
一、Flink
1.1、简介
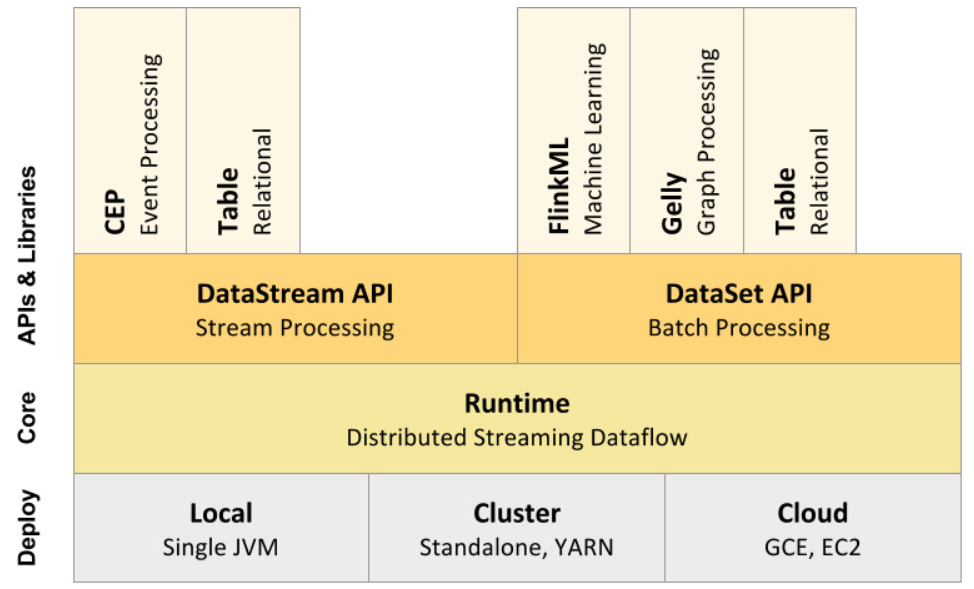
Flink 是一个针对流数据和批数据的分布式处理引擎,代码主要是由 Java 实现,部分代码是 Scala。它可以处理有界的批量数据集、也可以处理无界的实时数据集,总结如下图所示。对 Flink 而言,其所要处理的主要场景就是流数据,批数据只是流数据的一个极限特例而已,所以 Flink 也是一款真正的流批统一的计算引擎。Flink 提供了 State、Checkpoint、Time、Window 等,它们为 Flink 提供了基石。

1.2、整体架构
Flink 整体架构从下至上分为:
1、部署:Flink 支持本地运行(IDE 中直接运行程序)、能在独立集群(Standalone 模式)或者在被 YARN、Mesos、K8s 管理的集群上运行,也能部署在云上。
2、运行:Flink 的核心是分布式流式数据引擎,意味着数据以一次一个事件的形式被处理。
3、API:DataStream、DataSet、Table API & SQL。
4、扩展库:Flink 还包括用于 CEP(复杂事件处理)、机器学习、图形处理等场景。
整体架构如下图所示:
1.3、多种方式部署
作为一个计算引擎,如果要做的足够完善,除了它自身的各种特点要包含,还得支持各种生态圈,比如部署的情况,Flink 是支持以 Standalone、YARN、Kubernetes、Mesos 等形式部署的,如下图所示。
每种部署方式介绍如下:
- Local:直接在 IDE 中运行 Flink Job 时则会在本地启动一个 mini Flink 集群。
- Standalone:在 Flink 目录下执行
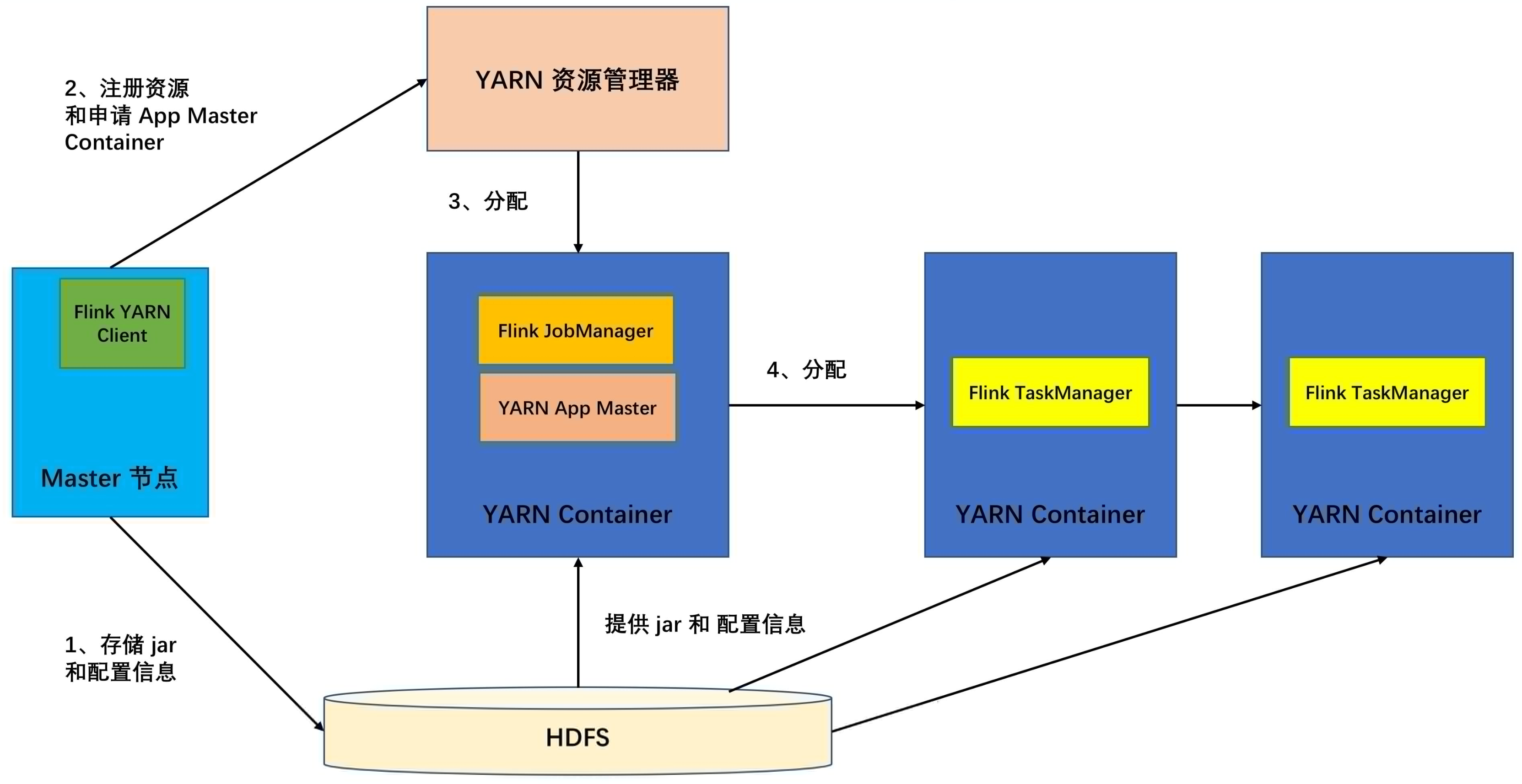
bin/start-cluster.sh脚本则会启动一个 Standalone 模式的集群。 - YARN:YARN 是 Hadoop 集群的资源管理系统,它可以在群集上运行各种分布式应用程序,Flink 可与其他应用并行于 YARN 中,Flink on YARN 的架构如下图所示。
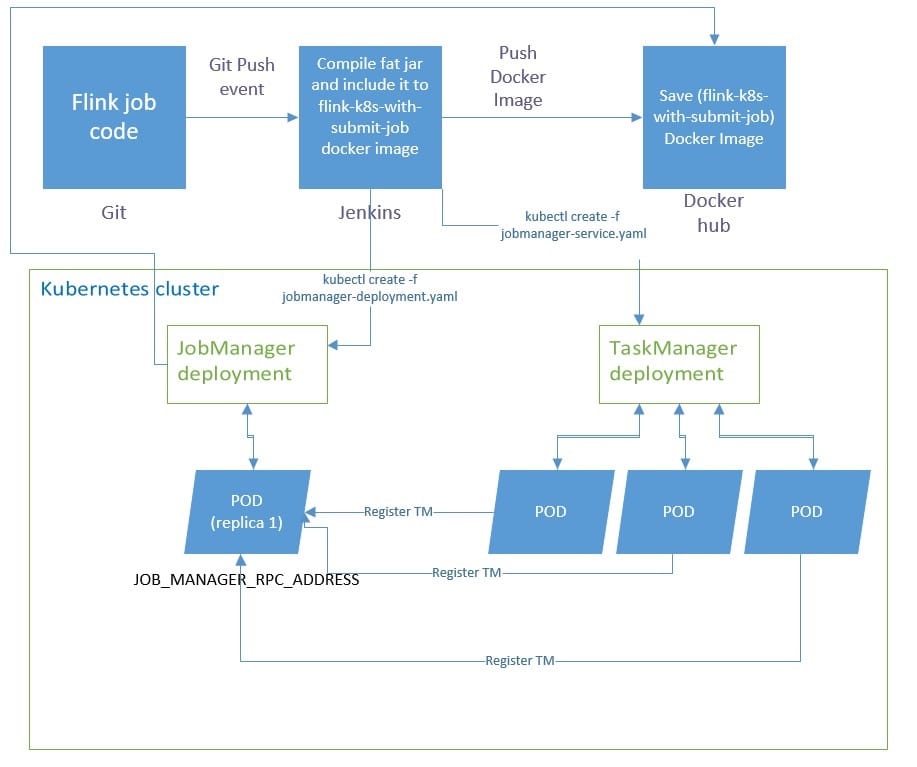
