
Flink 对比其他的流处理框架最大的特点是其支持状态,本文将深度讲解 Flink 中的状态分类,如何在不同的场景使用不同的状态,接着会介绍 Flink 中的多种状态存储,最后会介绍 Checkpoint 和 Savepoint 的使用方式以及如何恢复状态。
一、Flink 中的状态
1.1、为什么需要 State?
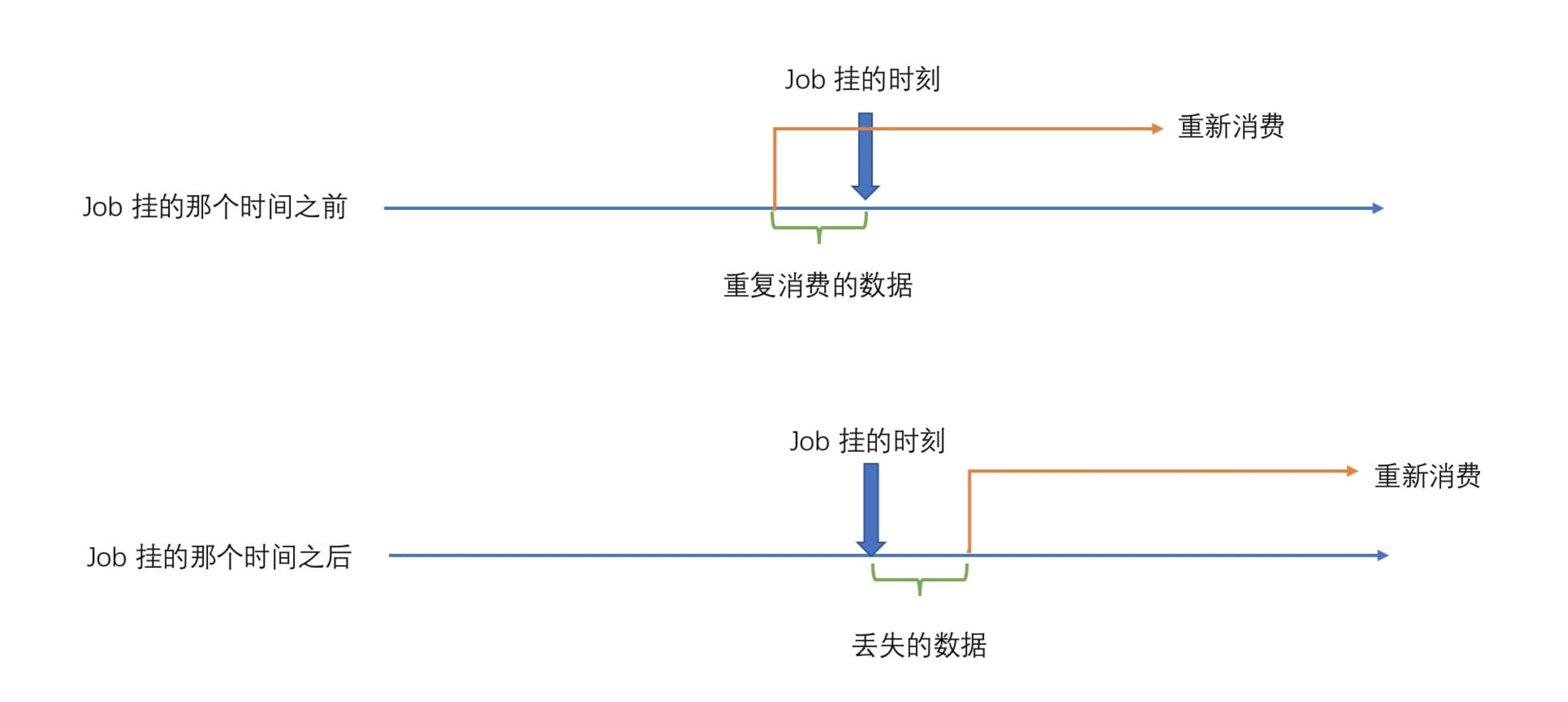
对于流处理系统,数据是一条一条被处理的,如果没有对数据处理的进度进行记录,那么如果这个处理数据的 Job 因为机器问题或者其他问题而导致重启,那么它是不知道上一次处理数据是到哪个地方了,这样的情况下如果是批数据,倒是可以很好的解决(重新将这份固定的数据再执行一遍),但是流数据那就麻烦了,根本不知道什么在 Job 挂的那个时刻数据消费到哪里了?那么重启的话该从哪里开始重新消费呢?你可以有以下选择(因为你可能也不确定 Job 挂的具体时间):
- Job 挂的那个时间之前:如果是从 Job 挂之前开始重新消费的话,那么会导致部分数据(从新消费的时间点到之前 Job 挂的那个时间点之前的数据)重复消费。
- Job 挂的那个时间之后:如果是从 Job 挂之后开始消费的话,那么会导致部分数据(从 Job 挂的那个时间点到新消费的时间点产生的数据)丢失,没有消费。
上面两种情况用图片描述如下图所示。
为了解决上面两种情况(数据重复消费或者数据没有消费)的发生,那么是不是就得需要个什么东西做个记录将这种数据消费状态,Flink state 就这样诞生了,state 中存储着每条数据消费后数据的消费点(生产环境需要持久化这些状态),当 Job 因为某种错误或者其他原因导致重启时,就能够从 Checkpoint(定时将 state 做一个全局快照,在 Flink 中,为了能够让 Job 在运行的过程中保证容错性,才会对这些 state 做一个快照) 中的 state 数据进行恢复。
1.2、State 的种类
在 Flink 中有两个基本的 state:Keyed state 和 Operator state,下面来分别介绍一下这两种 State。
1.3、Keyed State
Keyed State 总是和具体的 key 相关联,也只能在 KeyedStream 的 function 和 operator 上使用。你可以将 Keyed State 当作是 Operator State 的一种特例,但是它是被分区或分片的。每个 Keyed State 分区对应一个 key 的 Operator State,对于某个 key 在某个分区上有唯一的状态。逻辑上,Keyed State 总是对应着一个 <parallel-operator-instance, key> 二元组,在某种程度上,因为每个具体的 key 总是属于唯一一个具体的 parallel-operator-instance(并行操作实例),这种情况下,那么就可以简化认为是 <operator, key>。Keyed State 可以进一步组织成 Key Group,Key Group 是 Flink 重新分配 Keyed State 的最小单元,所以有多少个并行,就会有多少个 Key Group。在执行过程中,每个 keyed operator 的并行实例会处理来自不同 key 的不同 Key Group。
1.4、Operator State
对 Operator State 而言,每个 operator state 都对应着一个并行实例。Kafka Connector 就是一个很好的例子。每个 Kafka consumer 的并行实例都会持有一份topic partition 和 offset 的 map,这个 map 就是它的 Operator State。
当并行度发生变化时,Operator State 可以将状态在所有的并行实例中进行重分配,并且提供了多种方式来进行重分配。
在 Flink 源码中,在 flink-core module 下的 org.apache.flink.api.common.state 中可以看到 Flink 中所有和 State 相关的类,如下图所示。
1.5、Raw State 和 Managed State
Keyed State 和 Operator State 都有两种存在形式,即 Raw State(原始状态)和 Managed State(托管状态)。
原始状态是 Operator(算子)保存它们自己的数据结构中的 state,当 Checkpoint 时,原始状态会以字节流的形式写入进 Checkpoint 中。Flink 并不知道 State 的数据结构长啥样,仅能看到原生的字节数组。
托管状态可以使用 Flink runtime 提供的数据结构来表示,例如内部哈希表或者 RocksDB。具体有 ValueState,ListState 等。Flink runtime 会对这些状态进行编码然后将它们写入到 Checkpoint 中。
DataStream 的所有 function 都可以使用托管状态,但是原生状态只能在实现 operator 的时候使用。相对于原生状态,推荐使用托管状态,因为如果使用托管状态,当并行度发生改变时,Flink 可以自动的帮你重分配 state,同时还可以更好的管理内存。
注意:如果你的托管状态需要特殊的序列化,目前 Flink 还不支持。
1.6、如何使用托管的 Keyed State
托管的 Keyed State 接口提供对不同类型状态(这些状态的范围都是当前输入元素的 key)的访问,这意味着这种状态只能在通过 stream.keyBy() 创建的 KeyedStream 上使用。
我们首先来看一下有哪些可以使用的状态,然后再来看看它们在程序中是如何使用的:
- ValueState
: 保存一个可以更新和获取的值(每个 Key 一个 value),可以用 update(T) 来更新 value,可以用 value() 来获取 value。 - ListState
: 保存一个值的列表,用 add(T) 或者 addAll(List ) 来添加,用 Iterable get() 来获取。 - ReducingState
: 保存一个值,这个值是状态的很多值的聚合结果,接口和 ListState 类似,但是可以用相应的 ReduceFunction 来聚合。 - AggregatingState<IN, OUT>: 保存很多值的聚合结果的单一值,与 ReducingState 相比,不同点在于聚合类型可以和元素类型不同,提供 AggregateFunction 来实现聚合。
- FoldingState<T, ACC>: 与 AggregatingState 类似,除了使用 FoldFunction 进行聚合。
- MapState<UK, UV>: 保存一组映射,可以将 kv 放进这个状态,使用 put(UK, UV) 或者 putAll(Map<UK, UV>) 添加,或者使用 get(UK) 获取。
所有类型的状态都有一个 clear() 方法来清除当前的状态。
注意:FoldingState 已经不推荐使用,可以用 AggregatingState 来代替。
需要注意,上面的这些状态对象仅用来和状态打交道,状态不一定保存在内存中,也可以存储在磁盘或者其他地方。另外,你获取到的状态的值是取决于输入元素的 key,因此如果 key 不同,那么在一次调用用户函数中获得的值可能与另一次调用的值不同。
要使用一个状态对象,需要先创建一个 StateDescriptor,它包含了状态的名字(你可以创建若干个 state,但是它们必须要有唯一的值以便能够引用它们),状态的值的类型,或许还有一个用户定义的函数,比如 ReduceFunction。根据你想要使用的 state 类型,你可以创建 ValueStateDescriptor、ListStateDescriptor、ReducingStateDescriptor、FoldingStateDescriptor 或者 MapStateDescriptor。
