
一、关于Beats
在集中式日志记录中,数据管道包括三个主要阶段:聚合,处理和存储。 在 ELK 堆栈中,传统上,前两个阶段是堆栈工作量 Logstash 的职责。执行这些任务需要付出一定的代价。 由于与 Logstash 的设计有关的内在问题,性能问题变得经常发生,尤其是在复杂的管道需要大量处理的情况下。将 Logstash 的部分职责外包的想法也应运而生,尤其是将数据提取任务转移到其他工具上。 正如本文中所描述的,这个想法首先在 Lumberjack 中体现出来,然后在 Logstash 转发器中体现出来。 最终,在随后的几个开发周期中,引入了新的改进协议,该协议成为现在所谓的 “Beats” 家族的骨干。
Beats 是轻量级(资源高效,无依赖性,小型)和开放源代码日志发送程序的集合,这些日志发送程序充当安装在基础结构中不同服务器上的代理,用于收集日志或指标(metrics)。这些可以是日志文件(Filebeat),网络数据(Packetbeat),服务器指标(Metricbeat)或 Elastic 和社区开发的越来越多的 Beats 可以收集的任何其他类型的数据。 收集后,数据将直接发送到 Elasticsearch 或 Logstash 中进行其他处理。Beats 建立在名为 libbeat 的 Go 框架之上,该框架用于数据转发,这意味着社区一直在开发和贡献新的 Beats。
1.1、Elastic Beats

1、Filebeat
顾名思义,Filebeat 用于收集和传送日志文件,它也是最常用的 Beat。 Filebeat 如此高效的事实之一就是它处理背压的方式 -- 因此,如果它连接的 Logstash 处于繁忙状态,Filebeat 会减慢其读取速率,并在减速结束后加快节奏。Filebeat 几乎可以安装在任何操作系统上,包括作为 Docker 容器安装,还随附用于特定平台(例如 Apache,MySQL,Docker等)的内部模块,其中包含这些平台的默认配置和 Kibana 对象。
2、Packetbeat
网络数据包分析器 Packetbeat 是第一个引入的 Beat。 Packetbeat 捕获服务器之间的网络流量,因此可用于应用程序和性能监视。Packetbeat 可以安装在受监视的服务器上,也可以安装在其专用服务器上。 Packetbeat 跟踪网络流量,解码协议并记录每笔交易的数据。 Packetbeat 支持的协议包括:DNS,HTTP,ICMP,Redis,MySQL,MongoDB,Cassandra 等。
3、Metricbeat