- Kubernetes:Kubernetes 是 Google 开源的容器集群管理系统,在 Docker 技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性,Flink 也支持部署在 Kubernetes 上,在 GitHub 看到有下面这种运行架构的。
通常上面四种居多,另外还支持 AWS、MapR、Aliyun OSS 等。
{kind=link}
1.4、分布式运行流程
Flink 作业提交架构流程如下图所示:
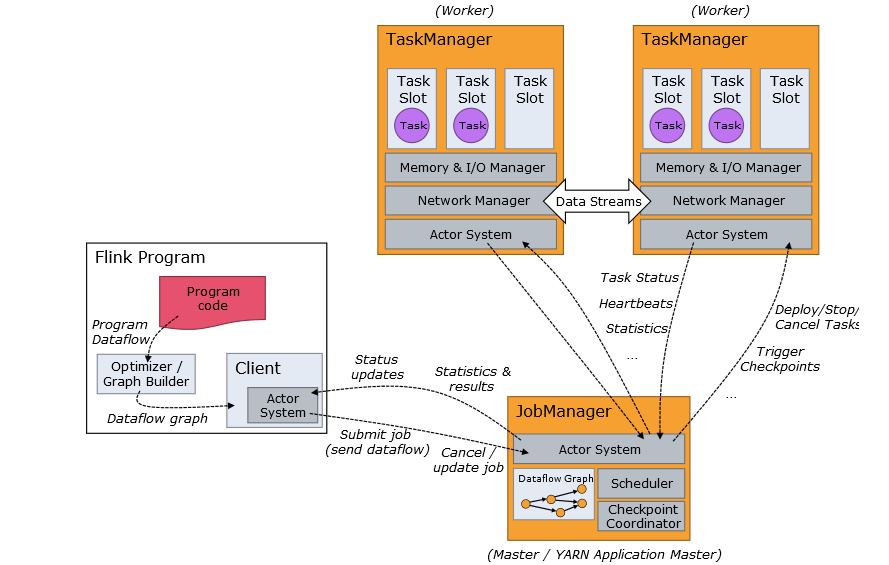
具体流程介绍如下:
1、Program Code:编写的 Flink 应用程序代码。
2、Job Client:Job Client 不是 Flink 程序执行的内部部分,但它是任务执行的起点。 Job Client 负责接受用户的程序代码,然后创建数据流,将数据流提交给 JobManager 以便进一步执行。 执行完成后,Job Client 将结果返回给用户。
3、JobManager:主进程(也称为作业管理器)协调和管理程序的执行。 它的主要职责包括安排任务,管理 Checkpoint ,故障恢复等。机器集群中至少要有一个 master,master 负责调度 task,协调 Checkpoints 和容灾,高可用设置的话可以有多个 master,但要保证一个是 leader, 其他是 standby; JobManager 包含 Actor system、Scheduler、Check pointing 三个重要的组件。
4、TaskManager:从 JobManager 处接收需要部署的 Task。TaskManager 是在 JVM 中的一个或多个线程中执行任务的工作节点。 任务执行的并行性由每个 TaskManager 上可用的任务槽(Slot 个数)决定。 每个任务代表分配给任务槽的一组资源。 例如,如果 TaskManager 有四个插槽,那么它将为每个插槽分配 25% 的内存。 可以在任务槽中运行一个或多个线程。 同一插槽中的线程共享相同的 JVM。
同一 JVM 中的任务共享 TCP 连接和心跳消息。TaskManager 的一个 Slot 代表一个可用线程,该线程具有固定的内存,注意 Slot 只对内存隔离,没有对 CPU 隔离。默认情况下,Flink 允许子任务共享 Slot,即使它们是不同 task 的 subtask,只要它们来自相同的 job。这种共享可以有更好的资源利用率。