状态只能通过 RuntimeContext 来获取,所以只能在 RichFunction 里面使用。RichFunction 中你可以通过 RuntimeContext 用下述方法获取状态:
- ValueState
getState(ValueStateDescriptor ) - ReducingState
getReducingState(ReducingStateDescriptor ) - ListState
getListState(ListStateDescriptor ) - AggregatingState<IN, OUT> getAggregatingState(AggregatingState<IN, OUT>)
- FoldingState<T, ACC> getFoldingState(FoldingStateDescriptor<T, ACC>)
- MapState<UK, UV> getMapState(MapStateDescriptor<UK, UV>)
示例:
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
//ValueState 使用方式,第一个字段是 count,第二个字段是运行的和
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
//访问状态的 value 值
Tuple2<Long, Long> currentSum = sum.value();
//更新 count
currentSum.f0 += 1;
//更新 sum
currentSum.f1 += input.f1;
//更新状态
sum.update(currentSum);
//如果 count 等于 2, 发出平均值并清除状态
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", //状态名称
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), //类型信息
Tuple2.of(0L, 0L)); //状态的默认值
sum = getRuntimeContext().getState(descriptor);//获取状态
}
}
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(0)
.flatMap(new CountWindowAverage())
.print();
//结果会打印出 (1,4) 和 (1,5)
这个例子实现了一个简单的计数器,使用元组的第一个字段来进行分组(这个例子中,所有的 key 都是 1),这个 CountWindowAverage 函数将计数和运行时总和保存在一个 ValueState 中,一旦计数等于 2,就会发出平均值并清理 state,因此又从 0 开始。请注意,如果在第一个字段中具有不同值的元组,则这将为每个不同的输入 key保存不同的 state 值。
1.7、State TTL(存活时间)
随着作业的运行时间变长,作业的状态也会逐渐的变大,那么很有可能就会影响作业的稳定性,这时如果有状态的过期这种功能就可以将历史的一些状态清除,对应在 Flink 中的就是 State TTL,接下来将对其做详细介绍。
State TTL 介绍
TTL 可以分配给任何类型的 Keyed state,如果一个状态设置了 TTL,那么当状态过期时,那么之前存储的状态值会被清除。所有的状态集合类型都支持单个入口的 TTL,这意味着 List 集合元素和 Map 集合都支持独立到期。为了使用状态 TTL,首先必须要构建 StateTtlConfig 配置对象,然后可以通过传递配置在 State descriptor 中启用 TTL 功能:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("test", String.class);
stateDescriptor.enableTimeToLive(ttlConfig); //开启 ttl
上面配置中有几个选项需要注意:
1、newBuilder 方法的第一个参数是必需的,它代表着状态存活时间。
2、UpdateType 配置状态 TTL 更新时(默认为 OnCreateAndWrite):
- StateTtlConfig.UpdateType.OnCreateAndWrite: 仅限创建和写入访问时更新。
- StateTtlConfig.UpdateType.OnReadAndWrite: 除了创建和写入访问,还支持在读取时更新。
3、StateVisibility 配置是否在读取访问时返回过期值(如果尚未清除),默认是 NeverReturnExpired:
- StateTtlConfig.StateVisibility.NeverReturnExpired: 永远不会返回过期值。
- StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp: 如果仍然可用则返回。
在 NeverReturnExpired 的情况下,过期状态表现得好像它不再存在,即使它仍然必须被删除。该选项对于在 TTL 之后必须严格用于读取访问的数据的用例是有用的,例如,应用程序使用隐私敏感数据.
另一个选项 ReturnExpiredIfNotCleanedUp 允许在清理之前返回过期状态。
注意:
- 状态后端会存储上次修改的时间戳以及对应的值,这意味着启用此功能会增加状态存储的消耗,堆状态后端存储一个额外的 Java 对象,其中包含对用户状态对象的引用和内存中原始的 long 值。RocksDB 状态后端存储为每个存储值、List、Map 都添加 8 个字节。
- 目前仅支持参考 processing time 的 TTL
- 使用启用 TTL 的描述符去尝试恢复先前未使用 TTL 配置的状态可能会导致兼容性失败或者 StateMigrationException 异常。
- TTL 配置并不是 Checkpoint 和 Savepoint 的一部分,而是 Flink 如何在当前运行的 Job 中处理它的方式。
- 只有当用户值序列化器可以处理 null 值时,具体 TTL 的 Map 状态当前才支持 null 值,如果序列化器不支持 null 值,则可以使用 NullableSerializer 来包装它(代价是需要一个额外的字节)。
清除过期 State
默认情况下,过期值只有在显式读出时才会被删除,例如通过调用 ValueState.value()。
注意:这意味着默认情况下,如果未读取过期状态,则不会删除它,这可能导致状态不断增长,这个特性在 Flink 未来的版本可能会发生变化。
此外,你可以在获取完整状态快照时激活清理状态,这样就可以减少状态的大小。在当前实现下不清除本地状态,但是在从上一个快照恢复的情况下,它不会包括已删除的过期状态,你可以在 StateTtlConfig 中这样配置:
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build();
此配置不适用于 RocksDB 状态后端中的增量 Checkpoint。对于现有的 Job,可以在 StateTtlConfig 中随时激活或停用此清理策略,例如,从保存点重启后。
除了在完整快照中清理外,你还可以在后台激活清理。如果使用的后端支持以下选项,则会激活 StateTtlConfig 中的默认后台清理:
