
一、Logstash 是一个数据流引擎
- 它是用于数据物流的开源流式
ETL(Extract-Transform-Load)引擎。 - 在几分钟内建立数据流管道。
- 具有水平可扩展及韧性且具有自适应缓冲。
- 不可知的数据源。
- 具有 200 多个集成和处理器的插件生态系统。
- 使用
Elastic Stack监视和管理部署。
二、Logstash 几乎可以摄入各种类别的数据
它可以摄入日志,文件,指标或者网路真实数据。经过 Logstash 的处理,变为可以使用的 Web Apps 可以消耗的数据,也可以存储于数据中心,或变为其它的流式数据。
三、最为流行的数据源

- Logstash 可以很方便地和 Beats一起合作,这也是被推荐的方法。
- Logstash 也可以和那些著名的云厂商的服务一起合作处理它们的数据。
- 它也可以和最为同样的信息消息队列,比如 redis 或 kafka 一起协作。
- Logstash 也可以使用 JDBC 来访问 RDMS 数据。
- 它也可以和 IoT 设备一起处理它们的数据。
- Logstash 不仅仅可以把数据传送到 Elasticsearch,而且它还可以把数据发送至很多其它的目的地,并作为它们的输入源做进一步的处理。
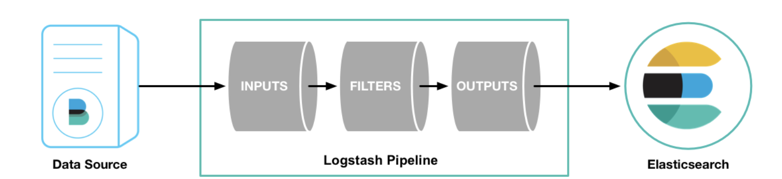
四、Logstash 在 Elastic Stack 中是如何融入的
到目前为止,有如下的3中方式能够把我们所感兴趣的数据导入到 Elasticsearch 中:
正如上面所显示的那样,我们可以通过:
Beats:我们可以通过 Beats 把数据导入到 Elasticsearch中Logstash:我们可以 Logstash 把数据导入。Logstash 的数据来源也可以是 Beats。REST API:我们可以通过 Elastic 所提供的丰富的 API 来把数据导入到 Elasticsearch 中。我们可以通过 Java, Python, Go, Nodejs 等各种 Elasticsearch API 来完成我们的数据导入。
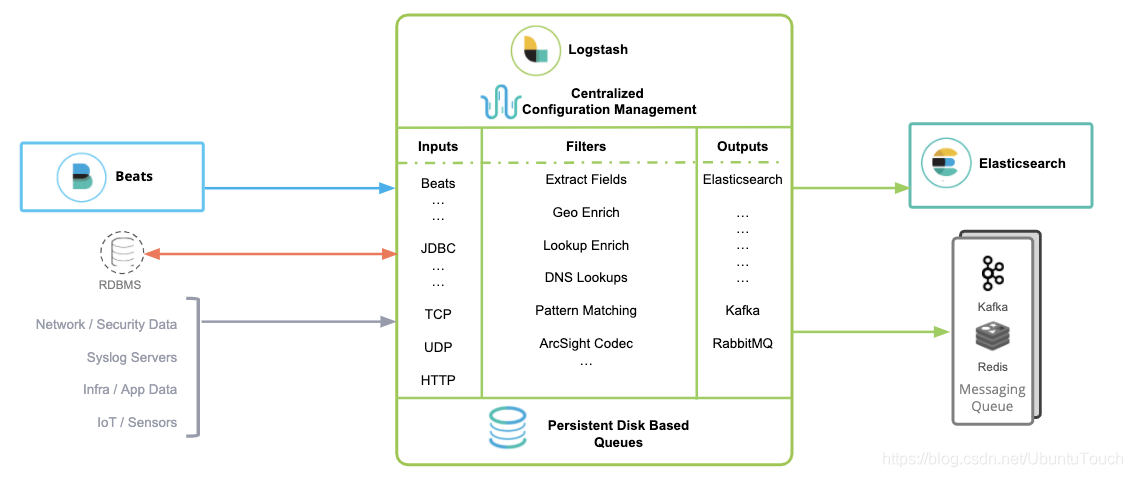
那么针对 Beats 来说,Logstash 是如何和其它的 Elastic Stack 一起工作的呢?可以看如下的框图:
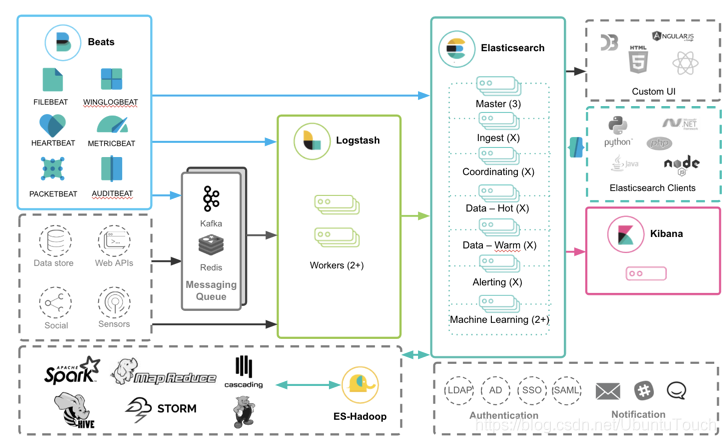
从上面我们可以看出来,Beats 的数据可以有如下的三种方式导入到 Elasticsearch 中:
Beats ==> ElasticsearchBeats ==> Logstash ==> ElasticsearchBeats ==> Kafka ==> Logstash ==> Elasticsearch
正如上面所显示的那样:
- 可以直接把 Beats 的数据传入到 Elasticsearch 中,甚至在现在的很多情况中,这也是一种比较受欢迎的一种方案。它甚至可以结合 Elasticsearch 所提供的 pipeline 一起完成更为强大的组合。