1.5、API
Flink 提供了不同的抽象级别的 API 以开发流式或批处理应用,如下图所示。

这四种API功能分别是:
- 最底层提供了有状态流。它将通过 Process Function 嵌入到 DataStream API 中。它允许用户可以自由地处理来自一个或多个流数据的事件,并使用一致性、容错的状态。除此之外,用户可以注册事件时间和处理事件回调,从而使程序可以实现复杂的计算。
- DataStream / DataSet API 是 Flink 提供的核心 API ,DataSet 处理有界的数据集,DataStream 处理有界或者无界的数据流。用户可以通过各种方法(map / flatmap / window / keyby / sum / max / min / avg / join 等)将数据进行转换或者计算。
- Table API 是以表为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作,使用起来却更加简洁(代码量更少)。你可以在表与 DataStream/DataSet 之间无缝切换,也允许程序将 Table API 与 DataStream 以及 DataSet 混合使用。
- Flink 提供的最高层级的抽象是 SQL 。这一层抽象在语法与表达能力上与 Table API 类似,但是是以 SQL查询表达式的形式表现程序。SQL 抽象与 Table API 交互密切,同时 SQL 查询可以直接在 Table API 定义的表上执行。
Flink 除了 DataStream 和 DataSet API,它还支持 Table API & SQL,Flink 也将通过 SQL 来构建统一的大数据流批处理引擎,因为在公司中通常会有那种每天定时生成报表的需求(批处理的场景,每晚定时跑一遍昨天的数据生成一个结果报表),但是也是会有流处理的场景(比如采用 Flink 来做实时性要求很高的需求),于是慢慢的整个公司的技术选型就变得越来越多了,这样开发人员也就要面临着学习两套不一样的技术框架,运维人员也需要对两种不一样的框架进行环境搭建和作业部署,平时还要维护作业的稳定性。当我们的系统变得越来越复杂了,作业越来越多了,这对于开发人员和运维来说简直就是噩梦,没准哪天凌晨晚上就被生产环境的告警电话给叫醒。所以 Flink 系统能通过 SQL API 来解决批流统一的痛点,这样不管是开发还是运维,他们只需要关注一个计算框架就行,从而减少企业的用人成本和后期开发运维成本。