import org.apache.flink.api.common.state.StateTtlConfig;
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInBackground()
.build();
要在后台对某些特殊清理进行更精细的控制,可以按照下面的说明单独配置它。目前,堆状态后端依赖于增量清理,RocksDB 后端使用压缩过滤器进行后台清理。
我们再来看看 TTL 对应着的类 StateTtlConfig 类中的具体实现,这样我们才能更加的理解其使用方式。
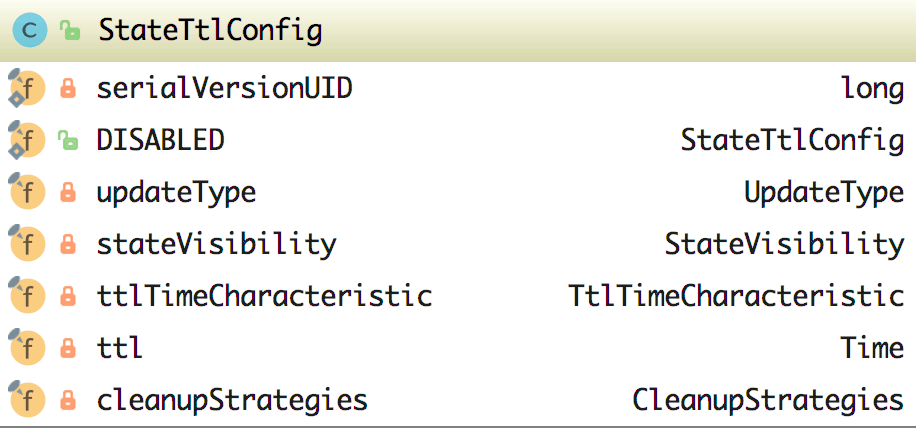
在该类中的属性如下图所示:
这些属性的功能如下:
- DISABLED:它默认创建了一个 UpdateType 为 Disabled 的 StateTtlConfig
- UpdateType:这个是一个枚举,包含 Disabled(代表 TTL 是禁用的,状态不会过期)、OnCreateAndWrite、OnReadAndWrite 可选
- StateVisibility:这也是一个枚举,包含了 ReturnExpiredIfNotCleanedUp、NeverReturnExpired
- TimeCharacteristic:这是时间特征,其实是只有 ProcessingTime 可选
- Time:设置 TTL 的时间,这里有两个参数 unit 和 size
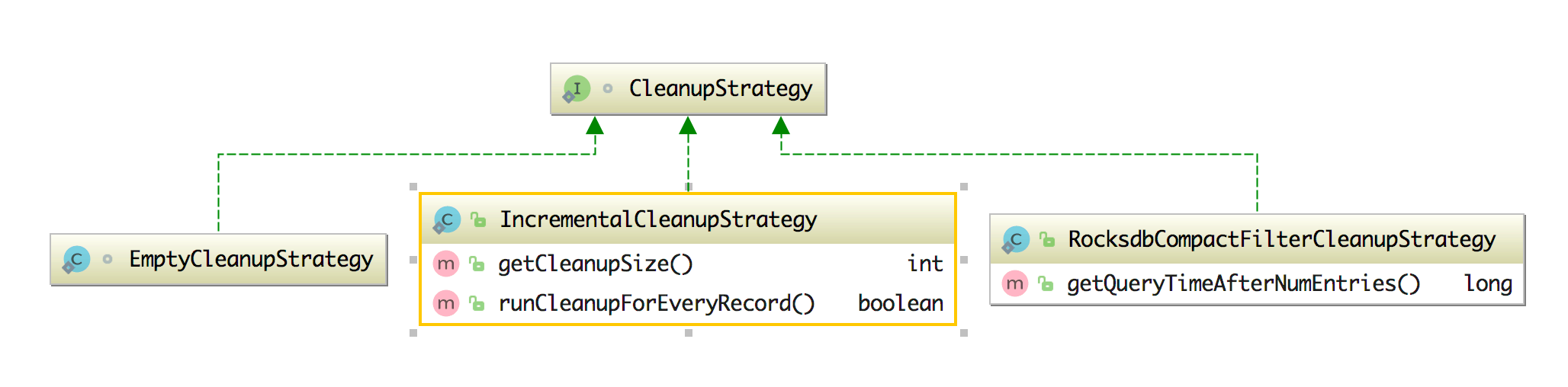
- CleanupStrategies:TTL 清理策略,在该类中有字段 isCleanupInBackground(是否在后台清理) 和相关的清理 strategies(包含 FULL_STATE_SCAN_SNAPSHOT、INCREMENTAL_CLEANUP 和 ROCKSDB_COMPACTION_FILTER),同时该类中还有 CleanupStrategy 接口,它的实现类有 EmptyCleanupStrategy(不清理,为空)、IncrementalCleanupStrategy(增量的清除)、RocksdbCompactFilterCleanupStrategy(在 RocksDB 中自定义压缩过滤器),该类和其实现类如下图所示。
如果对 State TTL 还有不清楚的可以看看 Flink 源码 flink-runtime module 中的 state ttl 相关的实现类,如下图所示:
1.8、如何使用托管的 Operator State
CheckpointedFunction
ListCheckpointed
1.9、Stateful Source Functions
1.10、Broadcast State
1.11、Queryable State
二、Flink 状态后端存储
在生产环境中,随着作业的运行时间变长,状态会变得越来越大,那么如何将这些状态存储也是 Flink 要解决的一大难点,本节来讲解下 Flink 中不同类型的状态后端存储。
2.1、State Backends
当需要对具体的某一种 State 做 Checkpoint 时,此时就需要具体的状态后端存储,刚好 Flink 内置提供了不同的状态后端存储,用于指定状态的存储方式和位置。状态可以存储在 Java 堆内存中或者堆外,在 Flink 安装路径下 conf 目录中的 flink-conf.yaml 配置文件中也有状态后端存储相关的配置,为此在 Flink 源码中还特有一个 CheckpointingOptions 类来控制 state 存储的相关配置,该类中有如下配置:
- state.backend: 用于存储和进行状态 Checkpoint 的状态后端存储方式,无默认值
- state.checkpoints.num-retained: 要保留的已完成 Checkpoint 的最大数量,默认值为 1
- state.backend.async: 状态后端是否使用异步快照方法,默认值为 true
- state.backend.incremental: 状态后端是否创建增量检查点,默认值为 false
- state.backend.local-recovery: 状态后端配置本地恢复,默认情况下,本地恢复被禁用
- taskmanager.state.local.root-dirs: 定义存储本地恢复的基于文件的状态的目录
- state.savepoints.dir: 存储 savepoints 的目录
- state.checkpoints.dir: 存储 Checkpoint 的数据文件和元数据
- state.backend.fs.memory-threshold: 状态数据文件的最小大小,默认值是 1024
虽然配置这么多,但是,Flink 还支持基于每个 Job 单独设置状态后端存储,方法如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new MemoryStateBackend()); //设置堆内存存储
//env.setStateBackend(new FsStateBackend(checkpointDir, asyncCheckpoints)); //设置文件存储
//env.setStateBackend(new RocksDBStateBackend(checkpointDir, incrementalCheckpoints)); //设置 RocksDB 存储
StateBackend 接口的三种实现类如下图所示:
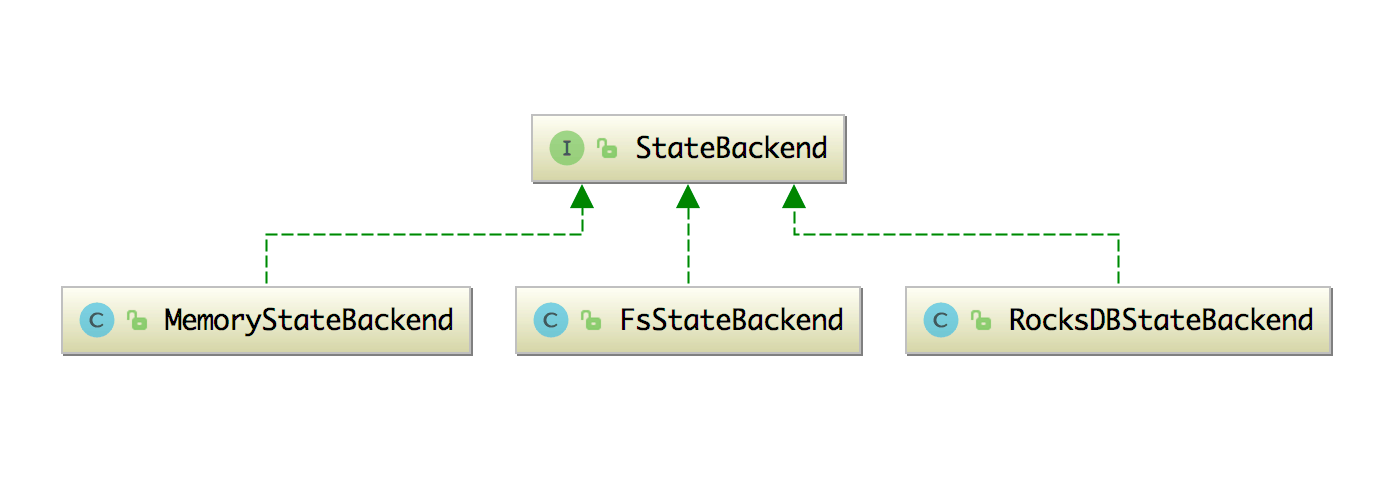
上面三种方式取一种就好了。但是有三种方式,我们该如何去挑选用哪种去存储状态呢?下面讲讲这三种的特点以及该如何选择。
2.2、MemoryStateBackend 的用法及分析
如果 Job 没有配置指定状态后端存储的话,就会默认采取 MemoryStateBackend 策略。如果你细心的话,可以从你的 Job 中看到类似日志如下:
2019-04-28 00:16:41.892 [Sink: zhisheng (1/4)] INFO org.apache.flink.streaming.runtime.tasks.StreamTask - No state backend has been configured, using default (Memory / JobManager) MemoryStateBackend (data in heap memory / checkpoints to JobManager) (checkpoints: 'null', savepoints: 'null', asynchronous: TRUE, maxStateSize: 5242880)
上面日志的意思就是说如果没有配置任何状态存储,使用默认的 MemoryStateBackend 策略,这种状态后端存储把数据以内部对象的形式保存在 TaskManagers 的内存(JVM 堆)中,当应用程序触发 Checkpoint 时,会将此时的状态进行快照然后存储在 JobManager 的内存中。因为状态是存储在内存中的,所以这种情况会有点限制,比如:
- 不太适合在生产环境中使用,仅用于本地测试的情况较多,主要适用于状态很小的 Job,因为它会将状态最终存储在 JobManager 中,如果状态较大的话,那么会使得 JobManager 的内存比较紧张,从而导致 JobManager 会出现 OOM 等问题,然后造成连锁反应使所有的 Job 都挂掉,所以 Job 的状态与之前的 Checkpoint 的数据所占的内存要小于 JobManager 的内存。
