
1、如何合理的配置重启策略。
2、Flink中的重启策略和恢复策略的发展实现过程。
3、如何管理Flink作业配置。
一、如何设置 Flink Job RestartStrategy(重启策略)
1.1、常见错误导致 Flink 作业重启
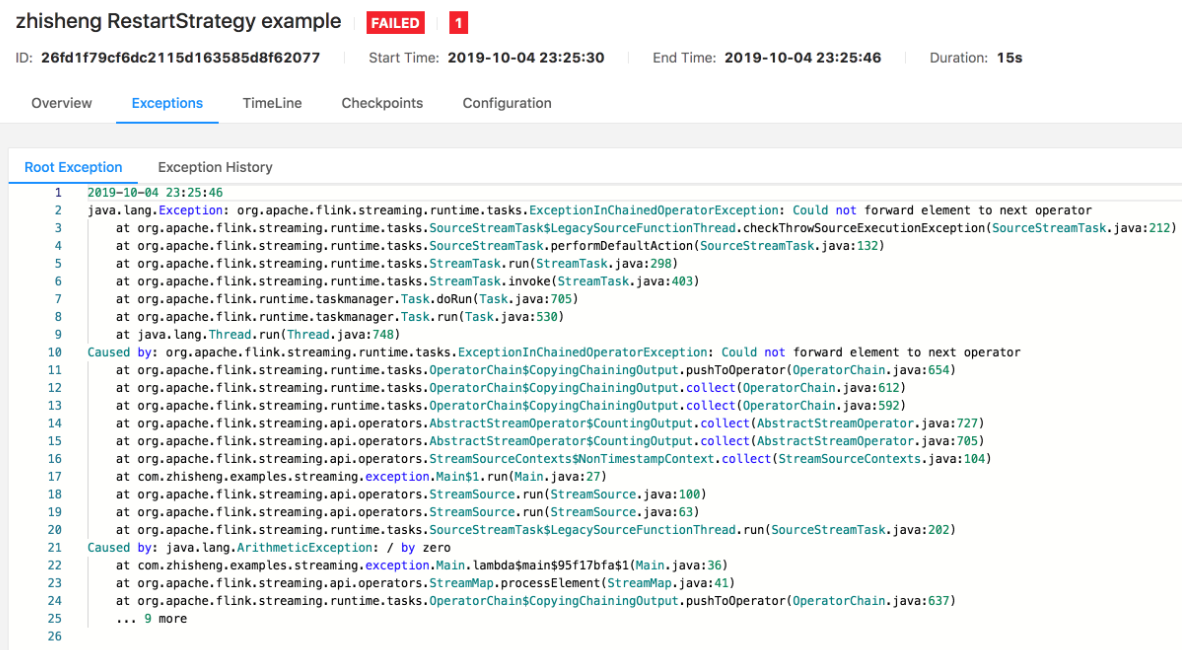
有时候因为数据的问题(不合规范、为 null 等),这时在处理这些脏数据的时候可能就会遇到各种各样的异常错误,比如空指针、数组越界、数据类型转换错误等。可能你会说只要过滤掉这种脏数据就行了,或者进行异常捕获就不会导致 Job 不断重启的问题了。
如果做好了脏数据的过滤和异常的捕获,Job 的稳定性确实有保证,但是复杂的 Job 下每个算子可能都会产生出脏数据(包含源数据可能也会为空或者不合法的数据),不可能在每个算子里面也用一个大的 try catch 做一个异常捕获,所以脏数据和异常简直就是防不胜防,不过还是要尽力的保证代码的健壮性,但是也要配置好 Flink Job 的 RestartStrategy(重启策略)。
1.2、RestartStrategy 简介
RestartStrategy,重启策略,在遇到机器或者代码等不可预知的问题时导致 Job 或者 Task 挂掉的时候,它会根据配置的重启策略将 Job 或者受影响的 Task 拉起来重新执行,以使得作业恢复到之前正常执行状态。Flink 中的重启策略决定了是否要重启 Job 或者 Task,以及重启的次数和每次重启的时间间隔。
1.3、为什么需要 RestartStrategy?
重启策略会让 Job 从上一次完整的 Checkpoint 处恢复状态,保证 Job 和挂之前的状态保持一致,另外还可以让 Job 继续处理数据,不会出现 Job 挂了导致消息出现大量堆积的问题,合理的设置重启策略可以减少 Job 不可用时间和避免人工介入处理故障的运维成本,因此重启策略对于 Flink Job 的稳定性来说有着举足轻重的作用。
1.4、如何配置 RestartStrategy?