1.6、程序与数据流结构

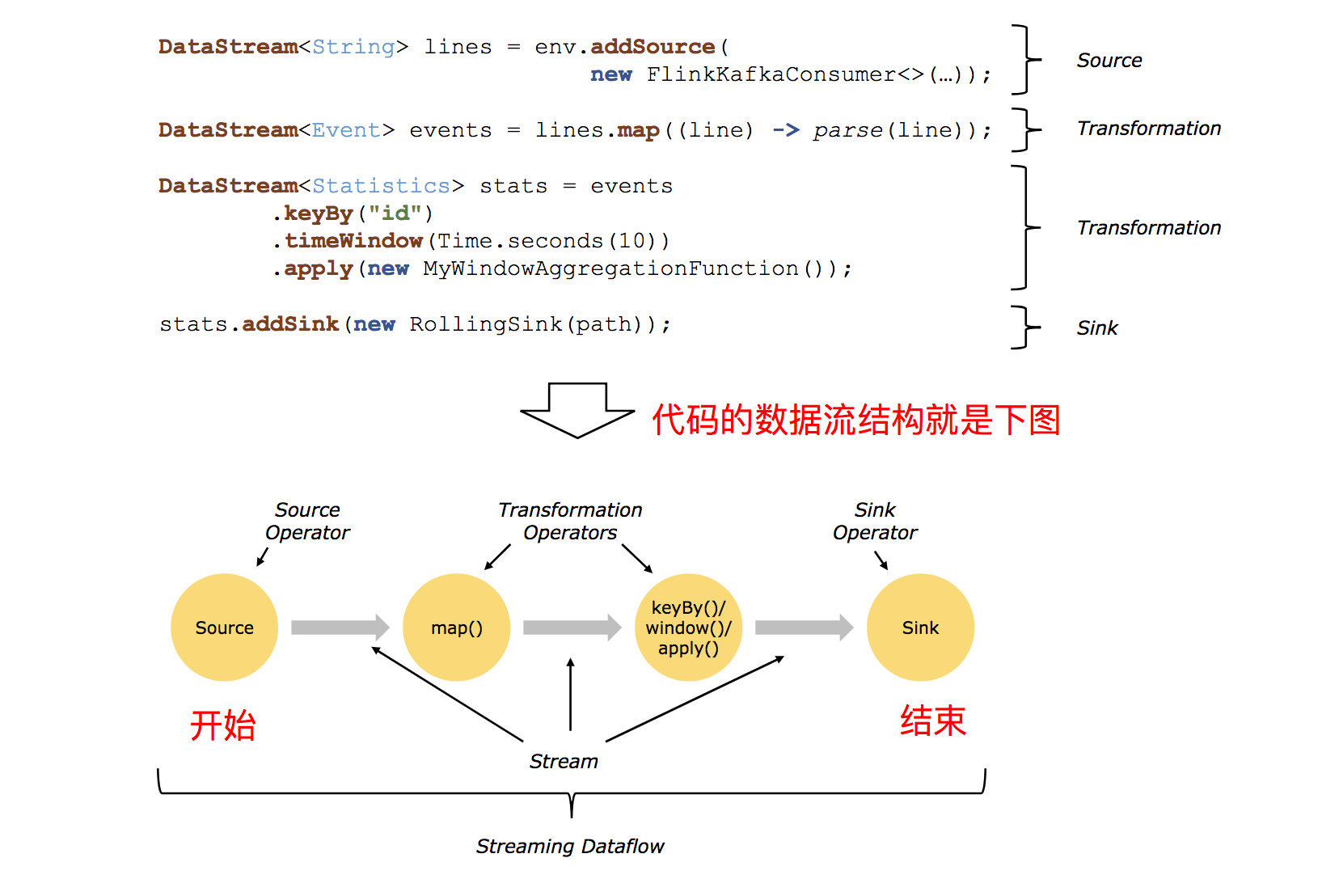
它们的功能分别是:
- Source:数据输入,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
- Transformation:数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
- Sink:数据输出,Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来,Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 socket 、自定义的 sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 sink。
代码结构如下图所示:
1.7、丰富的 Connector
通过源码可以发现不同版本的 Kafka、不同版本的 ElasticSearch、Cassandra、HBase、Hive、HDFS、RabbitMQ 都是支持的,除了流应用的 Connector 是支持的,另外还支持 SQL,如下图所示。
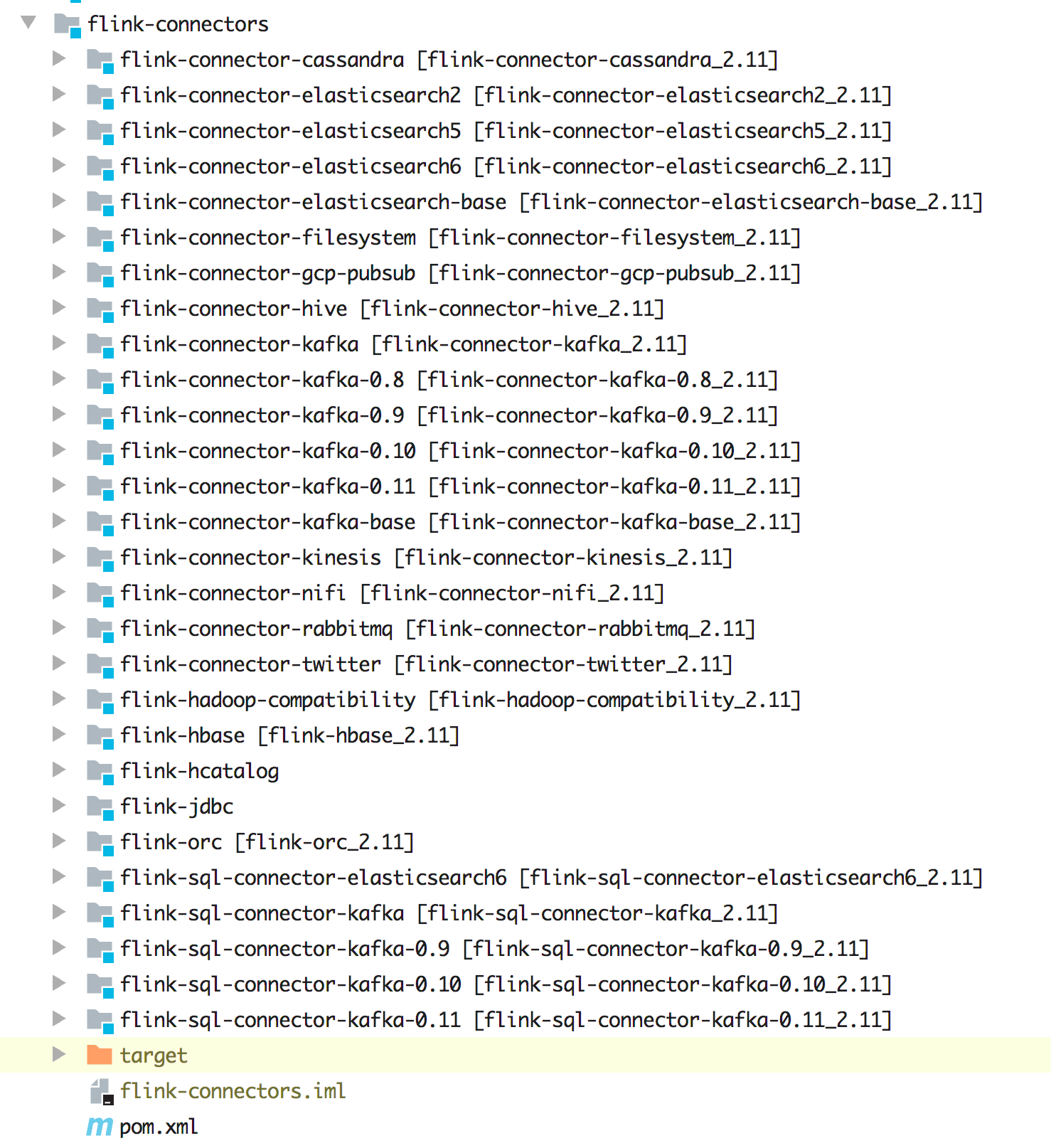
再就是要考虑计算的数据来源和数据最终存储,因为 Flink 在大数据领域的的定位就是实时计算,它不做存储(虽然 Flink 中也有 State 去存储状态数据,这里说的存储类似于 MySQL、ElasticSearch 等存储),所以在计算的时候其实你需要考虑的是数据源来自哪里,计算后的结果又存储到哪里去。庆幸的是 Flink 目前已经支持大部分常用的组件了,比如在 Flink 中已经支持了如下这些 Connector:
- 不同版本的 Kafka
- 不同版本的 ElasticSearch
- Redis
- MySQL
- Cassandra
- RabbitMQ
- HBase
- HDFS
- ...