- 每个单独的状态大小不能超过最大的 DEFAULT_MAX_STATE_SIZE(5MB),可以通过构造 MemoryStateBackend 参数传入不同大小的 maxStateSize。
- Job 的操作符状态和 keyed 状态加起来都不要超过 RPC 系统的默认配置 10 MB,虽然可以修改该配置,但是不建议去修改。
另外就是 MemoryStateBackend 支持配置是否是异步快照还是同步快照,它有一个字段 asynchronousSnapshots 来表示,可选值有:
- TRUE(表示使用异步的快照,这样可以避免因快照而导致数据流处理出现阻塞等问题)
- FALSE(同步)
- UNDEFINED(默认值)
在构造 MemoryStateBackend 的默认函数时是使用的 UNDEFINED,而不是异步:
public MemoryStateBackend() {
this(null, null, DEFAULT_MAX_STATE_SIZE, TernaryBoolean.UNDEFINED);//使用的是 UNDEFINED
}
网上有人说默认是异步的,这里给大家解释清楚一下,从上面的那条日志打印的确实也是表示异步,但是前提是你对 State 无任何操作,笔者跟了下源码,当你没有配置任何的 state 时,它是会在 StateBackendLoader 类中通过 MemoryStateBackendFactory 来创建的 state 的,如下图所示。

继续跟进 MemoryStateBackendFactory 可以发现他这里创建了一个 MemoryStateBackend 实例并通过 configure 方法进行配置,大概流程代码是:
//MemoryStateBackendFactory 类
public MemoryStateBackend createFromConfig(Configuration config, ClassLoader classLoader) {
return new MemoryStateBackend().configure(config, classLoader);
}
//MemoryStateBackend 类中的 config 方法
public MemoryStateBackend configure(Configuration config, ClassLoader classLoader) {
return new MemoryStateBackend(this, config, classLoader);
}
//私有的构造方法
private MemoryStateBackend(MemoryStateBackend original, Configuration configuration, ClassLoader classLoader) {
...
this.asynchronousSnapshots = original.asynchronousSnapshots.resolveUndefined(
configuration.getBoolean(CheckpointingOptions.ASYNC_SNAPSHOTS));
}
//根据 CheckpointingOptions 类中的 ASYNC_SNAPSHOTS 参数进行设置的
public static final ConfigOption<Boolean> ASYNC_SNAPSHOTS = ConfigOptions
.key("state.backend.async")
.defaultValue(true) //默认值就是 true,代表异步
.withDescription(...)
可以发现最终是通过读取 state.backend.async 参数的默认值(true)来配置是否要异步的进行快照,但是如果你手动配置 MemoryStateBackend 的话,利用无参数的构造方法,那么就不是默认异步,如果想使用异步的话,需要利用下面这个构造函数(需要传入一个 boolean 值,true 代表异步,false 代表同步):
public MemoryStateBackend(boolean asynchronousSnapshots) {
this(null, null, DEFAULT_MAX_STATE_SIZE, TernaryBoolean.fromBoolean(asynchronousSnapshots));
}
如果你再细看了这个 MemoryStateBackend 类的话,那么你可能会发现这个构造函数:
public MemoryStateBackend(@Nullable String checkpointPath, @Nullable String savepointPath) {
this(checkpointPath, savepointPath, DEFAULT_MAX_STATE_SIZE, TernaryBoolean.UNDEFINED);//需要你传入 checkpointPath 和 savepointPath
}
这个也是用来创建一个 MemoryStateBackend 的,它需要传入的参数是两个路径(checkpointPath、savepointPath),其中 checkpointPath 是写入 Checkpoint 元数据的路径,savepointPath 是写入 savepoint 的路径。
这个来看看 MemoryStateBackend 的继承关系图可以更明确的知道它是继承自 AbstractFileStateBackend,然后 AbstractFileStateBackend 这个抽象类就是为了能够将状态存储中的数据或者元数据进行文件存储的,如下图所示。
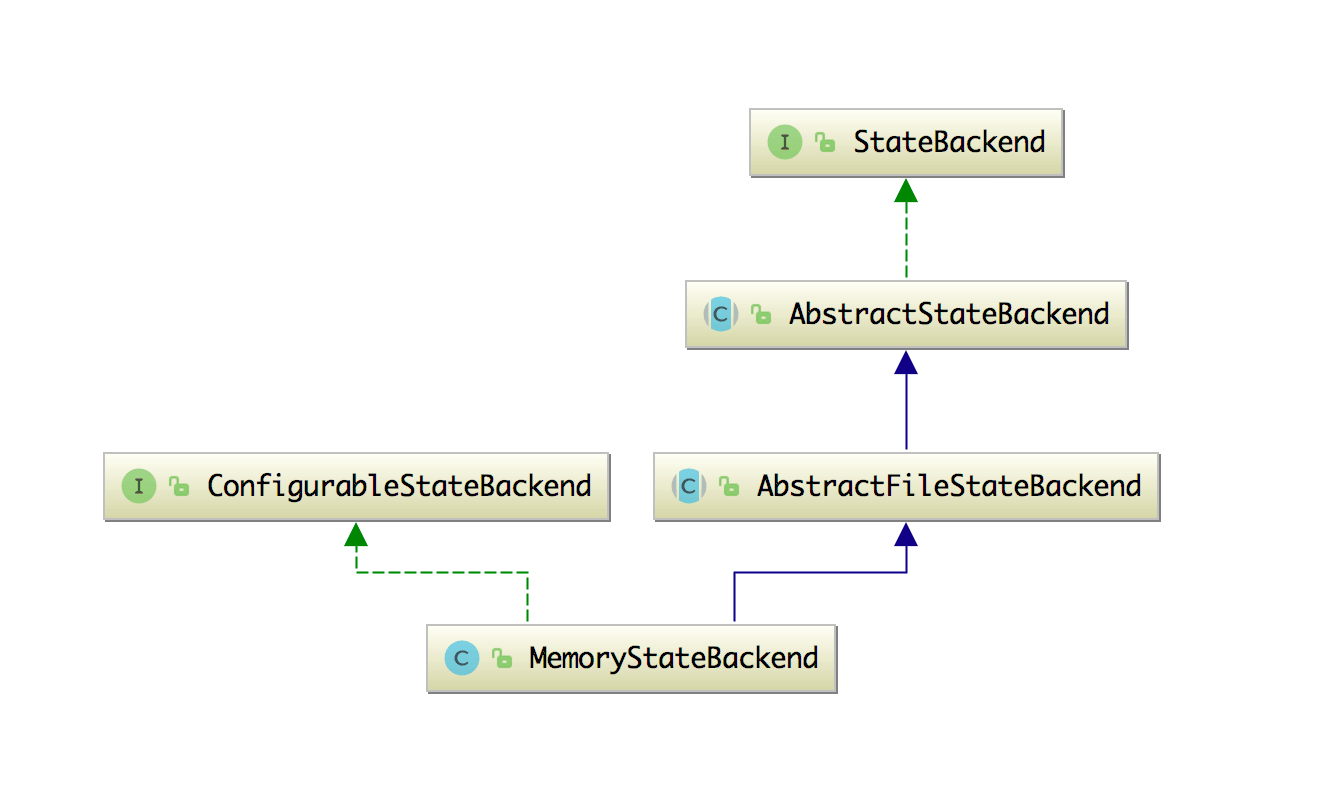
所以 FsStateBackend 和 MemoryStateBackend 都会继承该类。
2.3、FsStateBackend 的用法及分析
这种状态后端存储也是将工作状态存储在 TaskManager 中的内存(JVM 堆)中,但是 Checkpoint 的时候,它和 MemoryStateBackend 不一样,它是将状态存储在文件(可以是本地文件,也可以是 HDFS)中,这个文件具体是哪种需要配置,比如:"hdfs://namenode:40010/flink/checkpoints" 或 "file://flink/checkpoints" (通常使用 HDFS 比较多,如果是使用本地文件,可能会造成 Job 恢复的时候找不到之前的 checkkpoint,因为 Job 重启后如果由调度器重新分配在不同的机器的 TaskManager 执行时就会导致这个问题,所以还是建议使用 HDFS 或者其他的分布式文件系统)。
同样 FsStateBackend 也是支持通过 asynchronousSnapshots 字段来控制是使用异步还是同步来进行 Checkpoint 的,异步可以避免在状态 Checkpoint 时阻塞数据流的处理,然后还有一点的就是在 FsStateBackend 有个参数 fileStateThreshold,如果状态大小比 MAX_FILE_STATE_THRESHOLD(1MB) 小的话,那么会将状态数据直接存储在 meta data 文件中,而不是存储在配置的文件中(避免出现很小的状态文件),如果该值为 "-1" 表示尚未配置,在这种情况下会使用默认值(1024,该默认值可以通过 state.backend.fs.memory-threshold 来配置)。
那么我们该什么时候使用 FsStateBackend 呢?
