
一、Flink 多种时间语义对比
Flink 在流应用程序中支持不同的 Time 概念,就比如有 Processing Time、Event Time 和 Ingestion Time。
1.1、Processing Time
Processing Time 是指事件被处理时机器的系统时间。
如果 Flink Job 设置的时间策略是 Processing Time 的话,那么后面所有基于时间的操作(如时间窗口)都将会使用当时机器的系统时间。每小时 Processing Time 窗口将包括在系统时钟指示整个小时之间到达特定操作的所有事件。
例如,如果应用程序在上午 9:15 开始运行,则第一个每小时 Processing Time 窗口将包括在上午 9:15 到上午 10:00 之间处理的事件,下一个窗口将包括在上午 10:00 到 11:00 之间处理的事件。
Processing Time 是最简单的 "Time" 概念,不需要流和机器之间的协调,它提供了最好的性能和最低的延迟。但是,在分布式和异步的环境下,Processing Time 不能提供确定性,因为它容易受到事件到达系统的速度(例如从消息队列)、事件在系统内操作流动的速度以及中断的影响。
1.2、Event Time
Event Time 是指事件发生的时间,一般就是数据本身携带的时间。这个时间通常是在事件到达 Flink 之前就确定的,并且可以从每个事件中获取到事件时间戳。在 Event Time 中,时间取决于数据,而跟其他没什么关系。Event Time 程序必须指定如何生成 Event Time 水印,这是表示 Event Time 进度的机制。
完美的说,无论事件什么时候到达或者其怎么排序,最后处理 Event Time 将产生完全一致和确定的结果。但是,除非事件按照已知顺序(事件产生的时间顺序)到达,否则处理 Event Time 时将会因为要等待一些无序事件而产生一些延迟。由于只能等待一段有限的时间,因此就难以保证处理 Event Time 将产生完全一致和确定的结果。
假设所有数据都已到达,Event Time 操作将按照预期运行,即使在处理无序事件、延迟事件、重新处理历史数据时也会产生正确且一致的结果。 例如,每小时事件时间窗口将包含带有落入该小时的事件时间戳的所有记录,不管它们到达的顺序如何(是否按照事件产生的时间)。
1.3、Ingestion Time
Ingestion Time 是事件进入 Flink 的时间。 在数据源操作处(进入 Flink source 时),每个事件将进入 Flink 时当时的时间作为时间戳,并且基于时间的操作(如时间窗口)会利用这个时间戳。
Ingestion Time 在概念上位于 Event Time 和 Processing Time 之间。 与 Processing Time 相比,成本可能会高一点,但结果更可预测。因为 Ingestion Time 使用稳定的时间戳(只在进入 Flink 的时候分配一次),所以对事件的不同窗口操作将使用相同的时间戳(第一次分配的时间戳),而在 Processing Time 中,每个窗口操作符可以将事件分配给不同的窗口(基于机器系统时间和到达延迟)。
与 Event Time 相比,Ingestion Time 程序无法处理任何无序事件或延迟数据,但程序中不必指定如何生成水印。
在 Flink 中,Ingestion Time 与 Event Time 非常相似,唯一区别就是 Ingestion Time 具有自动分配时间戳和自动生成水印功能。
二、Window 基础概念与实现原理
目前有许多数据分析的场景从批处理到流处理的演变, 虽然可以将批处理作为流处理的特殊情况来处理,但是分析无穷集的流数据通常需要思维方式的转变并且具有其自己的术语,例如,“windowing(窗口化)”、“at-least-once(至少一次)”、“exactly-once(只有一次)” 。
对于刚刚接触流处理的人来说,这种转变和新术语可能会非常混乱。 Apache Flink 是一个为生产环境而生的流处理器,具有易于使用的 API,可以用于定义高级流分析程序。Flink 的 API 在数据流上具有非常灵活的窗口定义,使其在其他开源流处理框架中脱颖而出。
2.1、Window 简介
2.2、Window 作用
通常来讲,Window 就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。Window 又可以分为基于时间(Time-based)的 Window 以及基于数量(Count-based)的 window。
2.3、Flink 自带的 Window
Flink 在 KeyedStream(DataStream 的继承类) 中提供了下面几种 Window:
- 以时间驱动的 Time Window
- 以事件数量驱动的 Count Window
- 以会话间隔驱动的 Session Window
提供上面三种 Window 机制后,由于某些特殊的需要,DataStream API 也提供了定制化的 Window 操作,供用户自定义 Window。
三、数据转换 Operator(算子)
在 Flink 应用程序中,无论应用程序是批程序,还是流程序,都是上图这种模型,有数据源(source),有数据下游(sink),应用程序多是对数据源过来的数据做一系列操作,总结如下。

1、Source: 数据源,Flink 在流处理和批处理上的 source 大概有 4 类:基于本地集合的 source、基于文件的 source、基于网络套接字的 source、自定义的 source。自定义的 source 常见的有 Apache kafka、Amazon Kinesis Streams、RabbitMQ、Twitter Streaming API、Apache NiFi 等,当然你也可以定义自己的 source。
2、Transformation: 数据转换的各种操作,有 Map / FlatMap / Filter / KeyBy / Reduce / Fold / Aggregations / Window / WindowAll / Union / Window join / Split / Select / Project 等,操作很多,可以将数据转换计算成你想要的数据。
3、Sink: 接收器,Sink 是指 Flink 将转换计算后的数据发送的地点 ,你可能需要存储下来。Flink 常见的 Sink 大概有如下几类:写入文件、打印出来、写入 Socket 、自定义的 Sink 。自定义的 sink 常见的有 Apache kafka、RabbitMQ、MySQL、ElasticSearch、Apache Cassandra、Hadoop FileSystem 等,同理你也可以定义自己的 Sink。
3.1 DataStream Operator
Map
Map 算子的输入流是 DataStream,经过 Map 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成一个元素,举个例子:
SingleOutputStreamOperator<Employee> map = employeeStream.map(new MapFunction<Employee, Employee>() {
@Override
public Employee map(Employee employee) throws Exception {
employee.salary = employee.salary + 5000;
return employee;
}
});
map.print();
FlatMap
FlatMap 算子的输入流是 DataStream,经过 FlatMap 算子后返回的数据格式是 SingleOutputStreamOperator 类型,获取一个元素并生成零个、一个或多个元素,举个例子:
SingleOutputStreamOperator<Employee> flatMap = employeeStream.flatMap(new FlatMapFunction<Employee, Employee>() {
@Override
public void flatMap(Employee employee, Collector<Employee> out) throws Exception {
if (employee.salary >= 40000) {
out.collect(employee);
}
}
});
flatMap.print();
四、使用 DataStream API 来处理数据
源码里面的 DataStream 大概有哪些类呢?如下图所示,展示了 1.9 版本中的 DataStream 类。