这些 Connector 除了支持流作业外,目前还有还有支持 SQL 作业的,除了这些自带的 Connector 外,还可以通过 Flink 提供的接口做自定义 Source 和 Sink。
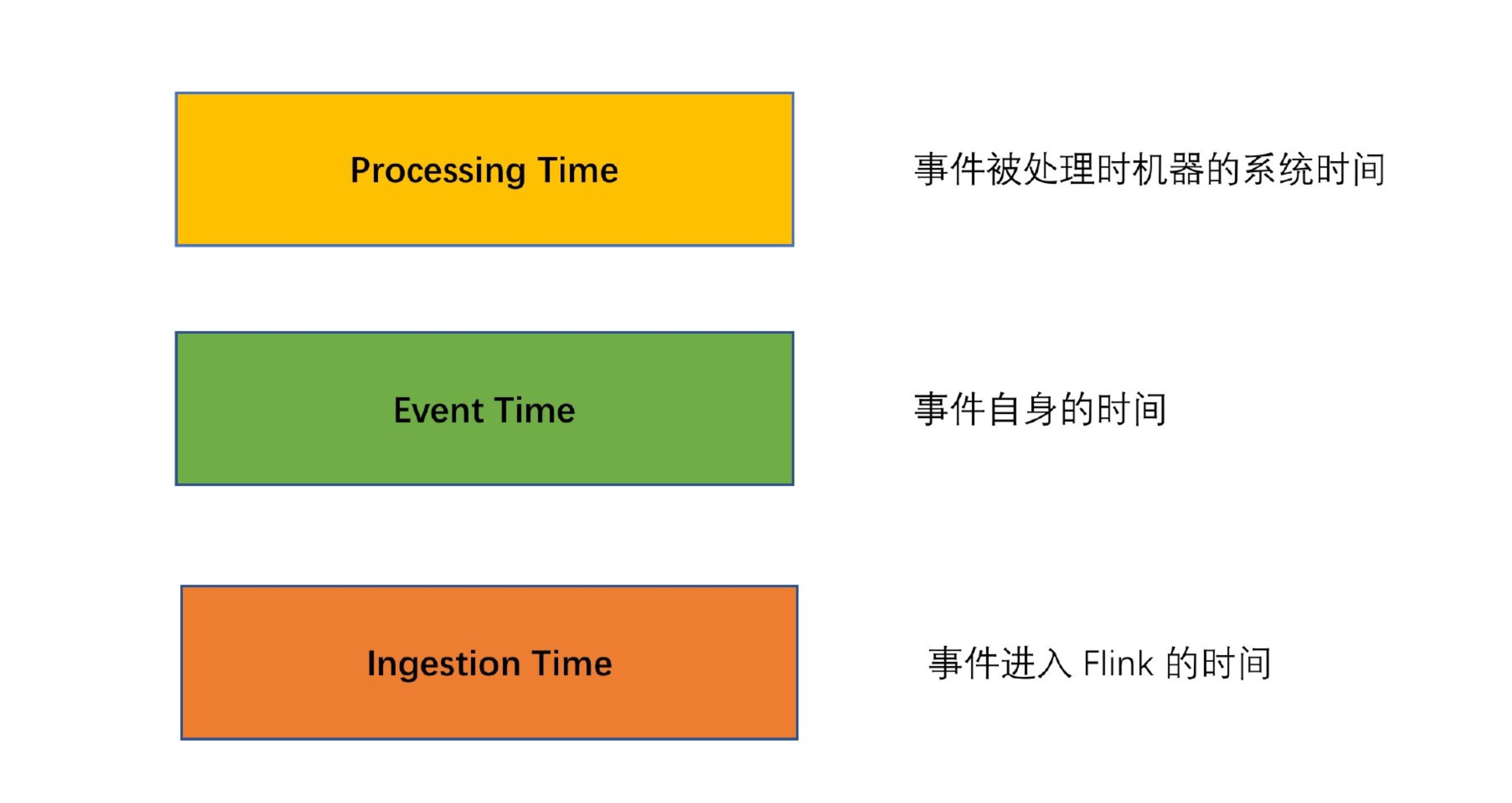
1.8、事件时间&处理时间语义
Flink 支持多种 Time,比如 Event time、Ingestion Time、Processing Time。
1.9、灵活的窗口机制
Flink 支持多种 Window,比如 Time Window、Count Window、Session Window,还支持自定义 Window。
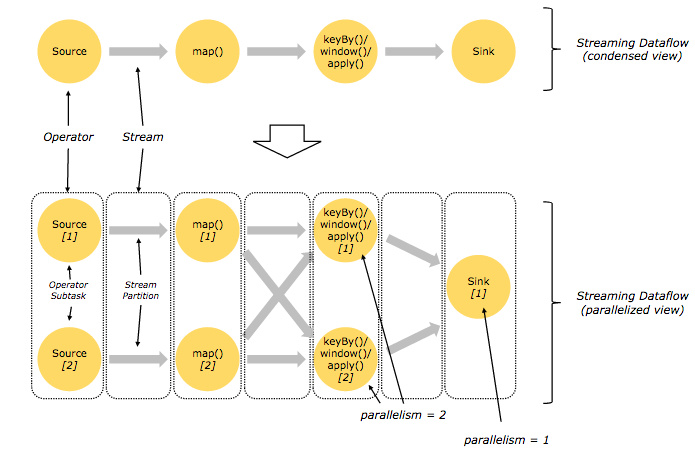
1.10、并行执行任务机制
Flink 的程序内在是并行和分布式的,数据流可以被分区成 stream partitions,operators 被划分为 operator subtasks; 这些 subtasks 在不同的机器或容器中分不同的线程独立运行;operator subtasks 的数量在具体的 operator 就是并行计算数,程序不同的 operator 阶段可能有不同的并行数;如下图所示,source operator 的并行数为 2,但最后的 sink operator 为 1:
1.11、状态存储和容错
Flink 是一款有状态的流处理框架,它提供了丰富的状态访问接口,按照数据的划分方式,可以分为 Keyed State 和 Operator State,在 Keyed State 中又提供了多种数据结构:
- ValueState
- MapState
- ListState
- ReducingState
- AggregatingState
另外状态存储也支持多种方式:
- MemoryStateBackend:存储在内存中
- FsStateBackend:存储在文件中
- RocksDBStateBackend:存储在 RocksDB 中
Flink 中支持使用 Checkpoint 来提高程序的可靠性,开启了 Checkpoint 之后,Flink 会按照一定的时间间隔对程序的运行状态进行备份,当发生故障时,Flink 会将所有任务的状态恢复至最后一次发生 Checkpoint 中的状态,并从那里开始重新开始执行。另外 Flink 还支持根据 Savepoint 从已停止作业的运行状态进行恢复,这种方式需要通过命令进行触发。
1.12、自己的内存管理机制
Flink 并不是直接把对象存放在堆内存上,而是将对象序列化为固定数量的预先分配的内存段。它采用类似 DBMS 的排序和连接算法,可以直接操作二进制数据,以此将序列化和反序列化开销降到最低。如果需要处理的数据容量超过内存,那么 Flink 的运算符会将部分数据存储到磁盘。Flink 的主动内存管理和操作二进制数据有几个好处:
