {
}
}
根据上面的套娃逻辑,A 需要找 B 和 C,但是 B 需要找 A,C 也需要找 A。
假如 A 需要进行 AOP,因为代理对象每次都是生成不同的对象,如果干掉第二级缓存,只有第一、三级缓存:
- B 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A1。
- C 找到 A 时,直接通过三级缓存的工厂的代理对象,生成对象 A2。
通过 A 的工厂的代理对象,生成了两个不同的对象 A1 和 A2,所以为了避免这种问题的出现,我们搞个二级缓存,把 A1 存下来,下次再获取时,直接从二级缓存获取,无需再生成新的代理对象。
所以“二级缓存”的目的是为了避免因为 AOP 创建多个对象,其中存储的是半成品的 AOP 的单例 bean。
如果没有 AOP 的话,其实只要 1、3 级缓存,就可以满足要求。
四、总结
三级缓存的作用:
- 一级缓存:为“Spring 的单例属性”而生,就是个单例池,用来存放已经初始化完成的单例 Bean;
- 二级缓存:为“解决 AOP”而生,存放的是半成品的 AOP 的单例 Bean;
- 三级缓存:为“打破循环”而生,存放的是生成半成品单例 Bean 的工厂方法。
评论