Metricbeat 是一种非常受欢迎的 beat,它收集并报告各种系统和平台的各种系统级指标。 Metricbeat 还支持用于从特定平台收集统计信息的内部模块。你可以使用这些模块和称为指标集的 metricsets 来配置 Metricbeat 收集指标的频率以及要收集哪些特定指标。
4、Heartbeat
Heartbeat 是用于 “uptime monitoring” 的。本质上,Heartbeat 是探测服务以检查它们是否可访问的功能,例如,它可以用来验证服务的正常运行时间是否符合你的 SLA。 你要做的就是为 Heartbeat 提供 URL 和正常运行时间指标的列表,以直接发送到Elasticsearch 或 Logstash 以便在建立索引之前发送到你的堆栈。
5、Auditbeat
Auditbeat 可用于审核 Linux 服务器上的用户和进程活动。 与其他传统的系统审核工具(systemd,auditd)类似,Auditbeat 可用于识别安全漏洞-文件更改,配置更改,恶意行为等。
6、Winlogbeat
Winlogbeat 仅会引起Windows系统管理员或工程师的兴趣,因为它是专门为收集 Windows 事件日志而设计的 Beat。 它可用于分析安全事件,已安装的更新等。
7、Functionbeat
Functionbeat 被定义为 “serverless” 的发件人,可以将其部署为收集数据并将其发送到 ELK 堆栈的功能。 Functionbeat 专为监视云环境而设计,目前已针对 Amazon 设置量身定制,可以部署为 Amazon Lambda 函数,以从 Amazon CloudWatch,Kinesis 和 SQS 收集数据。
1.2、社区 Beats
开源社区一直在努力开发新的 Beats。可以在 Beat 讨论论坛的 Community Beats 类别中发布问题并讨论问题。目前有超过90个 Beats。如果大家有发现有用的 Beat,可以直接下载并使用。
1.3、Beats在Elastic堆栈中是如何融入
到目前为止,有如下的三种方式能够把我们所感兴趣的数据导入到 Elasticsearch中:

正如上面所显示的那样,可以通过:
Beats:可以通过 beats 把数据直接导入到 Elasticsearch 中Logstash:可以 Logstash 把数据导入。Logstash 的数据来源也可以是 BeatsREST API:可以通过 Elastic 所提供的丰富的 API 来把数据导入到 Elasticsearch中。可以通过 Java, Python, Go, Nodejs 等各种 Elasticsearch API 来完成我们的数据导入。