- 可以利用 Logstash 所提供的强大的 filter 组合对数据流进行处理:解析,丰富,转换,删除,添加等等。
- 针对有些情况,如果数据流具有不确定性,比如可能在某个时刻生产大量的数据,从而导致 Logstash 不能及时处理,可以通过 Kafka 来做一个缓存。
五、Logstash 是如何工作的
Logstash 旨在作为独立组件运行,以将数据加载到 Elasticsearch(以及其他目标系统)。 Logstash 是一个基于插件的组件,这意味着它可以高度扩展它支持的源/目标系统类型以及它可以进行的转换。Logstash 不是集群组件,无法感知其他 Logstash 实例。通过跨实例负载平衡数据,可以使用多个 Logstash 实例来满足高可用性和扩展需求。
六、与 Logstash 相关的以下概念值得理解
- Logstash 实例是一个正在运行的 Logstash 进程。建议在 Elasticsearch 的单独主机上运行 Logstash,以确保两个组件有足够的计算资源可用。
管道(pipeline)是配置为处理给定工作负载的插件集合。一个 Logstash 实例可以运行多个管道(彼此独立) 。
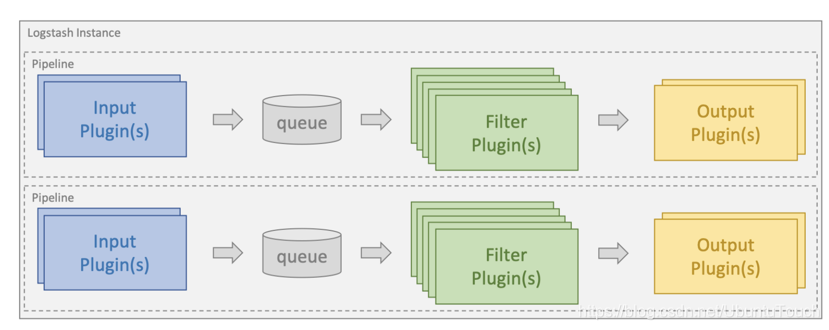
输入插件(input plugins)用于从给定的源系统中提取或接收数据。 Logstash 参考指南中提供了支持的输入插件列表:https://www.elastic.co/guide/en/logstash/current/input-plugins.html过滤器插件(filter plugin)用于对传入事件应用转换和丰富。 Logstash 参考指南中提供了支持的过滤器插件列表:Filter plugins | Logstash Reference [8.3] | Elastic输出插件(output plugin)用于将数据加载或发送到给定的目标系统。 Logstash 参考指南中提供了支持的输出插件列表:https://www.elastic.co/guide/en/logstash/current/output-plugins.html
Logstash 通过运行一个或多个 Logstash 管道作为 Logstash 实例的一部分来处理 ETL 工作负载。
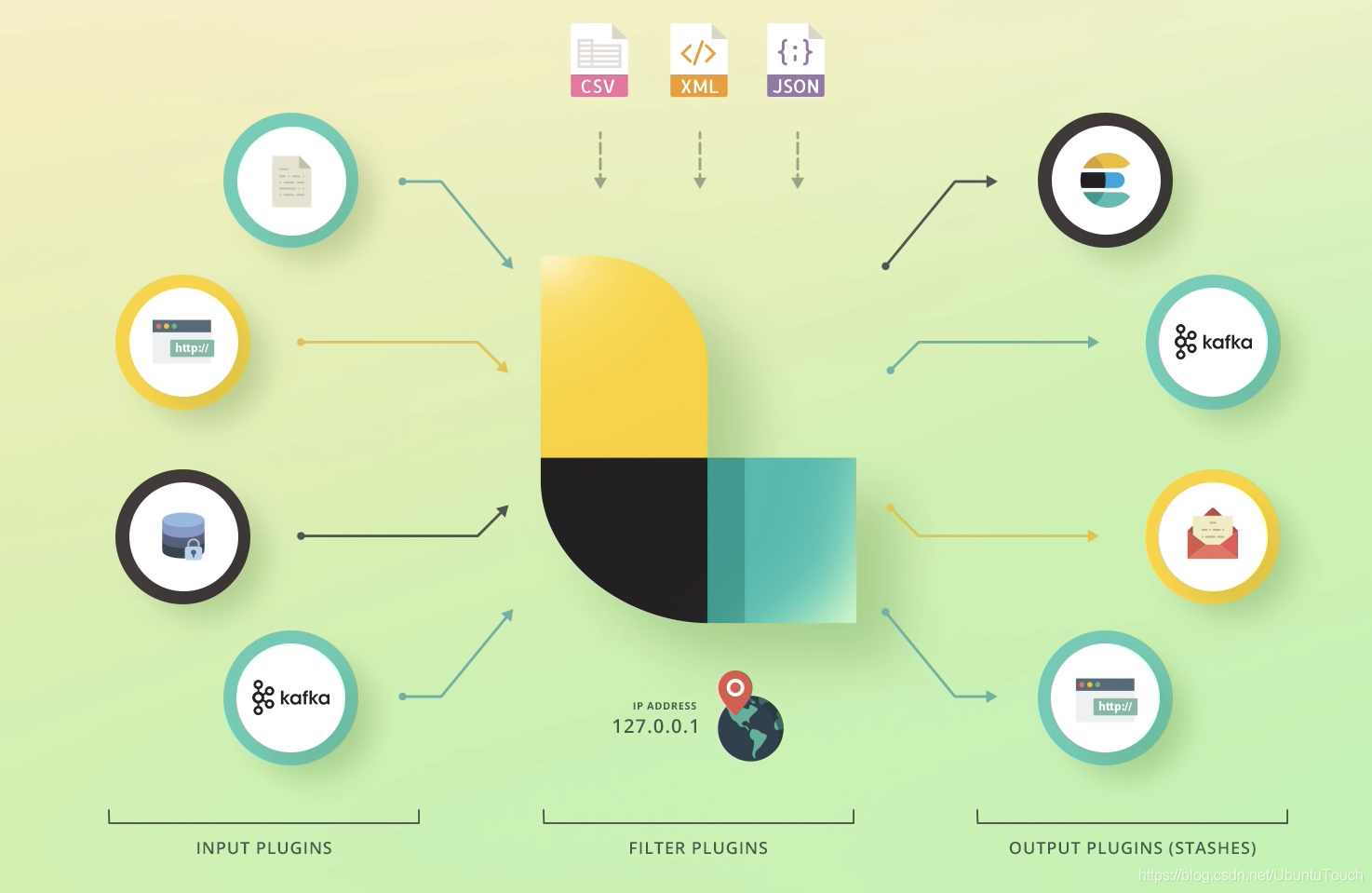
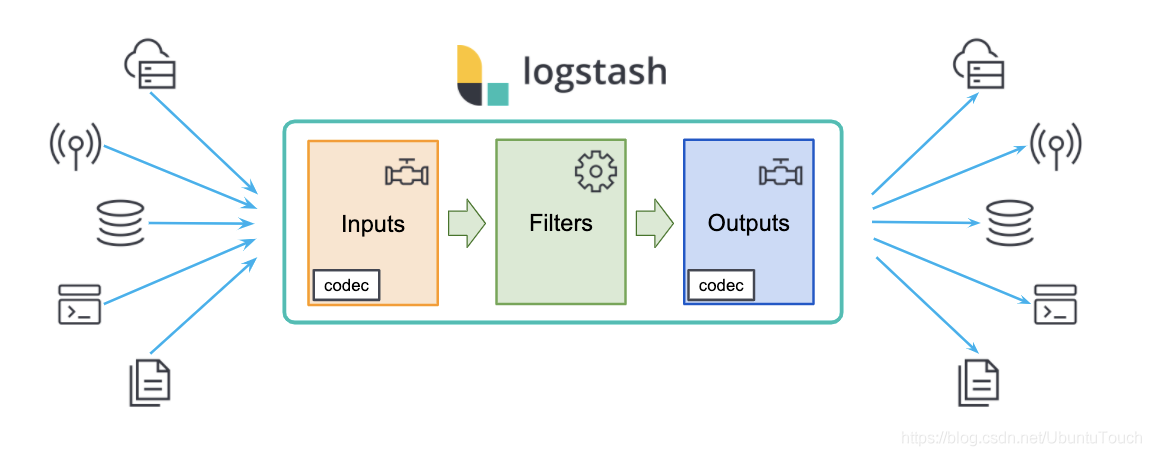
Logstash 包含3个主要部分: 输入(inputs),过滤器(filters)和输出(outputs)。 你必须定义这些过程的配置才能使用 Logstash,尽管不是每一个都必须的。在有些情况下,我们可以甚至没有过滤器。在过滤器的部分,它可以对数据源的数据进行分析,丰富,处理等等。
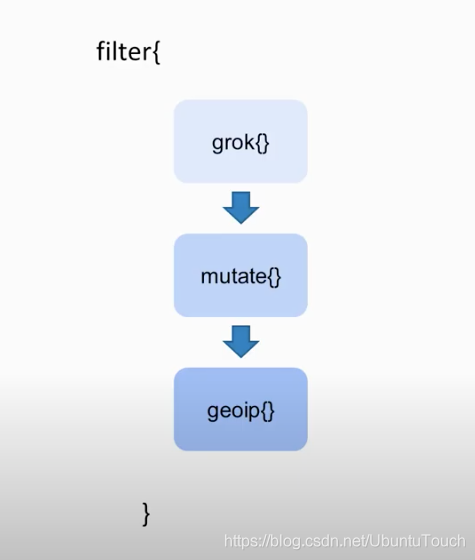
在输出的部分,我们甚至可以有多于一个以上的输出。
在下面的图中,我们可以看到一些常见的 inputs, filters 及 outputs:
了解更多关于 Logstash 的这些 Inputs, Filters 及 Outputs,那么请访问 Elastic 的官方网址Logstash Reference [7.14] | Elastic
七、简介
Logstash 是一个功能强大的工具,可与各种部署集成。它提供了大量插件,可帮助你解析,丰富,转换和缓冲来自各种来源的数据。 如果你的数据需要 Beats中 没有的其他处理,则需要将 Logstash 添加到部署中。
Logstash 是 Elastic 栈非常重要的一部分,但是它不仅仅为 Elasticsearch 所使用。它可以接受广泛的各种数据源。Logstash 可以帮利用它自己的 Filter 帮我们对数据进行解析,丰富,转换等。
最后,它可以把自己的数据输出到各种需要的数据储存地,这其中包括 Elasticsearch。
八、安装 Logstash
注意:在这里,以安装版本7.3为例。如果你想安装其它的版本,请把下面的数字改为相应的版本信息进行下载及安装。必须安装和 Elasticsearch 版本一致的 Logstash。除了下面的命令之外,也可以在地址直接下载安装。在下面使用 7.3.0 版本为例来进行安装。如果想安装其它的版本,直接在命令行中替换命令行中的 7.3.0 为你想要的版本号码。
deb:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.deb
sudo dpkg -i logstash-7.3.0.deb
rpm:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.rpm
sudo rpm -i logstash-7.3.0.rpm
mac and linux:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-7.3.0.tar.gz
tar -xzvf logstash-7.3.0.tar.gz
Logstash 管道有两个必需元素,输入和输出,以及一个可选元素 filter。 输入插件使用来自源的数据,过滤器插件在指定时修改数据,输出插件将数据写入目标。
要测试 Logstash 安装,请运行最基本的 Logstash 管道。 例如:
cd logstash-7.3.0
bin/logstash -e 'input { stdin { } } output { stdout {} }'
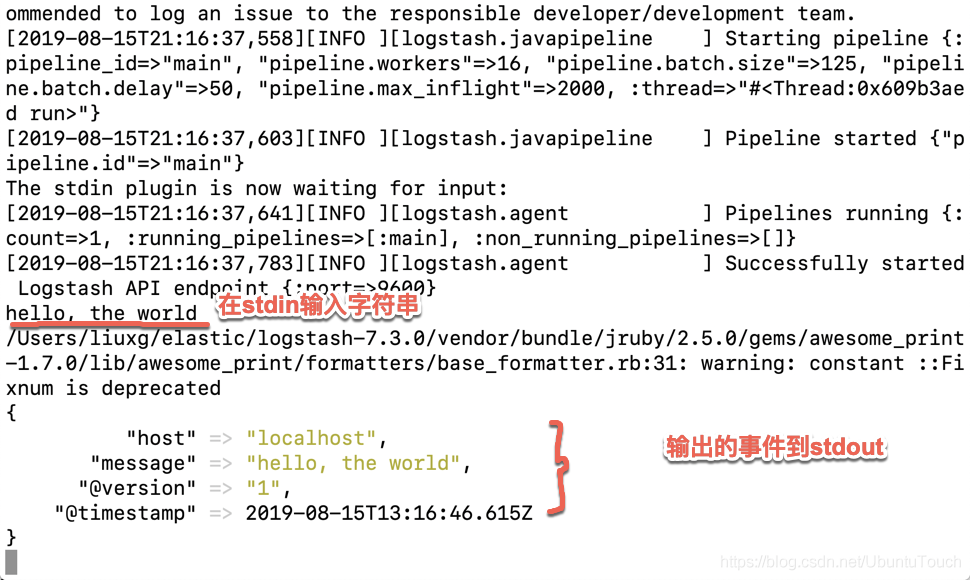
等 Logstash 完成启动后,我们在 stdin 里输入一下文字,我们可以看到如下的输出:
也可以创建一个自己的 logstash.conf 文件,并存于你的文件系统的一个目录下。这个 logstash.conf 的文件内容如下:
logstash.conf
input {
stdin{ }
}
output {
stdout {
codec => rubydebug
}
}
可以使用如下的命令来运行 logstash:
./bin/logstash -f path_to_logstash_conf_file