- 如果你要处理大状态,长窗口等有状态的任务,那么 FsStateBackend 就比较适合。
- 使用分布式文件系统,如 HDFS 等,这样 failover 时 Job 的状态可以恢复。
使用 FsStateBackend 需要注意的地方有什么呢?
- 工作状态仍然是存储在 TaskManager 中的内存中,虽然在 Checkpoint 的时候会存在文件中,所以还是得注意这个状态要保证不超过 TaskManager 的内存。
2.4、RocksDBStateBackend 的用法及分析
2.5、如何选择状态后端存储?
三、Flink Checkpoint 和 Savepoint 的区别及其配置使用
Checkpoint 在 Flink 中是一个非常重要的 Feature,Checkpoint 使 Flink 的状态具有良好的容错性,通过 Checkpoint 机制,Flink 可以对作业的状态和计算位置进行恢复。本节主要讲述在 Flink 中 Checkpoint 和 Savepoint 的使用方式及它们之间的区别。
3.1、Checkpoint 简介及使用
在 Flink 任务运行过程中,为了保障故障容错,Flink 需要对状态进行快照。Flink 可以从 Checkpoint 中恢复流的状态和位置,从而使得应用程序发生故障后能够得到与无故障执行相同的语义。
Flink 的 Checkpoint 有以下先决条件:
- 需要具有持久性且支持重放一定时间范围内数据的数据源。例如:Kafka、RabbitMQ 等。这里为什么要求支持重放一定时间范围内的数据呢?因为 Flink 的容错机制决定了,当 Flink 任务失败后会自动从最近一次成功的 Checkpoint 处恢复任务,此时可能需要把任务失败前消费的部分数据再消费一遍,所以必须要求数据源支持重放。假如一个Flink 任务消费 Kafka 并将数据写入到 MySQL 中,任务从 Kafka 读取到数据,还未将数据输出到 MySQL 时任务突然失败了,此时如果 Kafka 不支持重放,就会造成这部分数据永远丢失了。支持重放数据的数据源可以保障任务消费失败后,能够重新消费来保障任务不丢数据。
- 需要一个能保存状态的持久化存储介质,例如:HDFS、S3 等。当 Flink 任务失败后,自动从 Checkpoint 处恢复,但是如果 Checkpoint 时保存的状态信息快照全丢了,那就会影响 Flink 任务的正常恢复。就好比我们看书时经常使用书签来记录当前看到的页码,当下次看书时找到书签的位置继续阅读即可,但是如果书签三天两头经常丢,那我们就无法通过书签来恢复阅读。
Flink 中 Checkpoint 是默认关闭的,对于需要保障 At Least Once 和 Exactly Once 语义的任务,强烈建议开启 Checkpoint,对于丢一小部分数据不敏感的任务,可以不开启 Checkpoint,例如:一些推荐相关的任务丢一小部分数据并不会影响推荐效果。下面来介绍 Checkpoint 具体如何使用。
首先调用 StreamExecutionEnvironment 的方法 enableCheckpointing(n) 来开启 Checkpoint,参数 n 以毫秒为单位表示 Checkpoint 的时间间隔。Checkpoint 配置相关的 Java 代码如下所示:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutinEnvironment();
// 开启 Checkpoint,每 1000毫秒进行一次 Checkpoint
env.enableCheckpointing(1000);
// Checkpoint 语义设置为 EXACTLY_ONCE
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// CheckPoint 的超时时间
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间,只允许 有 1 个 Checkpoint 在发生
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 两次 Checkpoint 之间的最小时间间隔为 500 毫秒
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// 当 Flink 任务取消时,保留外部保存的 CheckPoint 信息
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 当有较新的 Savepoint 时,作业也会从 Checkpoint 处恢复
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
// 作业最多允许 Checkpoint 失败 1 次(flink 1.9 开始支持)
env.getCheckpointConfig().setTolerableCheckpointFailureNumber(1);
// Checkpoint 失败后,整个 Flink 任务也会失败(flink 1.9 之前)
env.getCheckpointConfig.setFailTasksOnCheckpointingErrors(true)
以上 Checkpoint 相关的参数描述如下所示:
- Checkpoint 语义: EXACTLY_ONCE 或 AT_LEAST_ONCE,EXACTLY_ONCE 表示所有要消费的数据被恰好处理一次,即所有数据既不丢数据也不重复消费;AT_LEAST_ONCE 表示要消费的数据至少处理一次,可能会重复消费。
- Checkpoint 超时时间:如果 Checkpoint 时间超过了设定的超时时间,则 Checkpoint 将会被终止。
- 同时进行的 Checkpoint 数量:默认情况下,当一个 Checkpoint 在进行时,JobManager 将不会触发下一个 Checkpoint,但 Flink 允许多个 Checkpoint 同时在发生。
- 两次 Checkpoint 之间的最小时间间隔:从上一次 Checkpoint 结束到下一次 Checkpoint 开始,中间的间隔时间。例如,env.enableCheckpointing(60000) 表示 1 分钟触发一次 Checkpoint,同时再设置两次 Checkpoint 之间的最小时间间隔为 30 秒,假如任务运行过程中一次 Checkpoint 就用了50s,那么等 Checkpoint 结束后,理论来讲再过 10s 就要开始下一次 Checkpoint 了,但是由于设置了最小时间间隔为30s,所以需要再过 30s 后,下次 Checkpoint 才开始。注:如果配置了该参数就决定了同时进行的 Checkpoint 数量只能为 1。
- 当任务被取消时,外部 Checkpoint 信息是否被清理:Checkpoint 在默认的情况下仅用于恢复运行失败的 Flink 任务,当任务手动取消时 Checkpoint 产生的状态信息并不保留。当然可以通过该配置来保留外部的 Checkpoint 状态信息,这些被保留的状态信息在作业手动取消时不会被清除,这样就可以使用该状态信息来恢复 Flink 任务,对于需要从状态恢复的任务强烈建议配置为外部 Checkpoint 状态信息不清理。可选择的配置项为:
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:当作业手动取消时,保留作业的 Checkpoint 状态信息。注意,这种情况下,需要手动清除该作业保留的 Checkpoint 状态信息,否则这些状态信息将永远保留在外部的持久化存储中。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION:当作业取消时,Checkpoint 状态信息会被删除。仅当作业失败时,作业的 Checkpoint 才会被保留用于任务恢复。
- 任务失败,当有较新的 Savepoint 时,作业是否回退到 Checkpoint 进行恢复:默认情况下,当 Savepoint 比 Checkpoint 较新时,任务会从 Savepoint 处恢复。
- 作业可以容忍 Checkpoint 失败的次数:默认值为 0,表示不能接受 Checkpoint 失败。
3.2、Savepoint 简介及使用
Savepoint 与 Checkpoint 类似,同样需要把状态信息存储到外部介质,当作业失败时,可以从外部存储中恢复。强烈建议在程序中给算子分配 Operator ID,以便来升级程序。主要通过 uid(String) 方法手动指定算子的 ID ,这些 ID 将用于恢复每个算子的状态。
DataStream<String> stream = env.