如果 Flink Job 没有单独设置重启重启策略的话,则会使用集群启动时加载的默认重启策略,如果 Flink Job 中单独设置了重启策略则会覆盖默认的集群重启策略。默认重启策略可以在 Flink 的配置文件 flink-conf.yaml 中设置,由 restart-strategy 参数控制,有 fixed-delay(固定延时重启策略)、failure-rate(故障率重启策略)、none(不重启策略)三种可以选择,如果选择的参数不同,对应的其他参数也不同。下面分别介绍这几种重启策略和如何配置。
1、FixedDelayRestartStrategy(固定延时重启策略)
restart-strategy: fixed-delay
restart-strategy.fixed-delay.attempts: 3 #表示作业重启的最大次数,启用 checkpoint 的话是 Integer.MAX_VALUE,否则是 1。
restart-strategy.fixed-delay.delay: 10 s #如果设置分钟可以类似 1 min,该参数表示两次重启之间的时间间隔,当程序与外部系统有连接交互时延迟重启可能会有帮助,启用 checkpoint 的话,延迟重启的时间是 10 秒,否则使用 akka.ask.timeout 的值。
在程序中设置固定延迟重启策略的话如下:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 尝试重启的次数
Time.of(10, TimeUnit.SECONDS) // 延时
));
2、FailureRateRestartStrategy(故障率重启策略)
FailureRateRestartStrategy 是故障率重启策略,在发生故障之后重启作业,如果固定时间间隔之内发生故障的次数超过设置的值后,作业就会失败停止,该重启策略也支持设置连续两次重启之间的等待时间。
restart-strategy: failure-rate
restart-strategy.failure-rate.max-failures-per-interval: 3 #固定时间间隔内允许的最大重启次数,默认 1
restart-strategy.failure-rate.failure-rate-interval: 5 min #固定时间间隔,默认 1 分钟
restart-strategy.failure-rate.delay: 10 s #连续两次重启尝试之间的延迟时间,默认是 akka.ask.timeout
可以在应用程序中这样设置来配置故障率重启策略:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 固定时间间隔允许 Job 重启的最大次数
Time.of(5, TimeUnit.MINUTES), // 固定时间间隔
Time.of(10, TimeUnit.SECONDS) // 两次重启的延迟时间
));
3、NoRestartStrategy(不重启策略)
NoRestartStrategy 作业不重启策略,直接失败停止,在 flink-conf.yaml 中配置如下:
restart-strategy: none
在程序中如下设置即可配置不重启:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());
4、Fallback(备用重启策略)
如果程序没有启用 Checkpoint,则采用不重启策略,如果开启了 Checkpoint 且没有设置重启策略,那么采用固定延时重启策略,最大重启次数为 Integer.MAX_VALUE。
在应用程序中配置好了固定延时重启策略,可以测试一下代码异常后导致 Job 失败后重启的情况,然后观察日志,可以看到 Job 重启相关的日志:
[flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Try to restart or fail the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) if no longer possible.
[flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) switched from state FAILING to RESTARTING.
[flink-akka.actor.default-dispatcher-5] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Restarting the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0).
最后重启次数达到配置的最大重启次数后 Job 还没有起来的话,则会停止 Job 并打印日志:
[flink-akka.actor.default-dispatcher-2] INFO org.apache.flink.runtime.executiongraph.ExecutionGraph - Could not restart the job zhisheng default RestartStrategy example (a890361aed156610b354813894d02cd0) because the restart strategy prevented it.
Flink 中几种重启策略的设置如上,大家可以根据需要选择合适的重启策略,比如如果程序抛出了空指针异常,但是你配置的是一直无限重启,那么就会导致 Job 一直在重启,这样无非再浪费机器资源,这种情况下可以配置重试固定次数,每次隔多久重试的固定延时重启策略,这样在重试一定次数后 Job 就会停止,如果对 Job 的状态做了监控告警的话,那么你就会收到告警信息,这样也会提示你去查看 Job 的运行状况,能及时的去发现和修复 Job 的问题。
1.6、Failover Strategies(故障恢复策略)
1、重启所有的任务
2、基于Region的局部故障重启策略
二、如何使用 Flink ParameterTool 读取配置?