通过这样的 -f 选项,可以启动任何一个我们喜欢路径的 longstash 配置文件。这个文件可能并不存在于当前的 Logstash 的安装目录中。以后 Logstash 整个安装目录被删除,那么配置文件也将在这里。
也可以通过如下的配置文件,把我们在 terminal 上输入的信息输出到一个文件中:
input {
stdin{}
}
output {
file {
path => "path_to_log_file/output.log"
}
}
比如,创建一个如下的 heartbeat.conf 文件:
heartbeat.conf
input {
heartbeat {
interval => 10
type => "heartbeat"
}
}
output {
stdout {
codec => rubydebug
}
}
可以使用如下的命令来运行:
./bin/logstash -f heartbeat.conf
可以看到如下的输出:
{
"@version" => "1",
"@timestamp" => 2020-05-04T23:10:15.893Z,
"type" => "heartbeat",
"host" => "liuxg",
"message" => "ok"
}
{
"@version" => "1",
"@timestamp" => 2020-05-04T23:10:25.885Z,
"type" => "heartbeat",
"host" => "liuxg",
"message" => "ok"
}
存在的配置文件:
logstash.yml配置Logstash的yml。pipelines.yml包含在单个Logstash实例中运行多个管道的框架和说明。jvm.options配置Logstash的JVM,使用此文件设置总堆空间的初始值和最大值,此文件中的所有其他设置都被视为专家设置。log4j2.properties包含log4j 2库的默认设置。
九、logstash.yml 配置详解
Logstash 配置选项可以控制 Logstash 的执行。如:指定管道设置、配置文件位置、日志记录选项等。运行 Logstash 时,大多数配置可以命令行中指定,并覆盖文件的相关配置。
node.name默认值:计算机的主机名
节点的名称。path.data默认值:计算机的主机名
Logstash及其插件用于任何持久需求的目录。pipeline.id默认值:main
管道的ID。pipeline.workers默认值:主机cpu数
设置output或filter插件的工作线程数。pipeline.batch.size默认值:125
单个工作线程从输入收集的最大事件数。pipeline.batch.delay默认值:50
创建管道事件批处理时,在将较小的批处理发送给管道工作人员之前,等待每个事件的时间(毫秒)。pipeline.unsafe_shutdown默认值:false
logstash在关闭时,默认会等到所有被处理的 event 都通过 output 输出后再执行关闭操作;如果设置为 true,则允许强制关闭,而不必等待 event 处理完毕,此时可能会丢失数据。pipeline.plugin_classloaders默认值:false