// Stateful source (e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") // ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.uid("mapper-id") // ID for the mapper
// Stateless printing sink
.print(); // Auto-generated ID
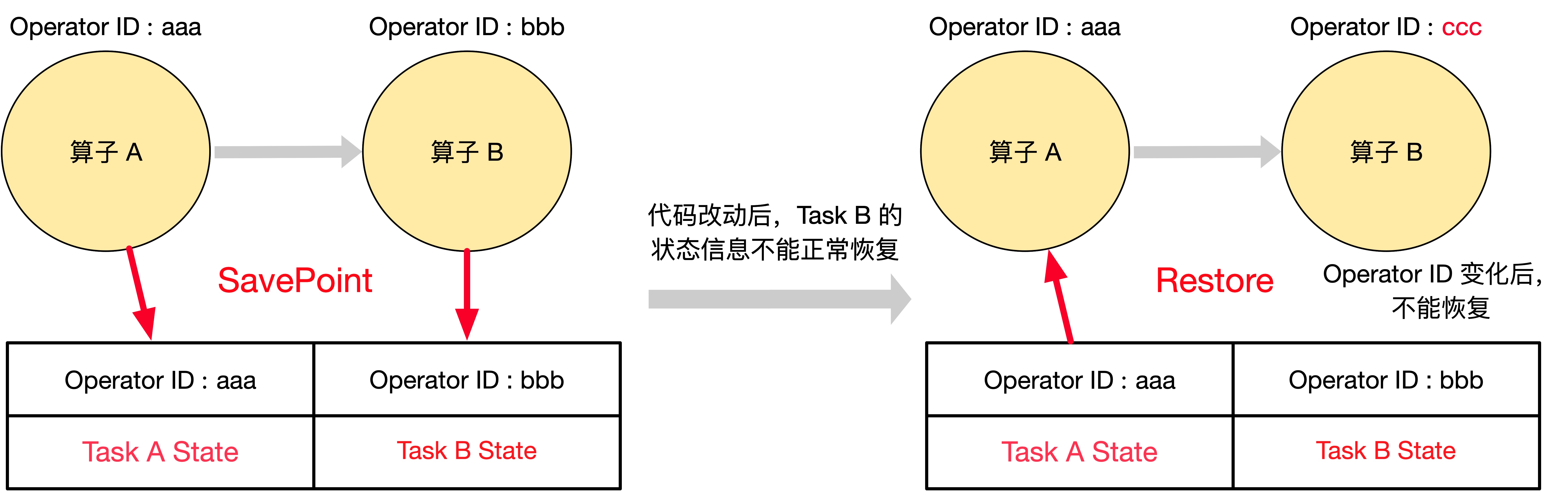
如果不为算子手动指定 ID,Flink 会为算子自动生成 ID。当 Flink 任务从 Savepoint 中恢复时,是按照 Operator ID 将快照信息与算子进行匹配的,只要这些 ID 不变,Flink 任务就可以从 Savepoint 中恢复。自动生成的 ID 取决于代码的结构,并且对代码更改比较敏感,因此强烈建议给程序中所有有状态的算子手动分配 Operator ID。如下图所示,一个 Flink 任务包含了 算子 A 和 算子 B,代码中都未指定 Operator ID,所以 Flink 为 Task A 自动生成了 Operator ID 为 aaa,为 Task B 自动生成了 Operator ID 为 bbb,且 Savepoint 成功完成。但是在代码改动后,任务并不能从 Savepoint 中正常恢复,因为 Flink 为算子生成的 Operator ID 取决于代码结构,代码改动后可能会把算子 B 的 Operator ID 改变成 ccc,导致任务从 Savepoint 恢复时,SavePoint 中只有 Operator ID 为 aaa 和 bbb 的状态信息,算子 B 找不到 Operator ID 为 ccc 的状态信息,所以算子 B 不能正常恢复。这里如果在写代码时通过 uid(String) 手动指定了 Operator ID,就不会存在上述问题了。
Savepoint 需要用户手动去触发,触发 Savepoint 的方式如下所示:
bin/flink savepoint :jobId [:targetDirectory]
这将触发 ID 为 :jobId 的作业进行 Savepoint,并返回创建的 Savepoint 路径,用户需要此路径来还原和删除 Savepoint 。
使用 YARN 触发 Savepoint 的方式如下所示:
bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
这将触发 ID 为 :jobId 和 YARN 应用程序 ID :yarnAppId 的作业进行 Savepoint,并返回创建的 Savepoint 路径。
使用 Savepoint 取消 Flink 任务:
bin/flink cancel -s [:targetDirectory] :jobId
这将自动触发 ID 为 :jobid 的作业进行 Savepoint,并在 Checkpoint 结束后取消该任务。此外,可以指定一个目标文件系统目录来存储 Savepoint 的状态信息,也可以在 flink 的 conf 目录下 flink-conf.yaml 中配置 state.savepoints.dir 参数来指定 Savepoint 的默认目录,触发 Savepoint 时,如果不指定目录则使用该默认目录。无论使用哪种方式配置,都需要保障配置的目录能被所有的 JobManager 和 TaskManager 访问。