- 保证内存可控,可以防止 OutOfMemoryError
- 减少垃圾收集压力
- 节省数据的存储空间
- 高效的二进制操作
1.13、多种扩展库
Flink 扩展库中含有机器学习、Gelly 图形处理、CEP 复杂事件处理、State Processing API 等,这些扩展库在一些特殊场景下会比较适用。
二、大数据计算框架对比
即Blink、Spark Streaming、Structured Streaming 和 Storm 的区别。
2.1、Flink
Flink 是一个针对流数据和批数据分布式处理的引擎,在某些对实时性要求非常高的场景,基本上都是采用 Flink 来作为计算引擎,它不仅可以处理有界的批数据,还可以处理无界的流数据,在 Flink 的设计愿想就是将批处理当成是流处理的一种特例。
而 Blink 一个很强大的特点就是它的 Table API & SQL 很强大,社区也在 Flink 1.9 版本将 Blink 开源版本大部分代码合进了 Flink 主分支。
2.2、Blink
Blink 是早期阿里在 Flink 的基础上开始修改和完善后在内部创建的分支,然后 Blink 目前在阿里服务于阿里集团内部搜索、推荐、广告、菜鸟物流等大量核心实时业务,如下图所示。

Blink 在阿里内部错综复杂的业务场景中锻炼成长着,经历了内部这么多用户的反馈(各种性能、资源使用率、易用性等诸多方面的问题),Blink 都做了针对性的改进。在 Flink Forward China 峰会上,阿里巴巴集团副总裁周靖人宣布 Blink 在 2019 年 1 月正式开源,同时阿里也希望 Blink 开源后能进一步加深与 Flink 社区的联动,
Blink 开源地址:https://github.com/apache/flink/tree/blink
开源版本 Blink 的主要功能和优化点:
1、Runtime 层引入 Pluggable Shuffle Architecture,开发者可以根据不同的计算模型或者新硬件的需要实现不同的 shuffle 策略进行适配;为了性能优化,Blink 可以让算子更加灵活的 chain 在一起,避免了不必要的数据传输开销;在 BroadCast Shuffle 模式中,Blink 优化掉了大量的不必要的序列化和反序列化开销;Blink 提供了全新的 JM FailOver 机制,JM 发生错误之后,新的 JM 会重新接管整个 JOB 而不是重启 JOB,从而大大减少了 JM FailOver 对 JOB 的影响;Blink 支持运行在 Kubernetes 上。
2、SQL/Table API 架构上的重构和性能的优化是 Blink 开源版本的一个重大贡献。