在独立的类加载器中加载 Java 插件以隔离它们的依赖项。pipeline.orderedauto
设置管道事件顺序。有效选项包括:
auto-如果是管道,则自动启用排序。workers 设置为 1,否则禁用。
true-在管道上强制排序,如果有多个工作线程则阻止Logstash启动。
false-禁用保持顺序所需的处理。pipeline.ecs_compatibilitydisabled
为 ecs_compatibility 设置管道的默认值,该设置可用于实现ecs兼容模式的插件,以便与 Elastic Common Schema 一起使用。path.configLOGSTASH_HOME/config
Logstash 的配置路径。config.stringN/A
用于主管道的管道配置的字符串。config.test_and_exitfalse
设置为 true 时,检查配置是否有效,然后退出。请注意,使用此设置不会检查grok模式的正确性。Logstash 可以从一个目录中读取多个配置文件。如果将此设置与日志相结合。level:debug,Logstash 将记录组合的配置文件,并用源文件注释每个配置块。config.reload.automaticfalse
当设置为true时,定期检查配置是否已更改,并在更改时重新加载配置。这也可以通过SIGHUP信号手动触发。config.reload.interval3s
Logstash检查配置文件更改的频率(以秒为单位)。请注意,单元限定符是必需的。config.debugfalse
设置为true时,将完全编译的配置显示为调试日志消息。还必须设置日志。级别:调试。警告:日志消息将包括以明文形式传递给插件配置的任何密码选项,并可能导致明文密码出现在日志中!config.support_escapesfalse
当设置为true时,带引号的字符串将处理以下转义序列:\n成为文字换行符(ASCII 10)。\r变成文字回车符(ASCII 13)。\t变为文字选项卡(ASCII 9)。\变成文字反斜杠\“变为文字双引号。'变为文字引号。queue.typememory
用于事件缓冲的内部队列模型。可选项:memory -内存,persisted-持久化。path.queuepath.data/queue
启用持久队列时存储数据文件的目录路径(queue.type:persisted)。queue.page_capacity64mb
启用持久队列时使用的页面数据文件的大小(queue.type:persisted)。队列数据由仅追加数据文件组成,这些文件被分隔成页面。queue.max_events0 (unlimited)
启用持久队列时队列中未读事件的最大数量(queue.type:persisted)。queue.max_bytes1024mb (1g)
队列的总容(queue.type:persisted)(字节数)。queue.checkpoint.acks1024
启用持久队列时,强制检查点之前确认的最大事件数(queue.type:persisted)。指定 queue.checkpoint。acks:0 将此值设置为无限制。queue.checkpoint.writes1024