3.3、Savepoint 与 Checkpoint 的区别
前面分别介绍了 Savepoint 和 Checkpoint,可以发现它们有不少相似之处,下面来看下它们之间的区别。
| Checkpoint | Savepoint |
| :----------------------------------------------------------: | :----------------------------------------------------------: |
| 由 Flink 的 JobManager 定时自动触发并管理 | 由用户手动触发并管理 |
| 主要用于任务发生故障时,为任务提供给自动恢复机制 | 主要用户升级 Flink 版本、修改任务的逻辑代码、调整算子的并行度,且必须手动恢复 |
| 当使用 RocksDBStateBackend 时,支持增量方式对状态信息进行快照 | 仅支持全量快照 |
| Flink 任务停止后,Checkpoint 的状态快照信息默认被清除 | 一旦触发 Savepoint,状态信息就被持久化到外部存储,除非用户手动删除 |
| Checkpoint 设计目标:轻量级且尽可能快地恢复任务 | Savepoint 的生成和恢复成本会更高一些,Savepoint 更多地关注代码的可移植性和兼容任务的更改操作 |
3.4、Checkpoint 流程
Flink 任务 Checkpoint 的详细流程如下面流程所示。
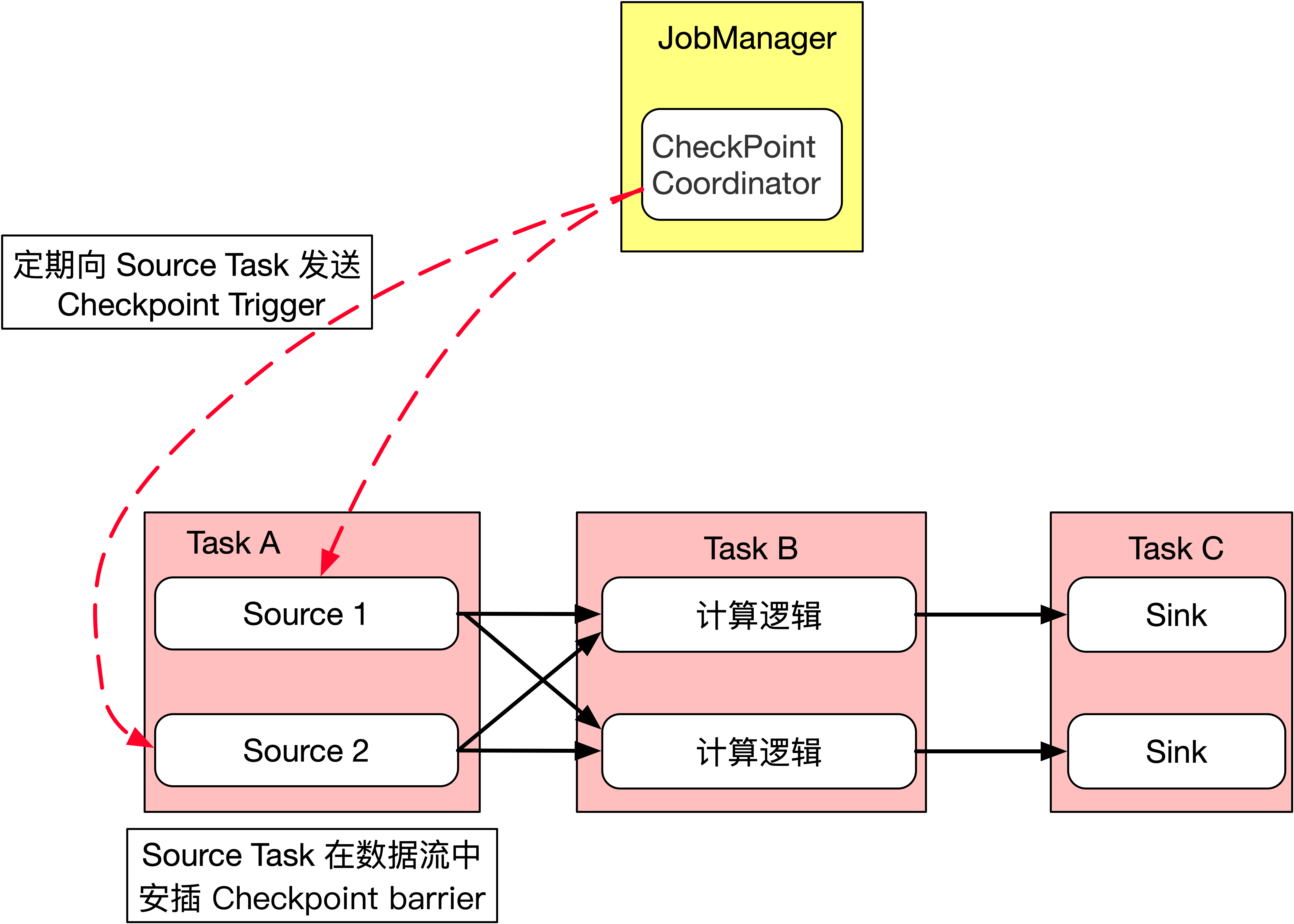
1、JobManager 端的 CheckPointCoordinator 会定期向所有 SourceTask 发送 CheckPointTrigger,Source Task 会在数据流中安插 Checkpoint barrier,如下图所示。
2、当 task 收到上游所有实例的 barrier 后,向自己的下游继续传递 barrier,然后自身同步进行快照,并将自己的状态异步写入到持久化存储中,如下图所示。
- 如果是增量 Checkpoint,则只是把最新的一部分更新写入到外部持久化存储中
- 为了下游尽快进行 Checkpoint,所以 task 会先发送 barrier 到下游,自身再同步进行快照
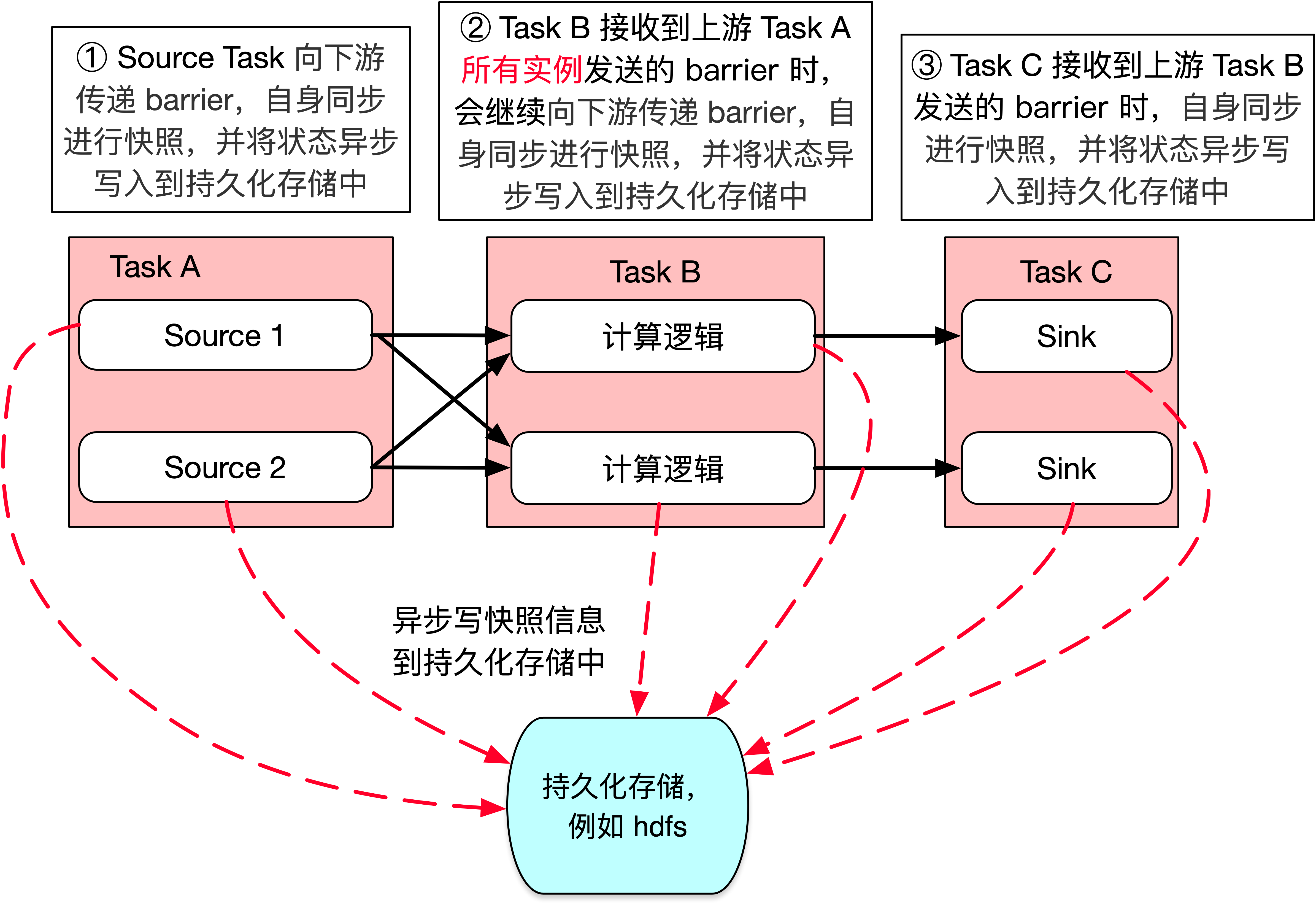
注:Task B 必须接收到上游 Task A 所有实例发送的 barrier 时,Task B 才能开始进行快照,这里有一个 barrier 对齐的概念,关于 barrier 对齐的详细介绍请参阅 9.5.1 节 Flink 内部如何保证 Exactly Once 中的 barrier 对齐部分
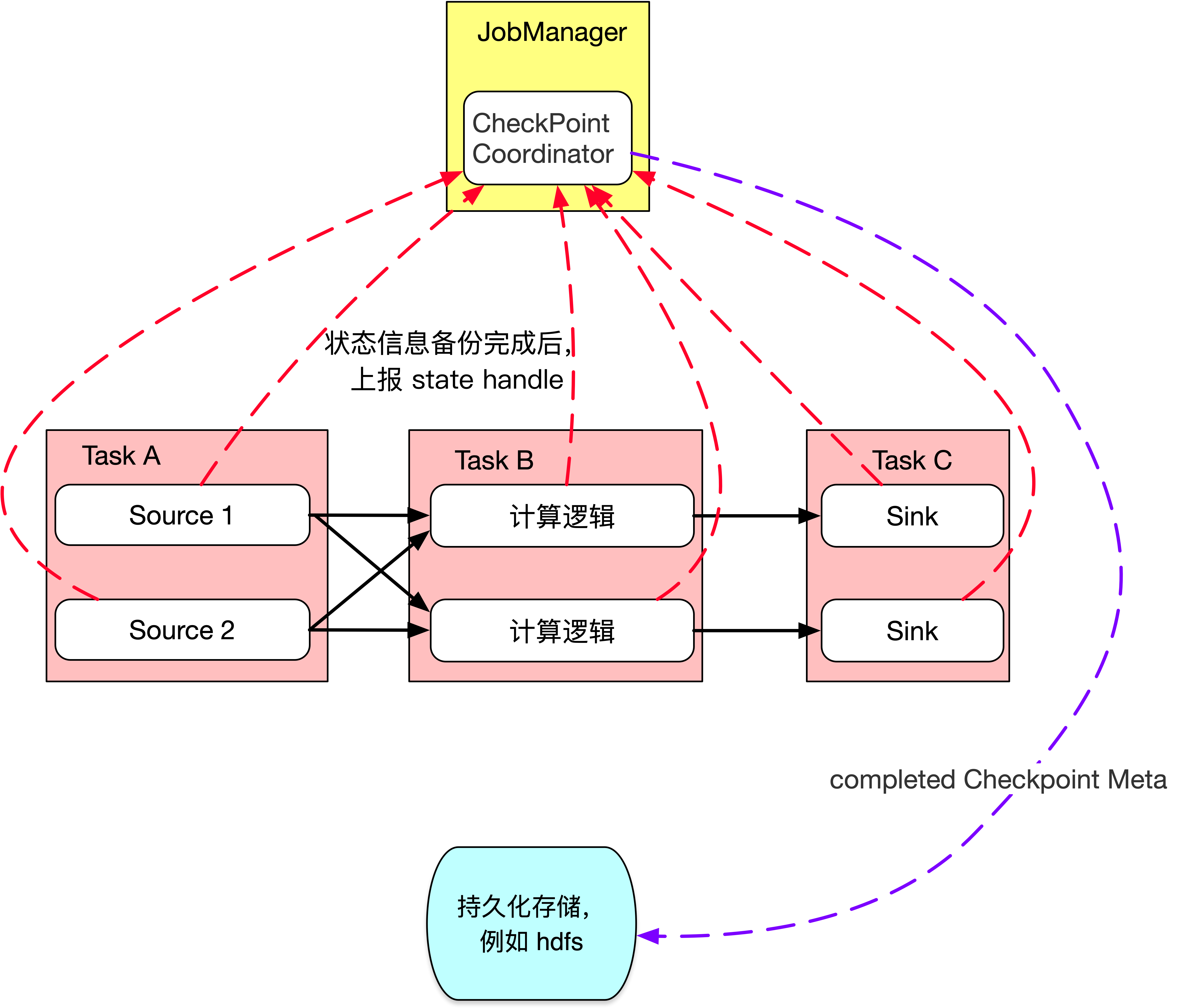
3、当 task 将状态信息完成备份后,会将备份数据的地址(state handle)通知给 JobManager 的CheckPointCoordinator,如果 Checkpoint 的持续时长超过了 Checkpoint 设定的超时时间CheckPointCoordinator 还没有收集完所有的 State Handle,CheckPointCoordinator 就会认为本次 Checkpoint 失败,会把这次 Checkpoint 产生的所有状态数据全部删除。