Beats 是如何和其它的 Elastic Stack 一起工作的呢。
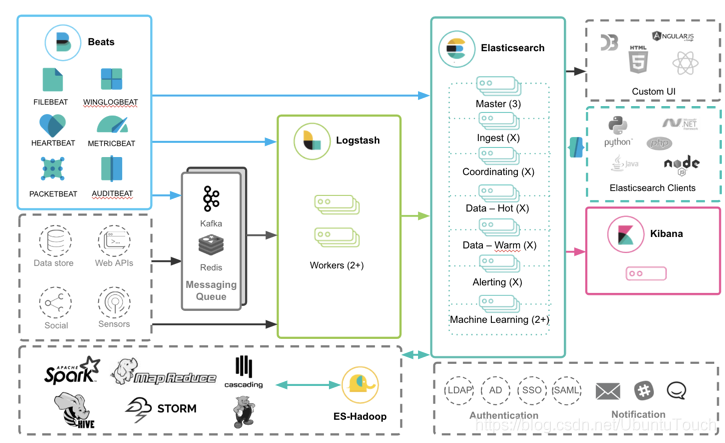
从上面可以看出来,Beats 的数据可以有如下的三种方式导入到 Elasticsearch 中:
Beats ==> Elasticsearch
Beats ==> Logstash ==> Elasticsearch
Beats ==> Kafka ==> Logstash ==> Elasticsearch
正如上面所显示的那样:
- 可以直接把 Beats 的数据传入到 Elasticsearch 中,甚至在现在的很多情况中,这也是一种比较受欢迎的一种方案。它甚至可以结合 Elasticsearch 所提供的 pipeline 一起完成更为强大的组合。
- 可以利用 Logstash 所提供的强大的filter组合对数据流进行处理:解析,丰富,转换,删除,添加等等。你可以参阅我之前的文章 “Data转换,分析,提取,丰富及核心操作”。
- 针对有些情况,如果我们的数据流具有不确定性,比如可能在某个时刻生产大量的数据,从而导致 Logstash 不能及时处理,我们可以通过 Kafka 或者 Redis 做为 Messaging Queue 来做一个缓存。
1.4、摄入管道(ingest pipeline)
在 Elasticsearch 的节点中,有一类节点是 ingest node。ingest pipeline 运行于 ingest node 之上。
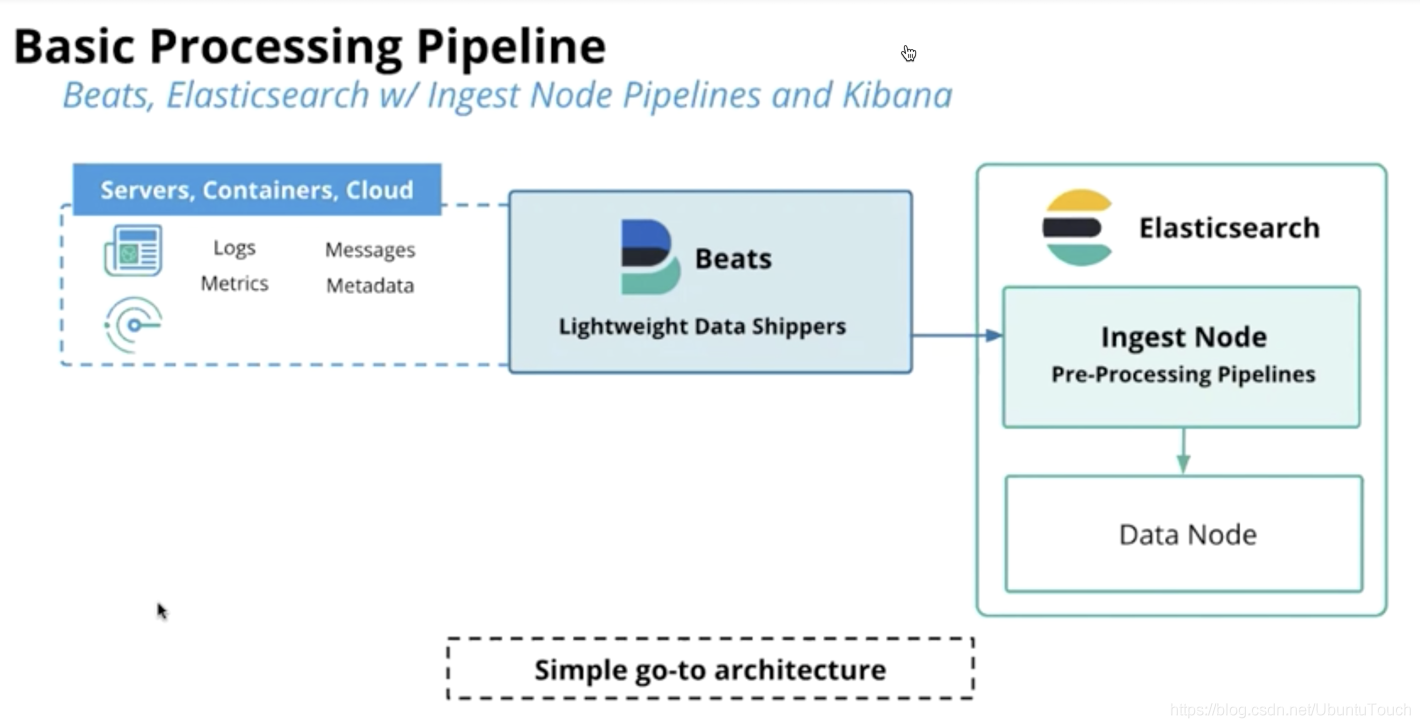
它提供了在对文档建立索引之前对其进行预处理的功能:
- 解析,转换并丰富数据。
- 管道允许你配置将要使用的处理器。
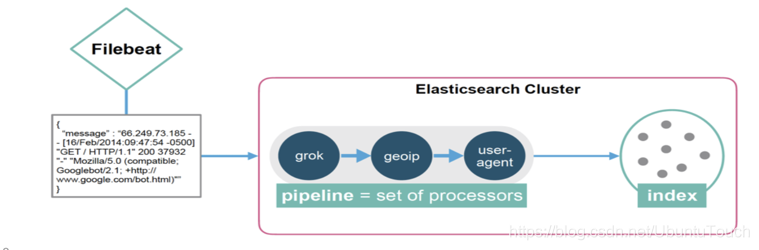
在上面的图中,可以看出来,我们可以使用在 Elasticsearch 集群里的 ingest node 来运行我们所定义的 processors。这些 processors 定义于 Elastic 的官方文档 Processors。
1.5、Libeat-创建 Beats 的 Go 架构
Libbeat 是一个用于数据转发的库。Beats 构建在名为 libbeat 的 Go 框架之上。 它是一个开源的软件。可以在地址 libbeat 找到它的源码。它可以轻松为你想要发送到 Elasticsearch 的任何类型的数据创建自定义 Beat。
对于一个 beat 来说,它可以分为如下的两个部分:数据收集器,数据处理器及发布器。后面的这个部分由 libbeat 来提供。