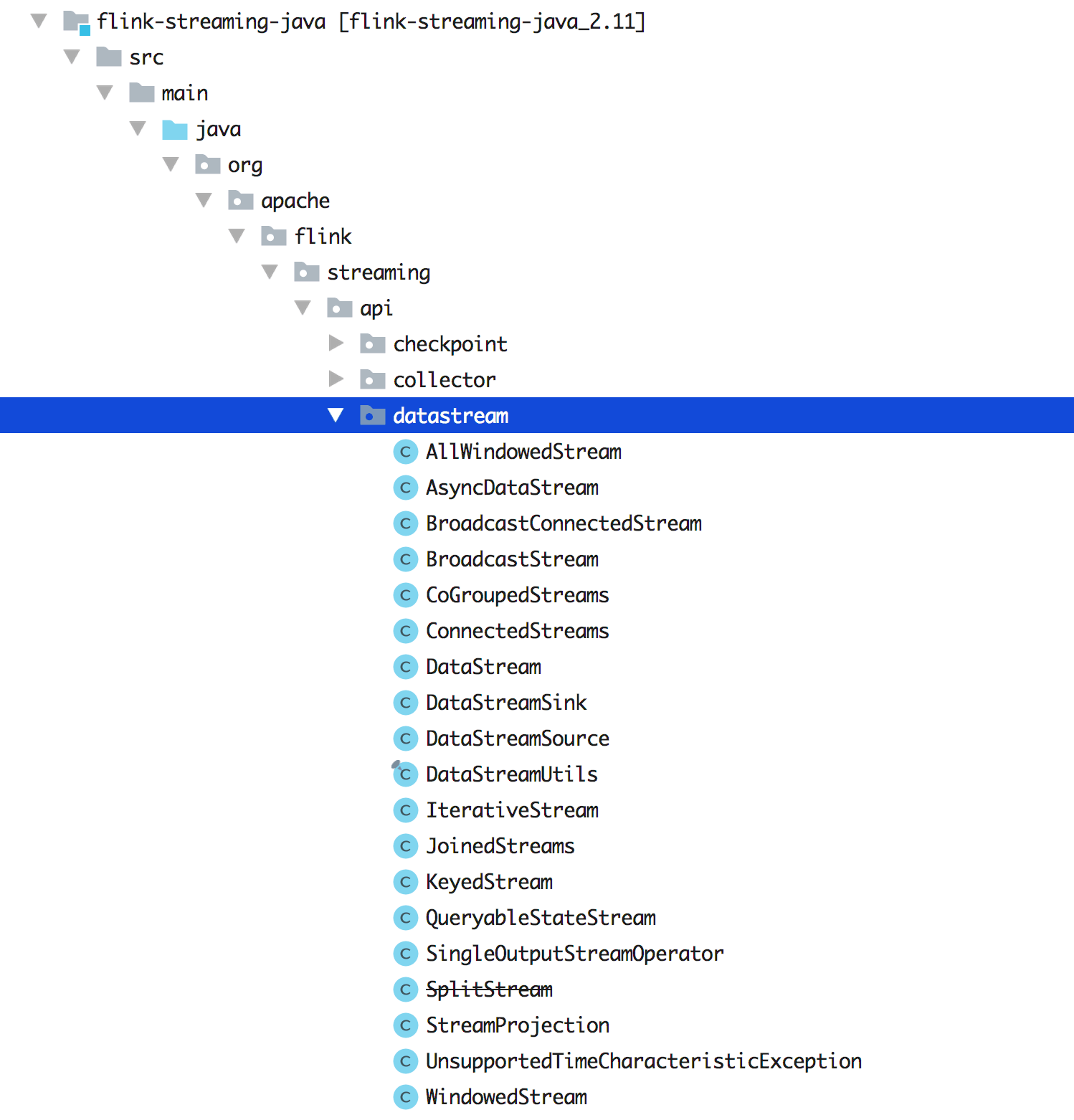
可以发现其实还是有很多的类,只有熟练掌握了这些 API,我们才能在做数据转换和计算的时候足够灵活的运用开来(知道何时该选用哪种 DataStream?选用哪个 Function?)。那么先从 DataStream 开始吧。
4.1、DataStream 的用法及分析
DataStream 这个类的定义:
A DataStream represents a stream of elements of the same type. A DataStreamcan be transformed into another DataStream by applying a transformation as
DataStream#map or DataStream#filter}
大概意思是:DataStream 表示相同类型的元素组成的数据流,一个数据流可以通过 map/filter 等算子转换成另一个数据流。
然后 DataStream 的类结构图如下图所示:
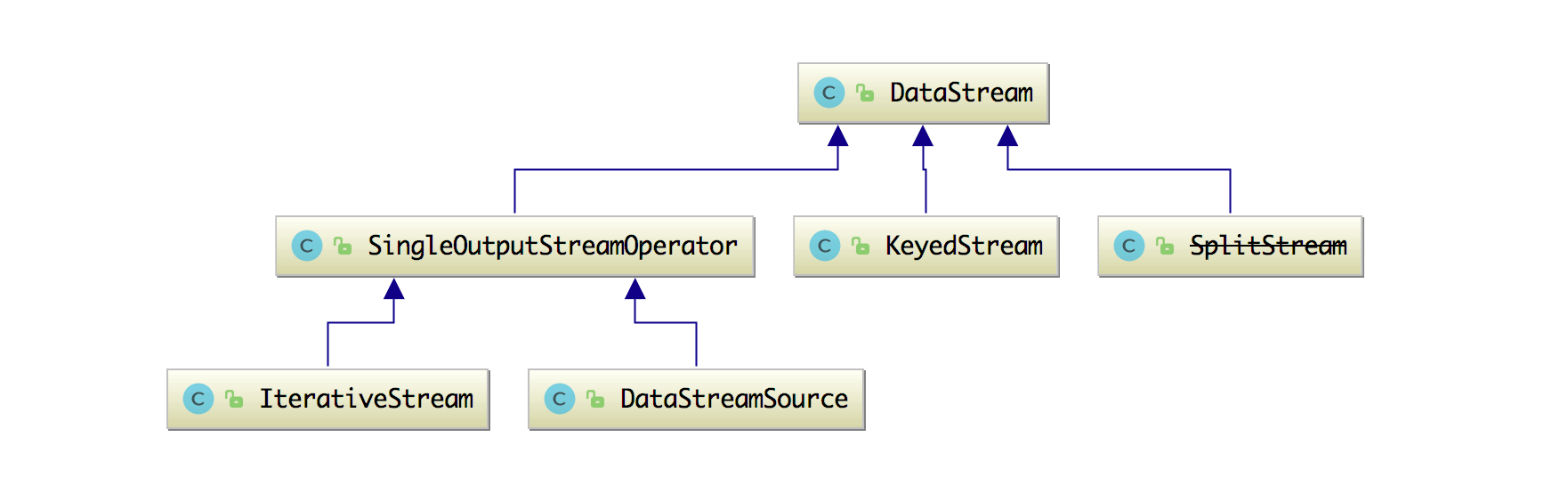
它的继承类有 KeyedStream、SingleOutputStreamOperator 和 SplitStream。下面看 DataStream 这个类中的属性和方法吧。
它的属性就只有两个:
protected final StreamExecutionEnvironment environment;
protected final StreamTransformation<T> transformation;
但是它的方法却有很多,并且平时写的 Flink Job 几乎离不开这些方法,这也注定了这个类的重要性,所以得好好看下这些方法该如何使用,以及是如何实现的。
public final DataStream<T> union(DataStream<T>... streams) {
List<StreamTransformation<T>> unionedTransforms = new ArrayList<>();
unionedTransforms.add(this.transformation);
for (DataStream<T> newStream : streams) {
if (!getType().equals(newStream.getType())) { //判断数据类型是否一致
throw new IllegalArgumentException("Cannot union streams of different types: " + getType() + " and " + newStream.getType());
}
unionedTransforms.add(newStream.getTransformation());
}
//构建新的数据流
return new DataStream<>(this.environment, new UnionTransformation<>(unionedTransforms));//通过使用 UnionTransformation 将多个 StreamTransformation 合并起来
}
那么该如何去使用 union 呢(不止连接一个数据流,也可以连接多个数据流)?
//数据流 1 和 2
final DataStream<Integer> stream1 = env.addSource(...);
final DataStream<Integer> stream2 = env.addSource(...);
//union
stream1.union(stream2)
split
该方法可以将两个数据流进行拆分,拆分后的数据流变成了 SplitStream(在下文会详细介绍这个类的内部实现),该 split 方法通过传入一个 OutputSelector 参数进行数据选择,方法内部实现就是构造一个 SplitStream 对象然后返回:
public SplitStream<T> split(OutputSelector<T> outputSelector) {
return new SplitStream<>(this, clean(outputSelector));
}
该如何使用这个方法?
dataStream.split(new OutputSelector<Integer>() {
private static final long serialVersionUID = 8354166915727490130L;
@Override
public Iterable<String> select(Integer value) {
List<String> s = new ArrayList<String>();
if (value > 4) { //大于 4 的数据放到 > 这个 tag 里面去
s.add(">");
} else { //小于等于 4 的数据放到 < 这个 tag 里面去
s.add("<");
}
return s;
}
});
注意:该方法已经不推荐使用了!在 1.7 版本以后建议使用 Side Output 来实现分流操作。
connect
通过连接不同或相同数据类型的数据流,然后创建一个新的连接数据流,如果连接的数据流也是一个 DataStream 的话,那么连接后的数据流为 ConnectedStreams(会在下文介绍这个类的具体实现),它的具体实现如下:
public <R> ConnectedStreams<T, R> connect(DataStream<R> dataStream) {
return new ConnectedStreams<>(environment, this, dataStream);
}
如果连接的数据流是一个 BroadcastStream(广播数据流),那么连接后的数据流是一个 BroadcastConnectedStream(会在下文详细介绍该类的内部实现),它的具体实现如下:
public <R> BroadcastConnectedStream<T, R> connect(BroadcastStream<R> broadcastStream) {
return new BroadcastConnectedStream<>(
environment, this, Preconditions.checkNotNull(broadcastStream),
broadcastStream.getBroadcastStateDescriptor());
}
使用如下:
//1、连接 DataStream
DataStream<Tuple2<Long, Long>> src1 = env.fromElements(new Tuple2<>(0L, 0L));
DataStream<Tuple2<Long, Long>> src2 = env.fromElements(new Tuple2<>(0L, 0L));
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connected = src1.connect(src2);
//2、连接 BroadcastStream
DataStream<Tuple2<Long, Long>> src1 = env.fromElements(new Tuple2<>(0L, 0L));
final BroadcastStream<String> broadcast = srcTwo.broadcast(utterDescriptor);
BroadcastConnectedStream<Tuple2<Long, Long>, String> connect = src1.connect(broadcast);
keyBy
keyBy 方法是用来将数据进行分组的,通过该方法可以将具有相同 key 的数据划分在一起组成新的数据流,该方法有四种(它们的参数各不一样):
//1、参数是 KeySelector 对象
public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> key) {
...
return new KeyedStream<>(this, clean(key));//构造 KeyedStream 对象
}
//2、参数是 KeySelector 对象和 TypeInformation 对象
public <K> KeyedStream<T, K> keyBy(KeySelector<T, K> key, TypeInformation<K> keyType) {
...