3、Hive 的兼容性,可以直接用 Flink SQL 去查询 Hive 的数据,Blink 重构了 Flink catalog 的实现,并且增加了两种 catalog,一个是基于内存存储的 FlinkInMemoryCatalog,另外一个是能够桥接 Hive metaStore 的 HiveCatalog。
4、Zeppelin for Flink
5、Flink Web,更美观的 UI 界面,查看日志和监控 Job 都变得更加方便。
2.3、Spark
Apache Spark 是一种包含流处理能力的下一代批处理框架。与 Hadoop 的 MapReduce 引擎基于各种相同原则开发而来的 Spark 主要侧重于通过完善的内存计算和处理优化机制加快批处理工作负载的运行速度。Spark 可作为独立集群部署(需要相应存储层的配合),或可与 Hadoop 集成并取代 MapReduce 引擎。
Spark Streaming 是 Spark API 核心的扩展,可实现实时数据的快速扩展,高吞吐量,容错处理。数据可以从很多来源(如 Kafka、Flume、Kinesis 等)中提取,并且可以通过很多函数来处理这些数据,处理完后的数据可以直接存入数据库或者 Dashboard 等,如下两图所示。
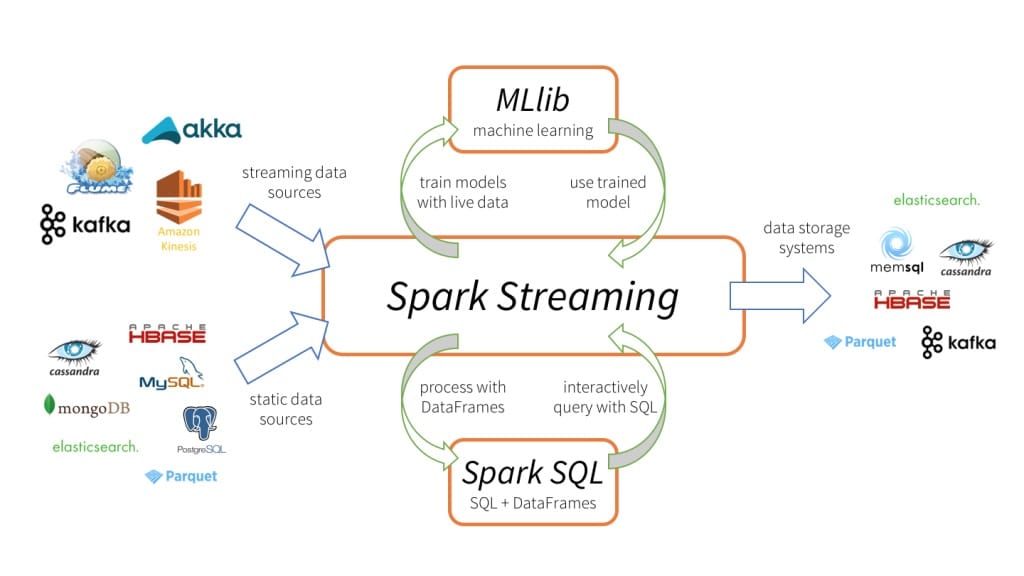
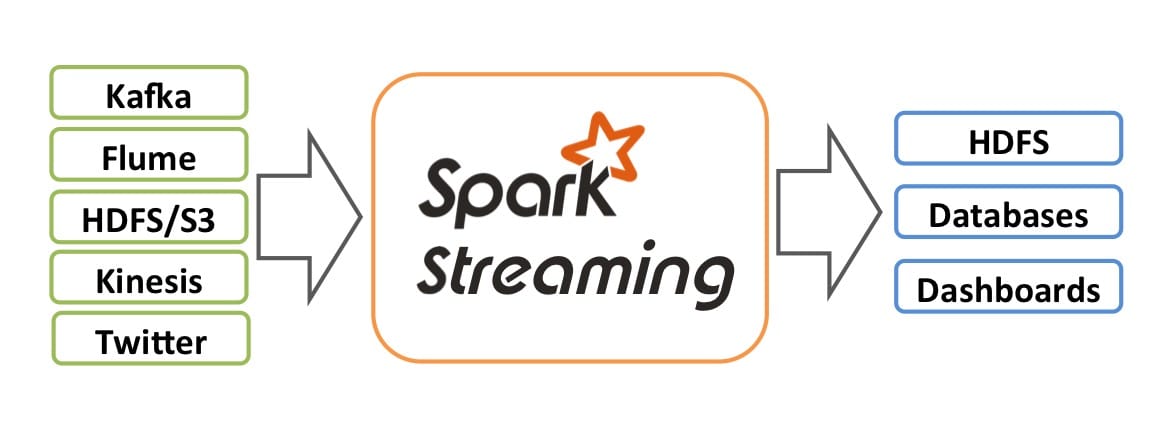
Spark Streaming 的内部实现原理是接收实时输入数据流并将数据分成批处理,然后由 Spark 引擎处理以批量生成最终结果流,也就是常说的 micro-batch 模式,如下图所示。
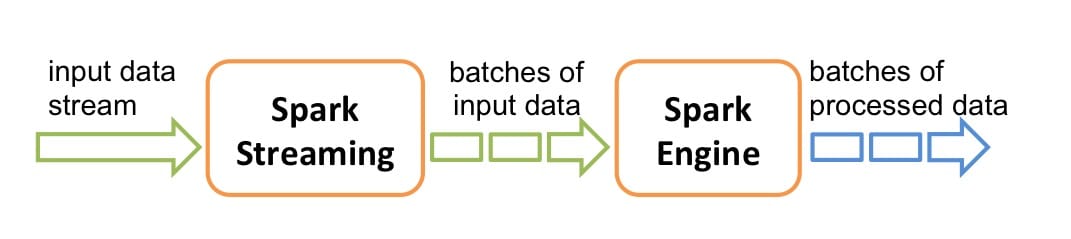
Spark DStreams
DStreams 是 Spark Streaming 提供的基本的抽象,它代表一个连续的数据流。它要么是从源中获取的输入流,要么是输入流通过转换算子生成的处理后的数据流。在内部实现上,DStream 由连续的序列化 RDD 来表示,每个 RDD 含有一段时间间隔内的数据,如下图所示:
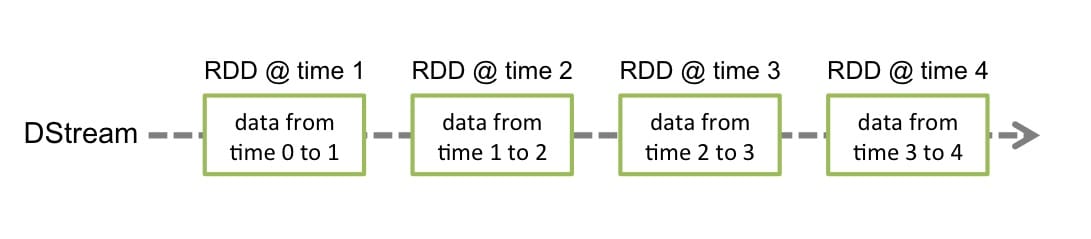
任何对 DStreams 的操作都转换成了对 DStreams 隐含的 RDD 的操作。例如 flatMap 操作应用于 lines 这个 DStreams 的每个 RDD,生成 words 这个 DStreams 的 RDD 过程如下图所示:
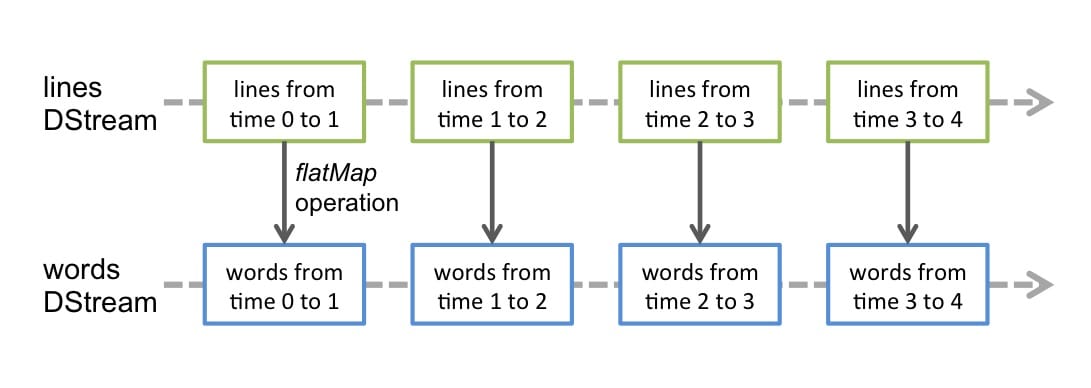
通过 Spark 引擎计算这些隐含 RDD 的转换算子。DStreams 操作隐藏了大部分的细节,并且为了更便捷,为开发者提供了更高层的 API。
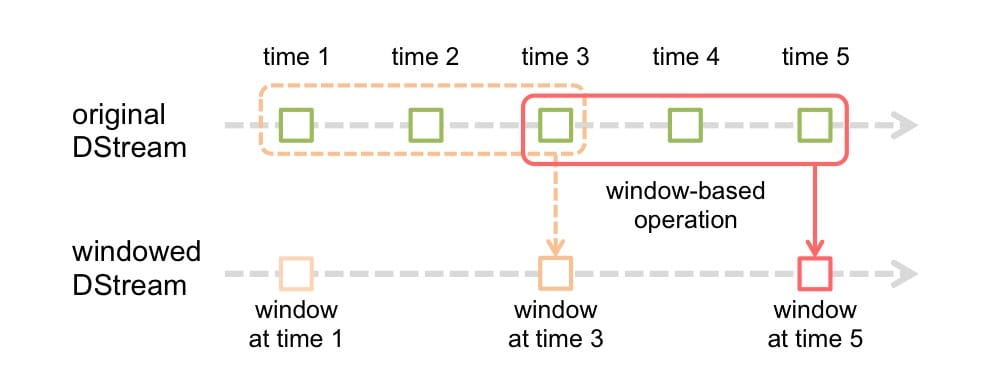
Spark 支持的滑动窗口
它和 Flink 的滑动窗口类似,支持传入两个参数,一个代表窗口长度,一个代表滑动间隔,如下图所示。