4、如果 CheckPointCoordinator 收集完所有算子的 State Handle,CheckPointCoordinator 会把整个 StateHandle 封装成 completed Checkpoint Meta,写入到外部存储中,Checkpoint 结束,如下图所示。
基于 RocksDB 的增量 Checkpoint 实现原理
当使用 RocksDBStateBackend 时,增量 Checkpoint 是如何实现的呢?RocksDB 是一个基于 LSM 实现的 KV 数据库。LSM 全称 Log Structured Merge Trees,LSM 树本质是将大量的磁盘随机写操作转换成磁盘的批量写操作来极大地提升磁盘数据写入效率。一般 LSM Tree 实现上都会有一个基于内存的 MemTable 介质,所有的增删改操作都是写入到 MemTable 中,当 MemTable 足够大以后,将 MemTable 中的数据 flush 到磁盘中生成不可变且内部有序的 ssTable(Sorted String Table)文件,全量数据保存在磁盘的多个 ssTable 文件中。HBase 也是基于 LSM Tree 实现的,HBase 磁盘上的 HFile 就相当于这里的 ssTable 文件,每次生成的 HFile 都是不可变的而且内部有序的文件。基于 ssTable 不可变的特性,才实现了增量 Checkpoint,具体流程如下图所示。
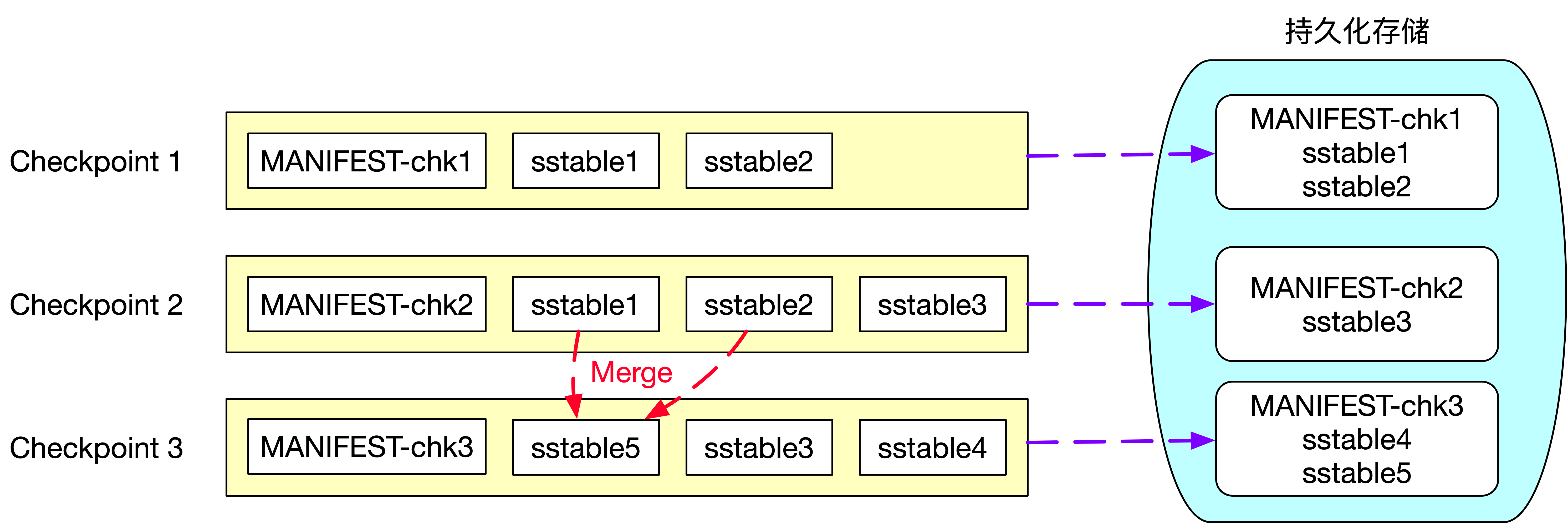
第一次 Checkpoint 时生成的状态快照信息包含了两个 sstable 文件:sstable1 和 sstable2 及 Checkpoint1 的元数据文件 MANIFEST-chk1,所以第一次 Checkpoint 时需要将 sstable1、sstable2 和 MANIFEST-chk1 上传到外部持久化存储中。第二次 Checkpoint 时生成的快照信息为 sstable1、sstable2、sstable3 及元数据文件 MANIFEST-chk2,由于 sstable 文件的不可变特性,所以状态快照信息的 sstable1、sstable2 这两个文件并没有发生变化,sstable1、sstable2 这两个文件不需要重复上传到外部持久化存储中,因此第二次 Checkpoint 时,只需要将 sstable3 和 MANIFEST-chk2 文件上传到外部持久化存储中即可。这里只将新增的文件上传到外部持久化存储,也就是所谓的增量 Checkpoint。
基于 LSM Tree 实现的数据库为了提高查询效率,都需要定期对磁盘上多个 sstable 文件进行合并操作,合并时会将删除的、过期的以及旧版本的数据进行清理,从而降低 sstable 文件的总大小。图中可以看到第三次 Checkpoint 时生成的快照信息为sstable3、sstable4、sstable5 及元数据文件 MANIFEST-chk3, 其中新增了 sstable4 文件且 sstable1 和 sstable2 文件合并成 sstable5 文件,因此第三次 Checkpoint 时只需要向外部持久化存储上传 sstable4、sstable5 及元数据文件 MANIFEST-chk3。
基于 RocksDB 的增量 Checkpoint 从本质上来讲每次 Checkpoint 时只将本次 Checkpoint 新增的快照信息上传到外部的持久化存储中,依靠的是 LSM Tree 中 sstable 文件不可变的特性。对 LSM Tree 感兴趣的可以深入研究 RocksDB 或 HBase 相关原理及实现。
评论