上面的 processor 可以由 Define processors 来了解。下面是其中的一些 processor 的例子:
- add_cloud_metadata
- add_locale
- decode_json_fields
- add_fields
- drop_event
- drop_fields
- include_fields
- add_kubernetes_metadata
- add_docker_metadata
二、启动 Filebeat 及 Metricbeat
2.1、Filebeat 总览
Filebeat 是用于转发和集中日志数据的轻量级传送程序。 作为服务器上的代理安装,Filebeat 监视你指定的日志文件或位置,收集日志事件,并将它们转发到 Elasticsearch 或 Logstash 以进行索引。
Filebeat 具有如下的一些特性:
正确处理日志旋转:针对每隔一个时间段生产一个新的日志的案例,Filebeat 可以帮我们正确地处理新生产的日志,并重新启动对新生成日志的处理。背压敏感:如果日志生成的速度过快,从而导致 Filebeat 生产的速度超过 Elasticsearch 处理的速度,那么 Filebeat 可以自动调节处理的速度,以达到 Elasticsearch 可以处理的范围内。“至少一次”保证:每个日志生成的事件至少被处理一次。结构化日志:可以处理结构化的日志数据数据。多行事件:如果一个日志有多行信息,也可以被正确处理,比如错误信息往往是多行数据。条件过滤:可以有条件地过滤一些事件。
Filebeat 的工作方式如下:启动 Filebeat 时,它将启动一个或多个输入,这些输入将在为日志数据指定的位置中查找。对于 Filebeat 所找到的每个日志,Filebeat 都会启动收集器(havester)。 每个收割机都读取一个日志以获取新内容,并将新日志数据发送到 libbeat。libbeat 会汇总事件,并将汇总的数据发送到为 Filebeat 配置的输出。
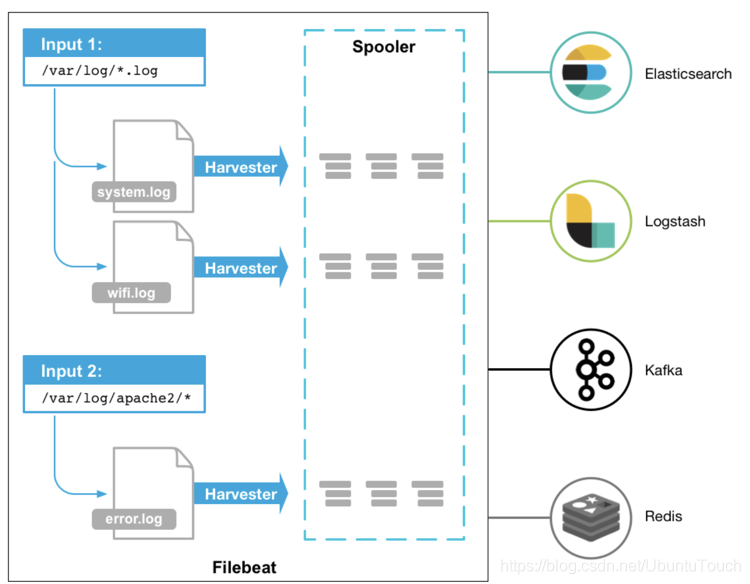
从上面有可以看出来在 spooler 里有一些缓存,这个可以用于重新发送以确保至少一次的事件消费,同时也可以用于背压敏感。一旦 Filebeat 生成的事件的速度超过 Elasticsearch 能够处理的极限,这个缓存可以用于存储一些事件。每个 Filebeat 可以配置多个 input,并且每个 input 可以配置来采集一个或多个文件路径的文件。 就像上面的图显示的那样,Filebeat 支持多种输入方式。你可以在 Filebeat 的配置文件 filebeat.yml 中进行多次的配置:
filebeat.yml
filebeat.inputs:
- type: log
paths:
- /var/log/system.log
- /var/log/wifi.log
- type: log
paths:
- "/var/log/apache2/*"
fields:
apache: true
fields_under_root: true
Filbeat 支持如下的一些输出:
Elasticsearch
Logstash
Kafka
Redis
File
Console
Cloud
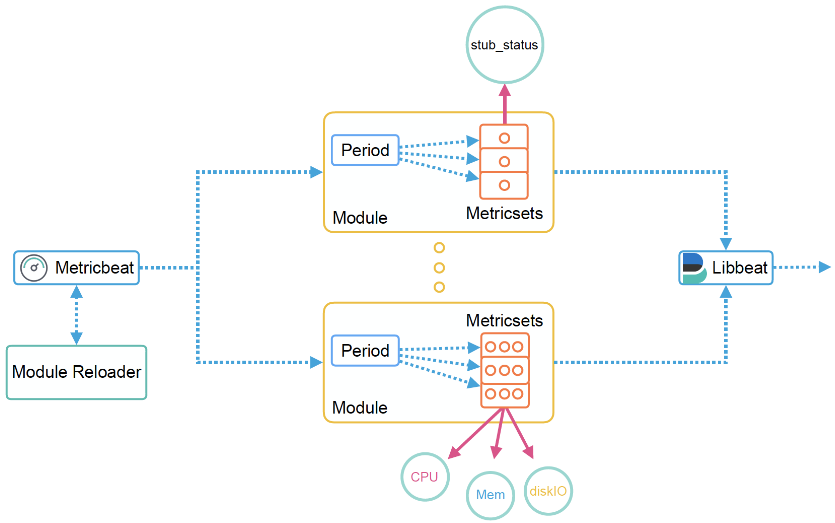
2.2、Metricbeat 总览
Metricbeat 是一种轻量级的数据摄入器,你可以将其安装在服务器上,以定期从操作系统和服务器上运行的服务收集指标。 Metricbeat 会收集它的指标和统计信息,并将其运送到你指定的输出,例如 Elasticsearch 或 Logstash。
Mettric 类型:Metric 可以收集如下两种类型的指标:
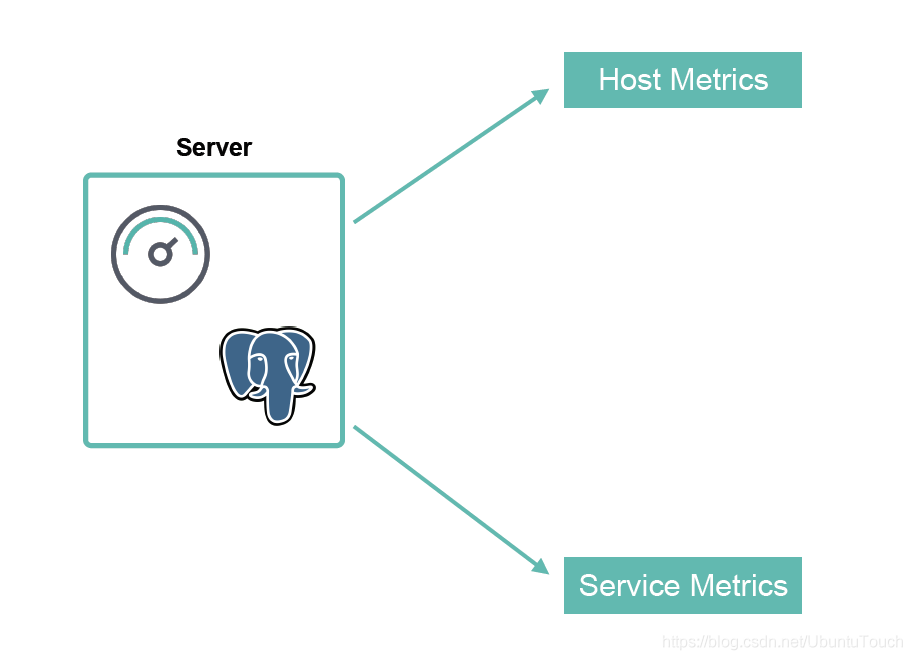
为了能够收集指标,我们必须把 Metricbeat 部署在需要监控的机器上。它除了能够对主机机进行指标采集,比如内存,CPU,硬盘等的实用情况,它同时也可以对运用于上面的服务比如 Nginx, Apache, MySQL 等的指标进行采集。
Metricbeat 通过从服务器上运行的系统和服务收集指标来帮助你监视服务器,例如:
Apache
HAProxy
MongoDB
MySQL
Nginx
PostgreSQL
Redis
System
Zookeeper
Metricbeat 具有一些特性:
- 轮询服务的 API 以收集指标。
- 有效地将指标存储在 Elasticsearch 中。
- 通过 JMX / Jolokia,Prometheus,Dropwizard,Graphite 的应用程序指标。
- 自动贴标:表明是从 AWS, Docker, Kubernetes, GoogleCloud 或 Azure 采集的。
Metricbeat 由模块和指标集组成。 Metricbeat 模块定义了从特定服务(例如 Redis,MySQL 等)收集数据的基本逻辑。 该模块指定有关服务的详细信息,包括如何连接,收集指标的频率以及收集哪些指标。
每个模块都有一个或多个指标集。 指标集是模块的一部分,用于获取和构建数据。 指标标准集不是将每个指标收集为单独的事件,而是在对远程系统的单个请求中检索多个相关指标的列表。 因此,例如,Redis 模块提供了一个指标集,该指标集通过运行 INFO 命令并解析返回的结果来从 Redis 收集信息和统计信息。