return new KeyedStream<>(this, clean(key), keyType);//构造 KeyedStream 对象
}
//3、参数是 1 至多个字段(用 0、1、2... 表示)
public KeyedStream<T, Tuple> keyBy(int... fields) {
if (getType() instanceof BasicArrayTypeInfo || getType() instanceof PrimitiveArrayTypeInfo) {
return keyBy(KeySelectorUtil.getSelectorForArray(fields, getType()));
} else {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));//调用 private 的 keyBy 方法
}
}
//4、参数是 1 至多个字符串
public KeyedStream<T, Tuple> keyBy(String... fields) {
return keyBy(new Keys.ExpressionKeys<>(fields, getType()));//调用 private 的 keyBy 方法
}
//真正调用的方法
private KeyedStream<T, Tuple> keyBy(Keys<T> keys) {
return new KeyedStream<>(this, clean(KeySelectorUtil.getSelectorForKeys(keys,
getType(), getExecutionConfig())));
}
如何使用呢:
DataStream<Event> dataStream = env.fromElements(
new Event(1, "zhisheng01", 1.0),
new Event(2, "zhisheng02", 2.0),
new Event(3, "zhisheng03", 2.1),
new Event(3, "zhisheng04", 3.0),
new SubEvent(4, "zhisheng05", 4.0, 1.0),
);
//第1种
dataStream.keyBy(new KeySelector<Event, Integer>() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
});
//第2种
dataStream.keyBy(new KeySelector<Event, Integer>() {
@Override
public Integer getKey(Event value) throws Exception {
return value.getId();
}
}, Types.STRING);
//第3种
dataStream.keyBy(0);
//第4种
dataStream.keyBy("zhisheng01", "zhisheng02");
partitionCustom
使用自定义分区器在指定的 key 字段上将 DataStream 分区,这个 partitionCustom 有 3 个不同参数的方法,分别要传入的参数有自定义分区 Partitioner 对象、位置、字符和 KeySelector。它们内部也都是调用了私有的 partitionCustom 方法。
broadcast
broadcast 是将数据流进行广播,然后让下游的每个并行 Task 中都可以获取到这份数据流,通常这些数据是一些配置,一般这些配置数据的数据量不能太大,否则资源消耗会比较大。这个 broadcast 方法也有两个,一个是无参数,它返回的数据是 DataStream;另一种的参数是 MapStateDescriptor,它返回的参数是 BroadcastStream(这个也会在下文详细介绍)。
使用方法:
//1、第一种
DataStream<Tuple2<Integer, String>> source = env.addSource(...).broadcast();
//2、第二种
final MapStateDescriptor<Long, String> utterDescriptor = new MapStateDescriptor<>(
"broadcast-state", BasicTypeInfo.LONG_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO
);
final DataStream<String> srcTwo = env.fromCollection(expected.values());
final BroadcastStream<String> broadcast = srcTwo.broadcast(utterDescriptor);
map
map 方法需要传入的参数是一个 MapFunction,当然传入 RichMapFunction 也是可以的,它返回的是 SingleOutputStreamOperator(这个类在会在下文详细介绍),该 map 方法里面的实现如下:
public <R> SingleOutputStreamOperator<R> map(MapFunction<T, R> mapper) {
TypeInformation<R> outType = TypeExtractor.getMapReturnTypes(clean(mapper), getType(),
Utils.getCallLocationName(), true);
//调用 transform 方法
return transform("Map", outType, new StreamMap<>(clean(mapper)));
}
该方法平时使用的非常频繁,该如何使用这个方法呢:
dataStream.map(new MapFunction<Integer, String>() {
private static final long serialVersionUID = 1L;
@Override
public String map(Integer value) throws Exception {
return value.toString();
}
})
flatMap
flatMap 方法需要传入一个 FlatMapFunction 参数,当然传入 RichFlatMapFunction 也是可以的,如果你的 Flink Job 里面有连续的 filter 和 map 算子在一起,可以考虑使用 flatMap 一个算子来完成两个算子的工作,它返回的是 SingleOutputStreamOperator,该 flatMap 方法里面的实现如下:
public <R> SingleOutputStreamOperator<R> flatMap(FlatMapFunction<T, R> flatMapper) {
TypeInformation<R> outType = TypeExtractor.getFlatMapReturnTypes(clean(flatMapper),
getType(), Utils.getCallLocationName(), true);
//调用 transform 方法
return transform("Flat Map", outType, new StreamFlatMap<>(clean(flatMapper)));
}
该方法平时使用的非常频繁,使用方式如下:
dataStream.flatMap(new FlatMapFunction<Integer, Integer>() {
@Override
public void flatMap(Integer value, Collector<Integer> out) throws Exception {
out.collect(value);
}
})
process
在输入流上应用给定的 ProcessFunction,从而创建转换后的输出流,通过该方法返回的是 SingleOutputStreamOperator,具体代码实现如下:
public <R> SingleOutputStreamOperator<R> process(ProcessFunction<T, R> processFunction) {
TypeInformation<R> outType = TypeExtractor.getUnaryOperatorReturnType(
processFunction, ProcessFunction.class, 0, 1,
TypeExtractor.NO_INDEX, getType(), Utils.getCallLocationName(), true);
//调用下面的 process 方法
return process(processFunction, outType);
}
public <R> SingleOutputStreamOperator<R> process(
ProcessFunction<T, R> processFunction,
TypeInformation<R> outputType) {
ProcessOperator<T, R> operator = new ProcessOperator<>(clean(processFunction));
//调用 transform 方法
return transform("Process", outputType, operator);
}
使用方法:
DataStreamSource<Long> data = env.generateSequence(0, 0);
//定义的 ProcessFunction
ProcessFunction<Long, Integer> processFunction = new ProcessFunction<Long, Integer>() {
private static final long serialVersionUID = 1L;
@Override
public void processElement(Long value, Context ctx,
Collector<Integer> out) throws Exception {
//具体逻辑
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx,
Collector<Integer> out) throws Exception {
//具体逻辑
}
};
DataStream<Integer> processed = data.keyBy(new IdentityKeySelector<Long>()).process(processFunction);
filter
filter 用来过滤数据的,它需要传入一个 FilterFunction,然后返回的数据也是 SingleOutputStreamOperator,该方法的实现是:
public SingleOutputStreamOperator<T> filter(FilterFunction<T> filter) {
return transform("Filter", getType(), new StreamFilter<>(clean(filter)));
}
该方法平时使用非常多:
DataStream<String> filter1 = src
.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return "zhisheng".equals(value);
}
})
上面这些方法是平时写代码时用的非常多的方法,这里讲解了它们的实现原理和使用方式,当然还有其他方法,比如 assignTimestampsAndWatermarks、join、shuffle、forward、addSink、rebalance、iterate、coGroup、project、timeWindowAll、countWindowAll、windowAll、print 等,这里由于篇幅的问题就不一一展开来讲了。
4.2、SingleOutputStreamOperator 的用法及分析
SingleOutputStreamOperator 这个类继承自 DataStream,所以 DataStream 中有的方法在这里也都有,那么这里就讲解下额外的方法的作用,如下。
- name():该方法可以设置当前数据流的名称,如果设置了该值,则可以在 Flink UI 上看到该值;uid() 方法可以为算子设置一个指定的 ID,该 ID 有个作用就是如果想从 savepoint 恢复 Job 时是可以根据这个算子的 ID 来恢复到它之前的运行状态;
- setParallelism() :该方法是为每个算子单独设置并行度的,这个设置优先于你通过 env 设置的全局并行度;
- setMaxParallelism() :该为算子设置最大的并行度;
- setResources():该方法有两个(参数不同),设置算子的资源,但是这两个方法对外还没开放(是私有的,暂时功能性还不全);
- forceNonParallel():该方法强行将并行度和最大并行度都设置为 1;
- setChainingStrategy():该方法对给定的算子设置 ChainingStrategy;
- disableChaining():该这个方法设置后将禁止该算子与其他的算子 chain 在一起;
- getSideOutput():该方法通过给定的 OutputTag 参数从 side output 中来筛选出对应的数据流。
4.3、KeyedStream 的用法及分析
KeyedStream 是 DataStream 在根据 KeySelector 分区后的数据流,DataStream 中常用的方法在 KeyedStream 后也可以用(除了 shuffle、forward 和 keyBy 等分区方法),在该类中的属性分别是 KeySelector 和 TypeInformation。
DataStream 中的窗口方法只有 timeWindowAll、countWindowAll 和 windowAll 这三种全局窗口方法,但是在 KeyedStream 类中的种类就稍微多了些,新增了 timeWindow、countWindow 方法,并且是还支持滑动窗口。
除了窗口方法的新增外,还支持大量的聚合操作方法,比如 reduce、fold、sum、min、max、minBy、maxBy、aggregate 等方法(列举的这几个方法都支持多种参数的)。
最后就是它还有 asQueryableState() 方法,能够将 KeyedStream 发布为可查询的 ValueState 实例。
4.4、SplitStream 的用法及分析
SplitStream 这个类比较简单,它代表着数据分流后的数据流了,它有一个 select 方法可以选择分流后的哪种数据流了,通常它是结合 split 使用的,对于单次分流来说还挺方便的。但是它是一个被废弃的类(Flink 1.7 后被废弃的)其实可以用 side output 来代替这种 split,后面文章中我们也会讲通过简单的案例来讲解一下该如何使用 side output 做数据分流操作。
因为这个类的源码比较少,我们可以看下这个类的实现:
public class SplitStream<OUT> extends DataStream<OUT> {
//构造方法
protected SplitStream(DataStream<OUT> dataStream, OutputSelector<OUT> outputSelector) {
super(dataStream.getExecutionEnvironment(), new SplitTransformation<OUT>(dataStream.getTransformation(), outputSelector));
}
//选择要输出哪种数据流
public DataStream<OUT> select(String... outputNames) {
return selectOutput(outputNames);
}
//上面那个 public 方法内部调用的就是这个方法,该方法是个 private 方法,对外隐藏了它是如何去找到特定的数据流。
private DataStream<OUT> selectOutput(String[] outputNames) {
for (String outName : outputNames) {
if (outName == null) {
throw new RuntimeException("Selected names must not be null");
}
}
//构造了一个 SelectTransformation 对象
SelectTransformation<OUT> selectTransform = new SelectTransformation<OUT>(this.getTransformation(), Lists.newArrayList(outputNames));
//构造了一个 DataStream 对象
return new DataStream<OUT>(this.getExecutionEnvironment(), selectTransform);
}
}
4.5、WindowedStream 的用法及分析
在 WindowedStream 类中定义的属性有 KeyedStream、WindowAssigner、Trigger、Evictor、allowedLateness 和 lateDataOutputTag。
- KeyedStream:代表着数据流,数据分组后再开 Window
- WindowAssigner:Window 的组件之一
- Trigger:Window 的组件之一
- Evictor:Window 的组件之一(可选)
- allowedLateness:用户指定的允许迟到时间长
- lateDataOutputTag:数据延迟到达的 Side output,如果延迟数据没有设置任何标记,则会被丢弃
allowedLateness 这个它可以在窗口后指定允许迟到的时间长,使用如下:
dataStream.keyBy(0)
.timeWindow(Time.milliseconds(20))
.allowedLateness(Time.milliseconds(2))
lateDataOutputTag 这个它将延迟到达的数据发送到由给定 OutputTag 标识的 side output(侧输出),当水印经过窗口末尾(并加上了允许的延迟后),数据就被认为是延迟了。
对于 keyed windows 有五个不同参数的 reduce 方法可以使用,如下:
//1、参数为 ReduceFunction
public SingleOutputStreamOperator<T> reduce(ReduceFunction<T> function) {
...