启用持久队列时,在强制检查点之前写入的最大事件数(queue.type:persisted)。指定 queue.checkpoint。写入:0以将此值设置为无限制。queue.checkpoint.retrytrue
启用后,对于任何失败的检查点写入,Logstash将在每次尝试检查点写入时重试四次。不会重试任何后续错误。对于只有在Windows平台、具有非标准行为(如SAN)的文件系统上才能看到的失败的检查点写入,这是一种解决方法,除非在这些特定情况下,否则不建议使用。(queue.type:持久化)queue.drainfalse
启用后,Logstash 会等待持久队列(queue.type:persisted)清空后再关闭。dead_letter_queue.enablefalse
指示 Logstash 启用插件支持的DLQ功能的标志。dead_letter_queue.max_bytes1024mb
每个死信队列的最大大小。如果条目会将死信队列的大小增加到超过此设置,则会删除这些条目。dead_letter_queue.storage_policydrop_newer
定义在执行 dead_letter_queue 时要执行的操作。达到 maxbytes 设置:dropnewer 停止接受会使文件大小超过限制的新值,dropolder 删除最旧的事件,为新事件腾出空间。path.dead_letter_queuepath.data/dead_letter_queue
为死信队列存储数据文件的目录路径。api.enabledtrue
默认情况下启用 HTTP API。它可以被禁用,但依赖它的功能将无法按预期工作。api.environmentproduction
API返回所提供的字符串作为其响应的一部分。设置环境可能有助于消除生产环境和测试环境中名称相似的节点之间的歧义。api.http.host"127.0.0.1"
HTTP API端点的绑定地址。默认情况下,Logstash HTTP API 仅绑定到本地环回接口。安全配置后(api.ssl.enabled:true和api.auth.type:basic),HTTP api 绑定到所有可用接口。api.http.port9600-9700
HTTP API 端点的绑定端口。api.ssl.enabledfalse
设置为 true 可在 HTTP API 上启用 SSL。这样做需要同时使用 api.ssl.keystore。路径和 api.ssl.keystore。要设置的密码。api.ssl.keystore.pathN/A
用于保护Logstash API的有效 JKS 或 PKCS12 密钥库的路径。密钥库必须受密码保护,并且必须包含单个证书链和私钥。除非 api.ssl,否则将忽略此设置。enabled 设置为 true。api.ssl.keystore.passwordN/A
api.ssl.keystore.path 提供的密钥库密码。除非 api.ssl,否则将忽略此设置。enabled 设置为 true。api.auth.typenone