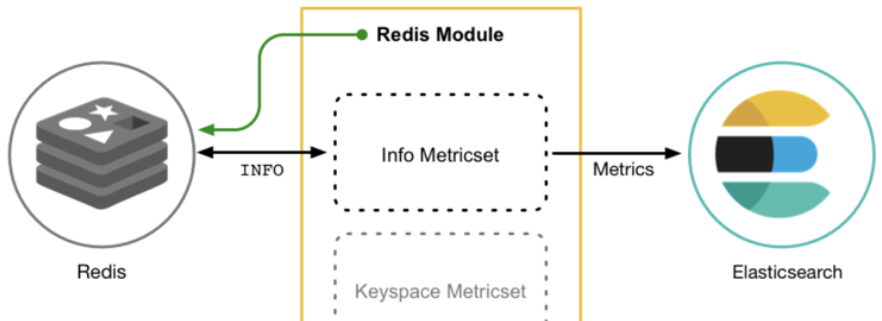
同样,MySQL 模块提供了一个状态指标集,该指标集通过运行 SHOW GLOBAL STATUS SQL 查询 从 MySQL 收集数据。 通过在远程服务器返回的单个请求中将相关指标标准集组合在一起,指标标准集使你更轻松。 如果没有用户启用的指标标准集,则大多数模块都具有默认指标集。
Metricbeat 通过根据你在配置模块时指定的周期值定期询问主机系统来检索指标。 由于多个指标集可以将请求发送到同一服务,因此 Metricbeat 尽可能重用连接。 如果 Metricbeat 在超时配置设置指定的时间内无法连接到主机系统,它将返回错误。 Metricbeat 异步发送事件,这意味着未确认事件检索。 如果配置的输出不可用,则事件可能会丢失。
三、什么是 Filebeat 和 Merticbeat 模块
一个 Filebeat 模块通常由如下的部分组成:
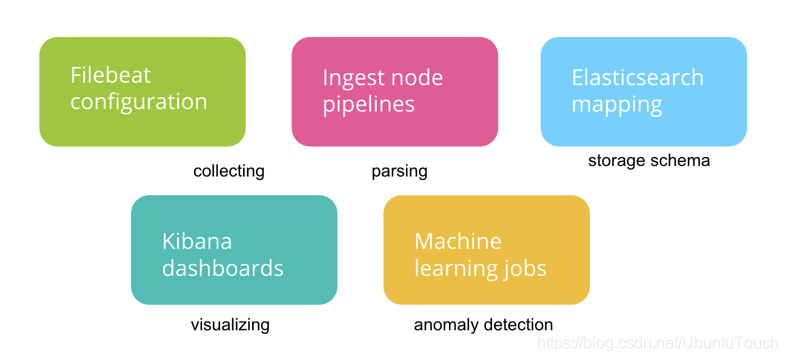
Filebeat 模块简化了常见日志格式的收集,解析和可视化。文件集包含以下内容:
- Filebeat 输入配置,其中包含在其中查找日志文件的默认路径。 这些默认路径取决于操作系统。 Filebeat 配置还负责在需要时将多行事件缝合在一起。
- Elasticsearch Ingest Node 管道定义,用于解析日志行。
- 字段定义,用于为每个字段配置具有正确类型的 Elasticsearch。 它们还包含每个字段的简短说明。
- 示例 Kibana 仪表板(如果有)可用于可视化日志文件。
Filebeat 会根据你的环境自动调整这些配置,并将它们加载到相应的 Elastic Stack 组件中。
一个典型的模块(例如,对于 Nginx 日志)由一个或多个文件集(对于 Nginx,访问和错误)组成,比如,Nginx 模块解析 NGINX HTTP 服务器创建的访问和错误日志。它在幕后执行如下的一些任务:
- 设置日志文件的默认路径(你可以更改)
- 确保每个多行日志事件都作为单个事件发送
- 使用 ingest node 来解析和处理日志行
- 将数据塑造成适合在 Kibana 中进行可视化的结构
- 部署仪表板以可视化日志数据
针对其它的 Beats 模块来说,基本和 Filebeat 一样。目前针对 Elasticsearch 所提供的模块来说,有非常多的模块可以供使用:

评论