return reduce(function, new PassThroughWindowFunction<K, W, T>());
}
//2、参数为 ReduceFunction 和 WindowFunction
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function) {
...
return reduce(reduceFunction, function, resultType);
}
//3、参数为 ReduceFunction、WindowFunction 和 TypeInformation
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, WindowFunction<T, R, K, W> function, TypeInformation<R> resultType) {
...
return input.transform(opName, resultType, operator);
}
//4、参数为 ReduceFunction 和 ProcessWindowFunction
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function) {
...
return reduce(reduceFunction, function, resultType);
}
//5、参数为 ReduceFunction、ProcessWindowFunction 和 TypeInformation
public <R> SingleOutputStreamOperator<R> reduce(ReduceFunction<T> reduceFunction, ProcessWindowFunction<T, R, K, W> function, TypeInformation<R> resultType) {
...
return input.transform(opName, resultType, operator);
}
除了 reduce 方法,还有六个不同参数的 fold 方法、aggregate 方法;两个不同参数的 apply 方法、process 方法(其中你会发现这两个 apply 方法和 process 方法内部其实都隐式的调用了一个私有的 apply 方法);其实除了前面说的两个不同参数的 apply 方法外,还有四个其他的 apply 方法,这四个方法也是参数不同,但是其实最终的是利用了 transform 方法;还有的就是一些预定义的聚合方法比如 sum、min、minBy、max、maxBy,它们的方法参数的个数不一致,这些预聚合的方法内部调用的其实都是私有的 aggregate 方法,该方法允许你传入一个 AggregationFunction 参数。来看一个具体的实现:
//max
public SingleOutputStreamOperator<T> max(String field) {
//内部调用私有的的 aggregate 方法
return aggregate(new ComparableAggregator<>(field, input.getType(), AggregationFunction.AggregationType.MAX, false, input.getExecutionConfig()));
}
//私有的 aggregate 方法
private SingleOutputStreamOperator<T> aggregate(AggregationFunction<T> aggregator) {
//继续调用的是 reduce 方法
return reduce(aggregator);
}
//该 reduce 方法内部其实又是调用了其他多个参数的 reduce 方法
public SingleOutputStreamOperator<T> reduce(ReduceFunction<T> function) {
...
function = input.getExecutionEnvironment().clean(function);
return reduce(function, new PassThroughWindowFunction<K, W, T>());
}
4.6、AllWindowedStream 的用法及分析
AllWindowedStream 这种场景下是不需要让数据流做 keyBy 分组操作,直接就进行 windowAll 操作,然后在 windowAll 方法中传入 WindowAssigner 参数对象即可,然后返回的数据结果就是 AllWindowedStream 了,下面使用方式继续执行了 AllWindowedStream 中的 reduce 方法来返回数据:
dataStream.windowAll(SlidingEventTimeWindows.of(Time.of(1, TimeUnit.SECONDS), Time.of(100, TimeUnit.MILLISECONDS)))
.reduce(new RichReduceFunction<Tuple2<String, Integer>>() {
private static final long serialVersionUID = -6448847205314995812L;
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1,
Tuple2<String, Integer> value2) throws Exception {
return value1;
}
});
4.7、ConnectedStreams 的用法及分析
ConnectedStreams 这个类定义是表示(可能)两个不同数据类型的数据连接流,该场景如果对一个数据流进行操作会直接影响另一个数据流,因此可以通过流连接来共享状态。比较常见的一个例子就是一个数据流(随时间变化的规则数据流)通过连接其他的数据流,这样另一个数据流就可以利用这些连接的规则数据流。
ConnectedStreams 在概念上可以认为和 Union 数据流是一样的。
在 ConnectedStreams 类中有三个属性:environment、inputStream1 和 inputStream2,该类中的方法如下图所示:
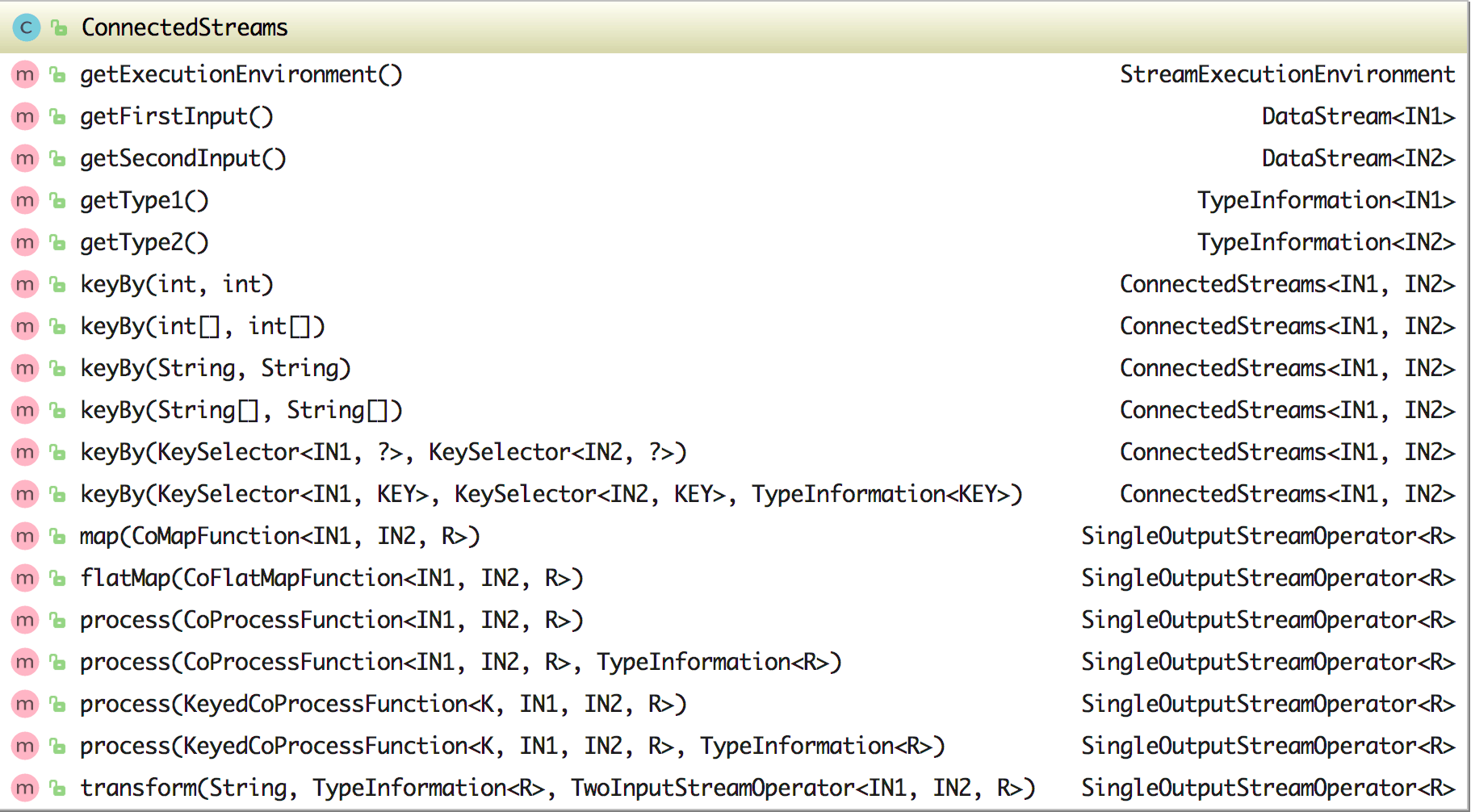
在 ConnectedStreams 中可以通过 getFirstInput 获取连接的第一个流、通过 getSecondInput 获取连接的第二个流,同时它还含有六个 keyBy 方法来将连接后的数据流进行分组,这六个 keyBy 方法的参数各有不同。另外它还含有 map、flatMap、process 方法来处理数据(其中 map 和 flatMap 方法的参数分别使用的是 CoMapFunction 和 CoFlatMapFunction),其实如果你细看其方法里面的实现就会发现都是调用的 transform 方法。
上面讲完了 ConnectedStreams 类的基础定义,接下来我们来看下该类如何使用呢?