Flink相关配置,像算子的并行度配置、Kafka 数据源的配置(broker 地址、topic 名、group.id)、Checkpoint 是否开启、状态后端存储路径、数据库地址、用户名和密码等,各种各样的配置都杂乱在一起,作业是否可以不修改任何配置就直接在各种环境(开发、测试、预发、生产)运行呢?可能每个环境的这些配置对应的值都是不一样的,如果是直接在代码里面写死的配置,那这下子就比较痛苦了,每次换个环境去运行测试你的作业,都要重新去修改代码中的配置,然后编译打包,提交运行,这样就要花费很多时间在这些重复的劳动力上了。
2.1、Flink Job 配置
使用 Configuration
Flink 提供了 withParameters 方法,它可以传递 Configuration 中的参数给,要使用它,需要实现那些 Rich 函数,比如实现 RichMapFunction,而不是 MapFunction,因为 Rich 函数中有 open 方法,然后可以重写 open 方法通过 Configuration 获取到传入的参数值。
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
// Configuration 类来存储参数
Configuration configuration = new Configuration();
configuration.setString("name", "zhisheng");
env.fromElements(WORDS)
.flatMap(new RichFlatMapFunction<String, Tuple2<String, Integer>>() {
String name;
@Override
public void open(Configuration parameters) throws Exception {
//读取配置
name = parameters.getString("name", "");
}
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] splits = value.toLowerCase().split("\\W+");
for (String split : splits) {
if (split.length() > 0) {
out.collect(new Tuple2<>(split + name, 1));
}
}
}
}).withParameters(configuration) //将参数传递给函数
.print();
但是要注意这个 withParameters 只在批程序中支持,流程序中是没有该方法的,并且这个 withParameters 要在每个算子后面使用才行,并不是一次使用就所有都可以获取到,如果所有算子都要该配置,那么就重复设置多次就会比较繁琐。
2.2、ParameterTool 管理配置
上面通过 Configuration 的局限性很大,其实在 Flink 中还可以通过使用 ParameterTool 类读取配置,它可以读取环境变量、运行参数、配置文件,下面分别讲下每种如何使用。
1、读取运行参数
Flink UI 上是支持为每个 Job 单独传入 arguments(参数)的,它的格式要求是如下这种。
--brokers 127.0.0.1:9200
--username admin
--password 123456
或者这种
-brokers 127.0.0.1:9200
-username admin
-password 123456
然后在 Flink 程序中你可以直接使用 ParameterTool.fromArgs(args) 获取到所有的参数,然后如果你要获取某个参数对应的值的话,可以通过 parameterTool.get("username") 方法。那么在这个地方其实你可以将配置放在一个第三方的接口,然后这个参数值中传入一个接口,拿到该接口后就能够通过请求去获取更多你想要的配置。
2、读取系统属性
ParameterTool 还支持通过 ParameterTool.fromSystemProperties() 方法读取系统属性。
3、读取配置文件
除了上面两种外,ParameterTool 还支持
ParameterTool.fromPropertiesFile("/application.properties")
读取 properties 配置文件。可以将所有要配置的地方(比如并行度和一些 Kafka、MySQL 等配置)都写成可配置的,然后其对应的 key 和 value 值都写在配置文件中,最后通过 ParameterTool 去读取配置文件获取对应的值。
4、ParameterTool 获取值
ParameterTool 类提供了很多便捷方法去获取值,如下图所示。

以在应用程序的 main() 方法中直接使用这些方法返回的值,例如:可以按如下方法来设置一个算子的并行度:
ParameterTool parameters = ParameterTool.fromArgs(args);
int parallelism = parameters.get("mapParallelism", 2);
DataStream<Tuple2<String, Integer>> counts = data.flatMap(new Tokenizer()).setParallelism(parallelism);
因为 ParameterTool 是可序列化的,所以你可以将它当作参数进行传递给自定义的函数。
ParameterTool parameters = ParameterTool.fromArgs(args);
DataStream<Tuple2<String, Integer>> counts = dara.flatMap(new Tokenizer(parameters));
然后在函数内部使用 ParameterTool 来获取命令行参数,这样就意味着在作业任何地方都可以获取到参数,而不是像 withParameters 一样需要每次都设置。
5、注册全局参数
在 ExecutionConfig 中可以将 ParameterTool 注册为全作业参数的参数,这样就可以被 JobManager 的 web 端以及用户自定义函数中以配置值的形式访问。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.getConfig().setGlobalJobParameters(ParameterTool.fromArgs(args));
然后就可以在用户自定义的 Rich 函数中像如下这样获取到参数值了。
env.addSource(new RichSourceFunction<String>() {
@Override
public void run(SourceContext<String> sourceContext) throws Exception {
while (true) {
ParameterTool parameterTool = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters();
sourceContext.collect(System.currentTimeMillis() + parameterTool.get("os.name") + parameterTool.get("user.home"));
}
}
@Override
public void cancel() {
}
})
参考:
public static ParameterTool createParameterTool(final String[] args) throws Exception {
return ParameterTool
.fromPropertiesFile(ExecutionEnv.class.getResourceAsStream("/application.properties"))
.mergeWith(ParameterTool.fromArgs(args))
.mergeWith(ParameterTool.fromSystemProperties())
.mergeWith(ParameterTool.fromMap(getenv()));// mergeWith 会使用最新的配置
}
//获取 Job 设置的环境变量
private static Map<String, String> getenv() {
Map<String, String> map = new HashMap<>();
for (Map.Entry<String, String> entry : System.getenv().entrySet()) {
map.put(entry.getKey().toLowerCase().replace('_', '.'), entry.getValue());
}
return map;
}
评论