设置为 basic 以要求使用随 API.auth.basic.username 和 API.auth.basic.password 提供的凭据在API上进行 HTTP basic身份验证。api.auth.basic.usernameN/A
HTTP Basic身份验证所需的用户名已忽略,除非是api.auth。type设置为basic。api.auth.basic.passwordN/A
HTTP Basic 身份验证所需的密码。除非 api.auth,否则忽略。type 设置为 basic。它应该符合默认密码策略,该策略要求非空的最少 8 个字符字符串,包括数字、大写字母和小写字母。可以通过以下选项自定义默认密码策略:
设置 api.auth.basic.password_policy.include。digit REQUIRED(默认)只接受包含至少一个数字的密码,或OPTIONAL(可选)从要求中排除。
设置 api.auth.basic.password_policy.include。upper REQUIRED(默认)只接受包含至少一个大写字母的密码,或 OPTIONAL(可选)从要求中排除。
设置 api.auth.basic.password_policy.include。较低的REQUIRED(默认)只接受包含至少一个小写字母的密码,或OPTIONAL(可选)不接受要求。
设置 api.auth.basic.password_policy.include。symbol REQUIRED 只接受包含至少一个特殊字符的密码,或OPTIONAL(默认)不接受要求。
设置 api.auth.basic.password_policy.length 。如果希望密码的默认设置超过8个字符,则最小值为 9 到 1024。api.auth.basic.password_policy.modeWARN
当不满足密码要求时,引发WARN或ERROR消息。log.levelinfo
日志级别。有效选项包括:
fatal
error
warn
info
debug
tracelog.formatplain
日志格式。设置为json以json格式登录,或设置为 plain 以使用 Object#.inspect。path.logsLOGSTASH_HOME/logs
Logstash将其日志写入的目录。pipeline.separate_logsfalse
这是一个布尔设置,用于在不同的日志文件中按管道分隔日志。如果启用,Logstash将使用管道为每个管道创建不同的日志文件。id作为文件名。目标目录取自`path。日志设置。当Logstash中配置了许多管道时,如果您需要对单个管道中发生的情况进行故障排除,而不受其他管道的干扰,那么将每个管道中的日志行分开可能会很有帮助。path.plugins
插件路径。allow_superusertrue
设置为 true 允许或 false 阻止以超级用户身份运行 Logstash。
参考:
https://blog.csdn.net/UbuntuTouch/article/details/105973985
评论