DataStream<Tuple2<Long, Long>> src1 = env.fromElements(new Tuple2<>(0L, 0L)); //流 1
DataStream<Tuple2<Long, Long>> src2 = env.fromElements(new Tuple2<>(0L, 0L)); //流 2
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connected = src1.connect(src2); //连接流 1 和流 2
//使用连接流的六种 keyBy 方法
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup1 = connected.keyBy(0, 0);
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup2 = connected.keyBy(new int[]{0}, new int[]{0});
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup3 = connected.keyBy("f0", "f0");
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup4 = connected.keyBy(new String[]{"f0"}, new String[]{"f0"});
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector());
ConnectedStreams<Tuple2<Long, Long>, Tuple2<Long, Long>> connectedGroup5 = connected.keyBy(new FirstSelector(), new FirstSelector(), Types.STRING);
//使用连接流的 map 方法
connected.map(new CoMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Object>() {
private static final long serialVersionUID = 1L;
@Override
public Object map1(Tuple2<Long, Long> value) {
return null;
}
@Override
public Object map2(Tuple2<Long, Long> value) {
return null;
}
});
//使用连接流的 flatMap 方法
connected.flatMap(new CoFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>>() {
@Override
public void flatMap1(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {}
@Override
public void flatMap2(Tuple2<Long, Long> value, Collector<Tuple2<Long, Long>> out) throws Exception {}
}).name("testCoFlatMap")
//使用连接流的 process 方法
connected.process(new CoProcessFunction<Tuple2<Long, Long>, Tuple2<Long, Long>, Tuple2<Long, Long>>() {
@Override
public void processElement1(Tuple2<Long, Long> value, Context ctx, Collector<Tuple2<Long, Long>> out) throws Exception {
if (value.f0 < 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout1-" + String.valueOf(value));
}
}
@Override
public void processElement2(Tuple2<Long, Long> value, Context ctx, Collector<Tuple2<Long, Long>> out) throws Exception {
if (value.f0 >= 3) {
out.collect(value);
ctx.output(sideOutputTag, "sideout2-" + String.valueOf(value));
}
}
});
五、Watermark 的用法和结合 Window 处理延迟数据
上文了解了 Flink 中的三种 Time 和其对应的使用场景,然后在 3.2 节中深入的讲解了 Flink 中窗口的机制以及 Flink 中自带的 Window 的实现原理和使用方法。如果在进行 Window 计算操作的时候,如果使用的时间是 Processing Time,那么在 Flink 消费数据的时候,它完全不需要关心的数据本身的时间,意思也就是说不需要关心数据到底是延迟数据还是乱序数据。因为 Processing Time 只是代表数据在 Flink 被处理时的时间,这个时间是顺序的。但是如果你使用的是 Event Time 的话,那么就不得不面临着这么个问题:事件乱序 & 事件延迟。
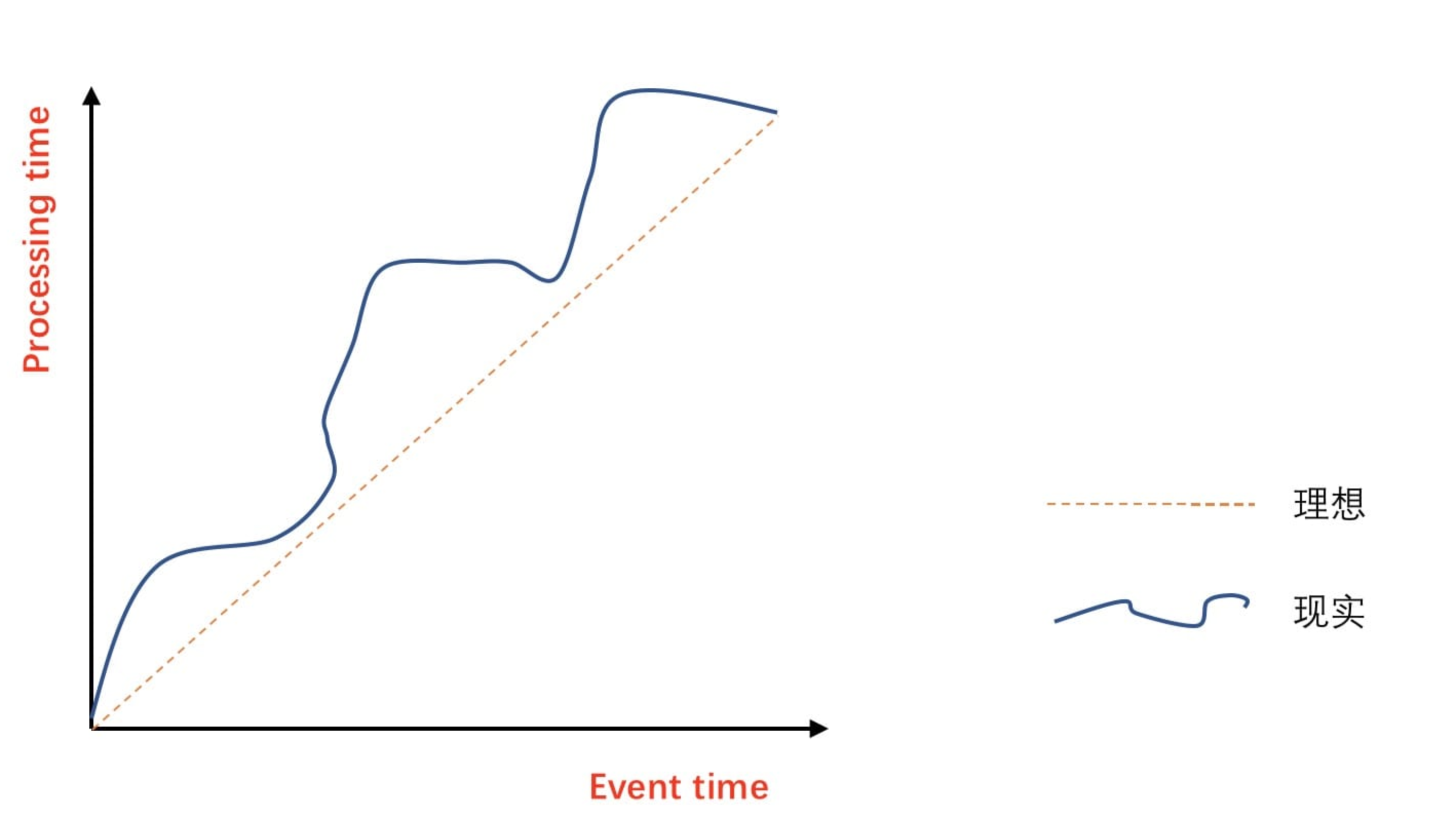