Spark 支持更多的 API
因为 Spark 是使用 Scala 开发的居多,所以从官方文档就可以看得到对 Scala 的 API 支持的很好,而 Flink 源码实现主要以 Java 为主,因此也对 Java API 更友好,从两者目前支持的 API 友好程度,应该是 Spark 更好,它目前也支持 Python API,但是 Flink 新版本也在不断的支持 Python API。
Spark 支持更多的 Machine Learning Lib
你可以很轻松的使用 Spark MLlib 提供的机器学习算法,然后将这些这些机器学习算法模型应用在流数据中,目前 Flink Machine Learning 这块的内容还较少,不过阿里宣称会开源些 Flink Machine Learning 算法,保持和 Spark 目前已有的算法一致,我自己在 GitHub 上看到一个阿里开源的仓库,感兴趣的可以看看 flink-ai-extended。
Spark Checkpoint
Spark 和 Flink 一样都支持 Checkpoint,但是 Flink 还支持 Savepoint,你可以在停止 Flink 作业的时候使用 Savepoint 将作业的状态保存下来,当作业重启的时候再从 Savepoint 中将停止作业那个时刻的状态恢复起来,保持作业的状态和之前一致。
Spark SQL
Spark 除了 DataFrames 和 Datasets 外,也还有 SQL API,这样你就可以通过 SQL 查询数据,另外 Spark SQL 还可以用于从 Hive 中读取数据。
Spark Streaming 优缺点
1、优点
- Spark Streaming 内部的实现和调度方式高度依赖 Spark 的 DAG 调度器和 RDD,这就决定了 Spark Streaming 的设计初衷必须是粗粒度方式的,也就无法做到真正的实时处理
- Spark Streaming 的粗粒度执行方式使其确保“处理且仅处理一次”的特性,同时也可以更方便地实现容错恢复机制。
- 由于 Spark Streaming 的 DStream 本质是 RDD 在流式数据上的抽象,因此基于 RDD 的各种操作也有相应的基于 DStream 的版本,这样就大大降低了用户对于新框架的学习成本,在了解 Spark 的情况下用户将很容易使用 Spark Streaming。
2、缺点
- Spark Streaming 的粗粒度处理方式也造成了不可避免的数据延迟。在细粒度处理方式下,理想情况下每一条记录都会被实时处理,而在 Spark Streaming 中,数据需要汇总到一定的量后再一次性处理,这就增加了数据处理的延迟,这种延迟是由框架的设计引入的,并不是由网络或其他情况造成的。
- 使用的是 Processing Time 而不是 Event Time
评论