在理想的情况下,Event Time 和 Process Time 是相等的,数据发生的时间与数据处理的时间没有延迟,但是现实却仍然这么骨感,会因为各种各样的问题(网络的抖动、设备的故障、应用的异常等原因)从而导致如图中曲线一样,Process Time 总是会与 Event Time 有一些延迟。所谓乱序,其实是指 Flink 接收到的事件的先后顺序并不是严格的按照事件的 Event Time 顺序排列的。
然而在有些场景下,其实是特别依赖于事件时间而不是处理时间,比如:
- 错误日志的时间戳,代表着发生的错误的具体时间,开发们只有知道了这个时间戳,才能去还原那个时间点系统到底发生了什么问题,或者根据那个时间戳去关联其他的事件,找出导致问题触发的罪魁祸首
- 设备传感器或者监控系统实时上传对应时间点的设备周围的监控情况,通过监控大屏可以实时查看,不错漏重要或者可疑的事件
这种情况下,最有意义的事件发生的顺序,而不是事件到达 Flink 后被处理的顺序。庆幸的是 Flink 支持用户以事件时间来定义窗口(也支持以处理时间来定义窗口),那么这样就要去解决上面所说的两个问题。针对上面的问题(事件乱序 & 事件延迟),Flink 引入了 Watermark 机制来解决。
5.1、Watermark 简介
举个例子:
统计 8:00 ~ 9:00 这个时间段打开淘宝 App 的用户数量,Flink 这边可以开个窗口做聚合操作,但是由于网络的抖动或者应用采集数据发送延迟等问题,于是无法保证在窗口时间结束的那一刻窗口中是否已经收集好了在 8:00 ~ 9:00 中用户打开 App 的事件数据,但又不能无限期的等下去?当基于事件时间的数据流进行窗口计算时,最为困难的一点也就是如何确定对应当前窗口的事件已经全部到达。然而实际上并不能百分百的准确判断,因此业界常用的方法就是基于已经收集的消息来估算是否还有消息未到达,这就是 Watermark 的思想。
Watermark 是一种衡量 Event Time 进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的 Watermark。Watermark 本质来说就是一个时间戳,代表着比这时间戳早的事件已经全部到达窗口,即假设不会再有比这时间戳还小的事件到达,这个假设是触发窗口计算的基础,只有 Watermark 大于窗口对应的结束时间,窗口才会关闭和进行计算。按照这个标准去处理数据,那么如果后面还有比这时间戳更小的数据,那么就视为迟到的数据,对于这部分迟到的数据,Flink 也有相应的机制(下文会讲)去处理。
下面通过几个图来了解一下 Watermark 是如何工作的!如下图所示,数据是 Flink 从消息队列中消费的,然后在 Flink 中有个 4s 的时间窗口(根据事件时间定义的窗口),消息队列中的数据是乱序过来的,数据上的数字代表着数据本身的 timestamp,W(4) 和 W(9) 是水印。

经过 Flink 的消费,数据 1、3、2 进入了第一个窗口,然后 7 会进入第二个窗口,接着 3 依旧会进入第一个窗口,然后就有水印了,此时水印过来了,就会发现水印的 timestamp 和第一个窗口结束时间是一致的,那么它就表示在后面不会有比 4 还小的数据过来了,接着就会触发第一个窗口的计算操作,如下图所示。
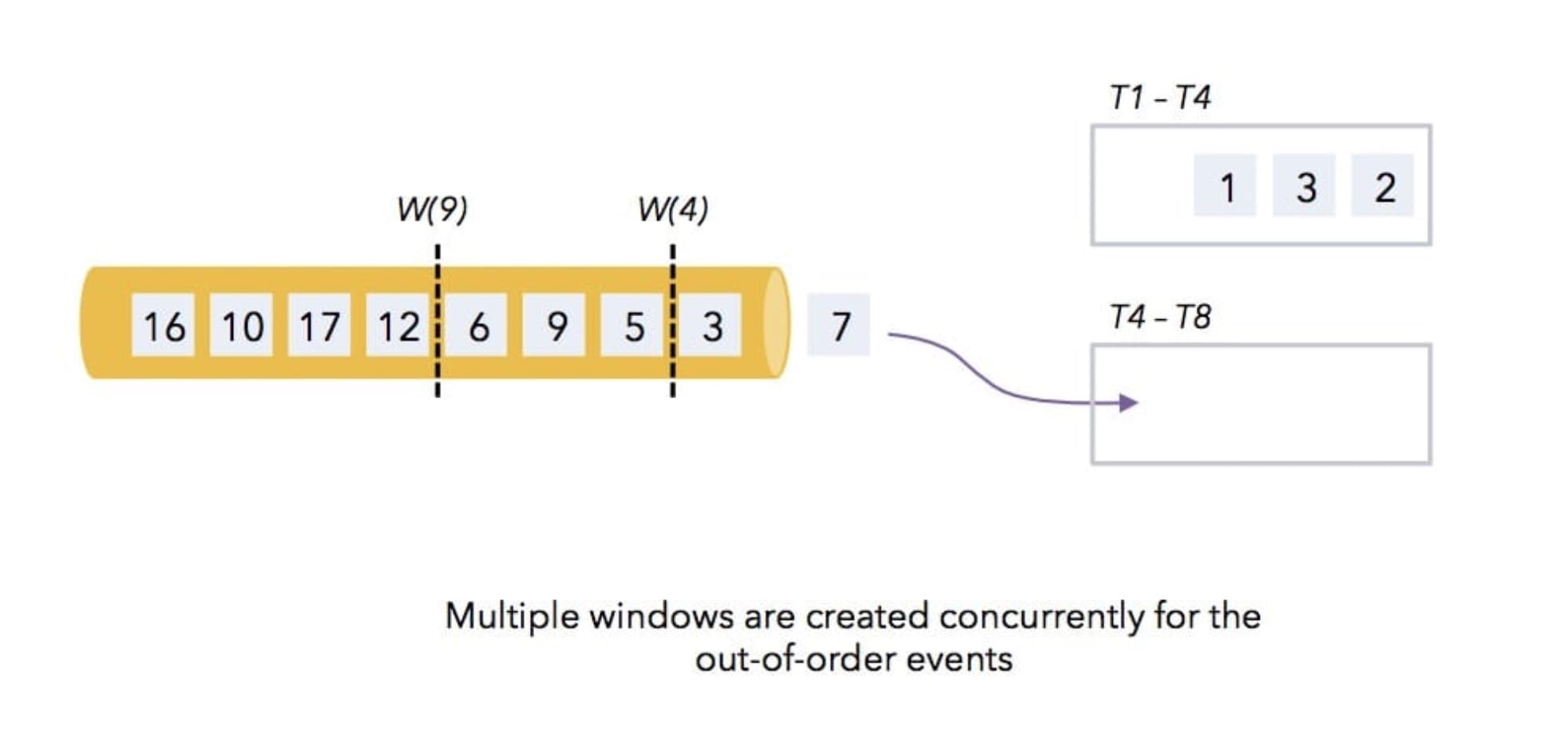
那么接着后面的数据 5 和 6 会进入到第二个窗口里面,数据 9 会进入在第三个窗口里面,如下图所示。
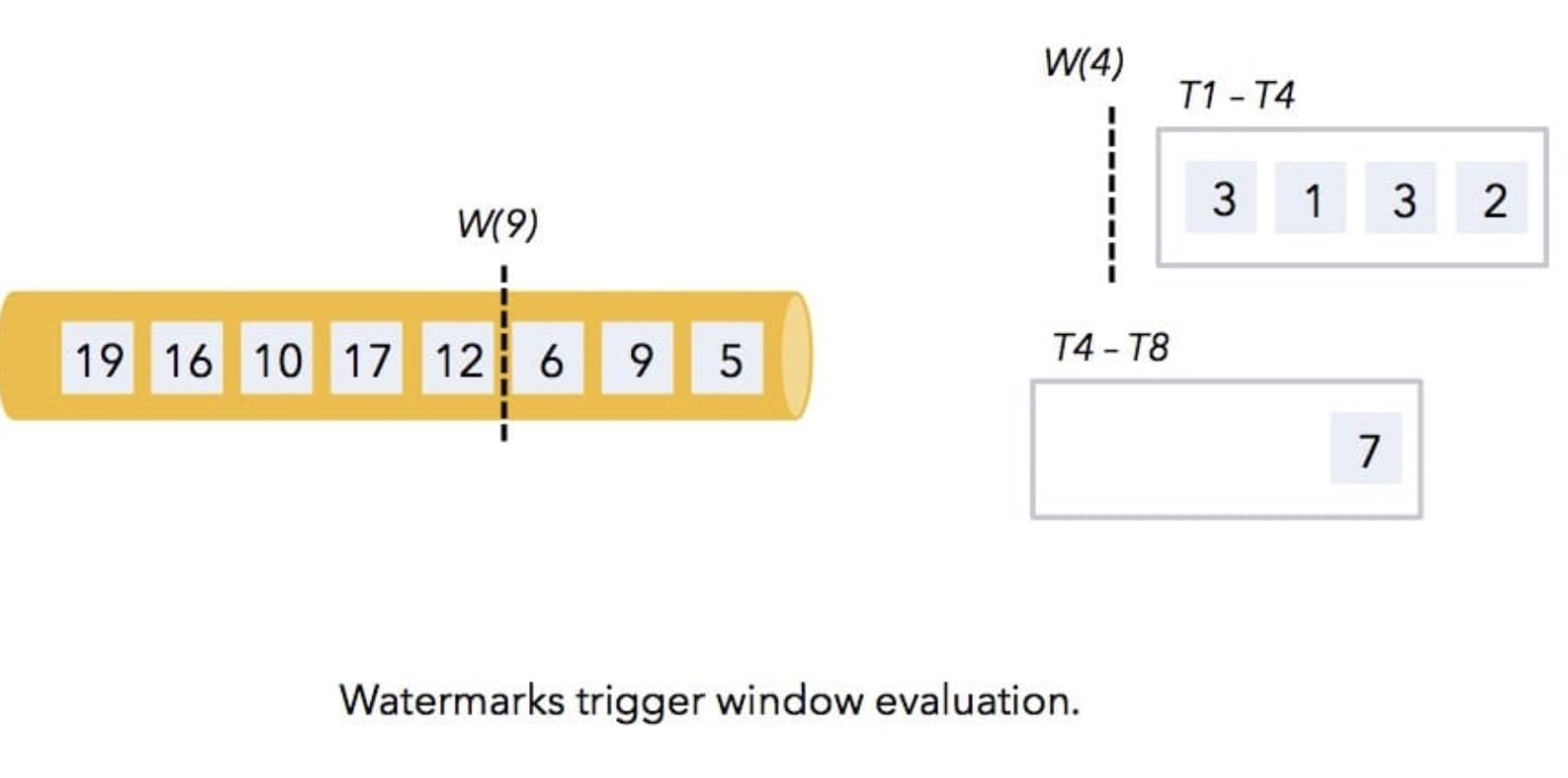
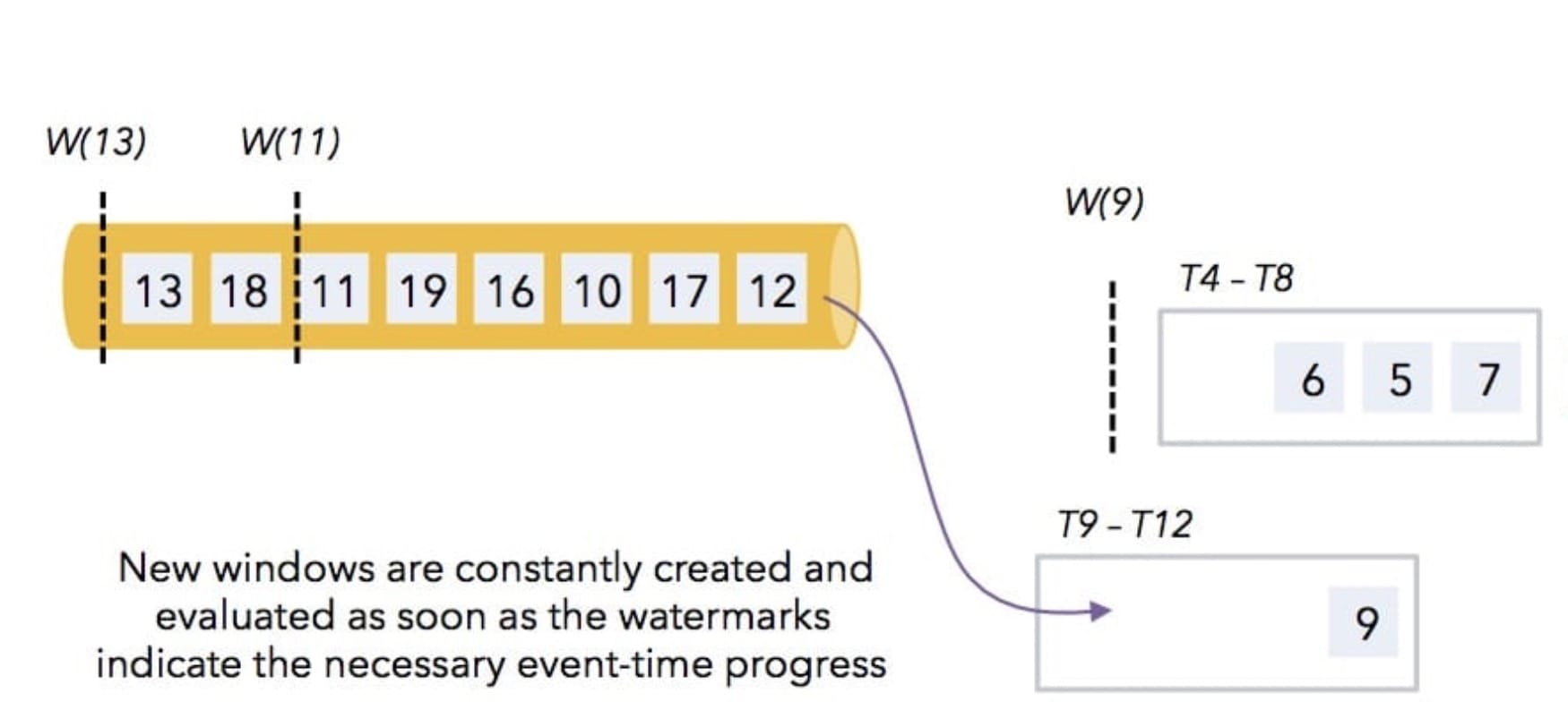
那么当遇到水印 9 时,发现水印比第二个窗口的结束时间 8 还大,所以第二个窗口也会触发进行计算,然后以此继续类推下去,如下图所示。
5.2、Flink 中的 Watermark 的设置
在 Flink 中,数据处理中需要通过调用 DataStream 中的 assignTimestampsAndWatermarks 方法来分配时间和水印,该方法可以传入两种参数,一个是 AssignerWithPeriodicWatermarks,另一个是 AssignerWithPunctuatedWatermarks。
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(AssignerWithPeriodicWatermarks<T> timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPeriodicWatermarks<T> cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPeriodicWatermarksOperator<T> operator = new TimestampsAndPeriodicWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
public SingleOutputStreamOperator<T> assignTimestampsAndWatermarks(AssignerWithPunctuatedWatermarks<T> timestampAndWatermarkAssigner) {
final int inputParallelism = getTransformation().getParallelism();
final AssignerWithPunctuatedWatermarks<T> cleanedAssigner = clean(timestampAndWatermarkAssigner);
TimestampsAndPunctuatedWatermarksOperator<T> operator = new TimestampsAndPunctuatedWatermarksOperator<>(cleanedAssigner);
return transform("Timestamps/Watermarks", getTransformation().getOutputType(), operator).setParallelism(inputParallelism);
}
所以设置 Watermark 是有如下两种方式:
1、AssignerWithPunctuatedWatermarks:数据流中每一个递增的 EventTime 都会产生一个 Watermark。
在实际的生产环境中,在 TPS 很高的情况下会产生大量的 Watermark,可能在一定程度上会对下游算子造成一定的压力,所以只有在实时性要求非常高的场景才会选择这种方式来进行水印的生成。
2、AssignerWithPeriodicWatermarks:周期性的(一定时间间隔或者达到一定的记录条数)产生一个 Watermark。
在实际的生产环境中,通常这种使用较多,它会周期性产生 Watermark 的方式,但是必须结合时间或者积累条数两个维度,否则在极端情况下会有很大的延时,所以 Watermark 的生成方式需要根据业务场景的不同进行不同的选择。
5.3、Punctuated Watermark
AssignerWithPunctuatedWatermarks 接口中包含了 checkAndGetNextWatermark 方法,这个方法会在每次 extractTimestamp() 方法被调用后调用,它可以决定是否要生成一个新的水印,返回的水印只有在不为 null 并且时间戳要大于先前返回的水印时间戳的时候才会发送出去,如果返回的水印是 null 或者返回的水印时间戳比之前的小则不会生成新的水印。
怎么利用这个来定义水印生成器呢?
public class WordPunctuatedWatermark implements AssignerWithPunctuatedWatermarks<Word> {
@Nullable
@Override
public Watermark checkAndGetNextWatermark(Word lastElement, long extractedTimestamp) {
return extractedTimestamp % 3 == 0 ? new Watermark(extractedTimestamp) : null;
}
@Override
public long extractTimestamp(Word element, long previousElementTimestamp) {
return element.getTimestamp();
}
}
需要注意的是这种情况下可以为每个事件都生成一个水印,但是因为水印是要在下游参与计算的,所以过多的话会导致整体计算性能下降。
5.4、Periodic Watermark
通常在生产环境中使用 AssignerWithPeriodicWatermarks 来定期分配时间戳并生成水印比较多。
public class WordPeriodicWatermark implements AssignerWithPeriodicWatermarks<Word> {
private long currentTimestamp = Long.MIN_VALUE;
@Override
public long extractTimestamp(Word word, long previousElementTimestamp) {
long timestamp = word.getTimestamp();
currentTimestamp = Math.max(timestamp, currentTimestamp);
return word.getTimestamp();
}
@Nullable
@Override
public Watermark getCurrentWatermark() {
long maxTimeLag = 5000;
return new Watermark(currentTimestamp == Long.MIN_VALUE ? Long.MIN_VALUE : currentTimestamp - maxTimeLag);
}
}
上面的是根据 Word 数据自定义的水印周期性生成器,在这个类中,有两个方法 extractTimestamp() 和 getCurrentWatermark()。extractTimestamp() 方法是从数据本身中提取 Event Time,然后将当前时间戳与事件时间进行比较,取最大值后赋值给当前时间戳 currentTimestamp,然后返回事件时间。getCurrentWatermark() 方法是获取当前的水位线,通过 currentTimestamp - maxTimeLag 得到水印的值,这里有个 maxTimeLag 参数代表数据能够延迟的时间,上面代码中定义的 long maxTimeLag = 5000; 表示最大允许数据延迟时间为 5s,超过 5s 的话如果还来了之前早的数据,那么 Flink 就会丢弃了,因为 Flink 的窗口中的数据是要触发的,不可能一直在等着这些迟到的数据(由于网络的问题数据可能一直没发上来)而不让窗口触发结束进行计算操作。
通过定义这个时间,可以避免部分数据因为网络或者其他的问题导致不能够及时上传从而不把这些事件数据作为计算的,那么如果在这延迟之后还有更早的数据到来的话,那么 Flink 就会丢弃了,所以合理的设置这个允许延迟的时间也是一门细活,得观察生产环境数据的采集到消息队列再到 Flink 整个流程是否会出现延迟,统计平均延迟大概会在什么范围内波动。这也就是说明了一个事实那就是 Flink 中设计这个水印的根本目的是来解决部分数据乱序或者数据延迟的问题,而不能真正做到彻底解决这个问题,不过这一特性在相比于其他的流处理框架已经算是非常给力了。
AssignerWithPeriodicWatermarks 这个接口有四个实现类,如下图所示:
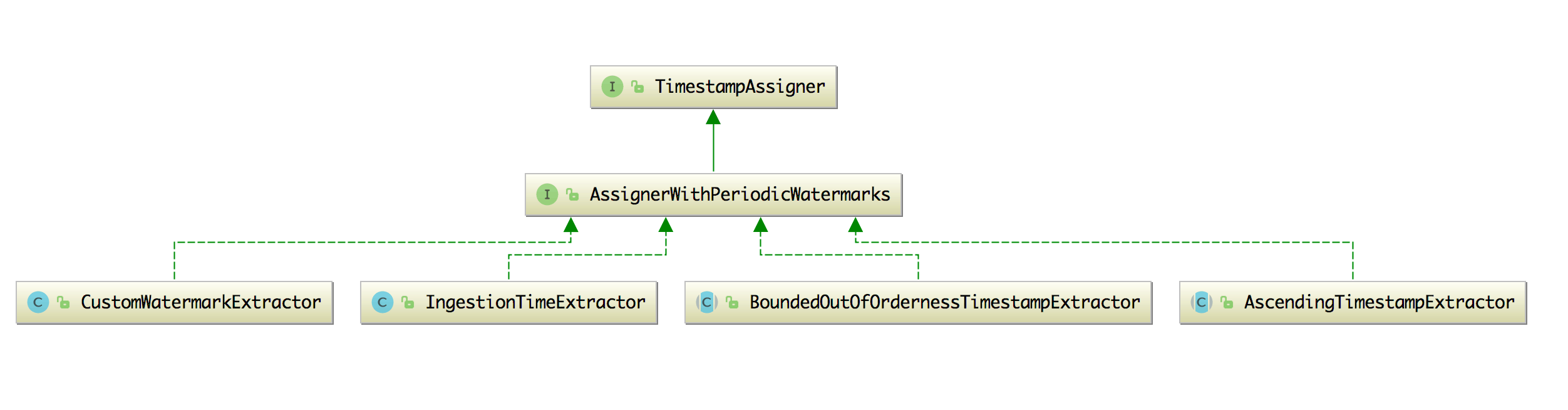
这四个实现类的功能和使用方式如下:
1、BoundedOutOfOrdernessTimestampExtractor:该类用来发出滞后于数据时间的水印,它的目的其实就是和我们上面定义的那个类作用是类似的,你可以传入一个时间代表着可以允许数据延迟到来的时间是多长。该类内部实现如下图所示:
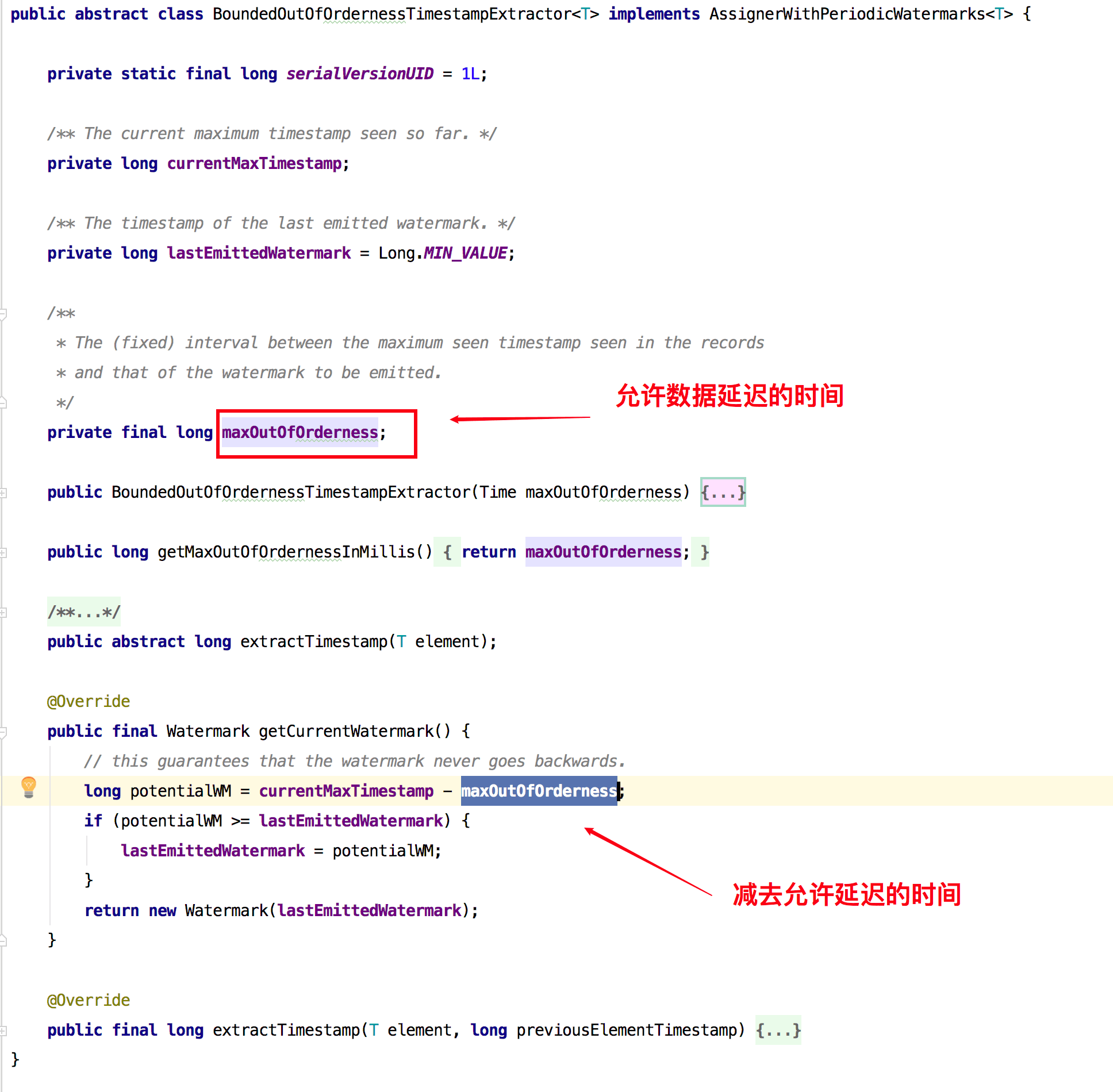
可以像下面一样使用该类来分配时间和生成水印:
//Time.seconds(10) 代表允许延迟的时间大小
dataStream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<Event>(Time.seconds(10)) {
//重写 BoundedOutOfOrdernessTimestampExtractor 中的 extractTimestamp()抽象方法
@Override
public long extractTimestamp(Event event) {
return event.getTimestamp();
}
})
2、CustomWatermarkExtractor:这是一个自定义的周期性生成水印的类,在这个类里面的数据是 KafkaEvent。
3、AscendingTimestampExtractor:时间戳分配器和水印生成器,用于时间戳单调递增的数据流,如果数据流的时间戳不是单调递增,那么会有专门的处理方法,代码如下:
public final long extractTimestamp(T element, long elementPrevTimestamp) {
final long newTimestamp = extractAscendingTimestamp(element);
if (newTimestamp >= this.currentTimestamp) {
this.currentTimestamp = ne∏wTimestamp;
return newTimestamp;
} else {
violationHandler.handleViolation(newTimestamp, this.currentTimestamp);
return newTimestamp;
}
}
4、IngestionTimeExtractor:依赖于机器系统时间,它在 extractTimestamp 和 getCurrentWatermark 方法中是根据 System.currentTimeMillis() 来获取时间的,而不是根据事件的时间,如果这个时间分配器是在数据源进 Flink 后分配的,那么这个时间就和 Ingestion Time 一致了,所以命名也取的就是叫 IngestionTimeExtractor。
注意:
1、使用这种方式周期性生成水印的话,你可以通过 env.getConfig().setAutoWatermarkInterval(...); 来设置生成水印的间隔(每隔 n 毫秒)。
2、通常建议在数据源(source)之后就进行生成水印,或者做些简单操作比如 filter/map/flatMap 之后再生成水印,越早生成水印的效果会更好,也可以直接在数据源头就做生成水印。比如你可以在 source 源头类中的 run() 方法里面这样定义。
@Override
public void run(SourceContext<MyType> ctx) throws Exception {
while (/* condition */) {
MyType next = getNext();
ctx.collectWithTimestamp(next, next.getEventTimestamp());
if (next.hasWatermarkTime()) {
ctx.emitWatermark(new Watermark(next.getWatermarkTime()));
}
}
}
六、Flink 常用的 Source Connector 和 Sink Connector 介绍
Flink Job 的大致结构就是 Source ——> Transformation ——> Sink。

6.1、Data Source 简介
Flink 做为一款流式计算框架,它可用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即处理实时的数据流(做计算操作),然后将处理后的数据实时下发,只要数据源源不断过来,Flink 就能够一直计算下去。
Flink 中可以使用 StreamExecutionEnvironment.addSource(sourceFunction) 来为程序添加数据来源。
Flink 已经提供了若干实现好了的 source function,当然你也可以通过实现 SourceFunction 来自定义非并行的 source 或者实现 ParallelSourceFunction 接口或者扩展 RichParallelSourceFunction 来自定义并行的 source。
6.2、常用的 Data Source
StreamExecutionEnvironment 中可以使用如下图所示的这些已实现的 Stream Source。
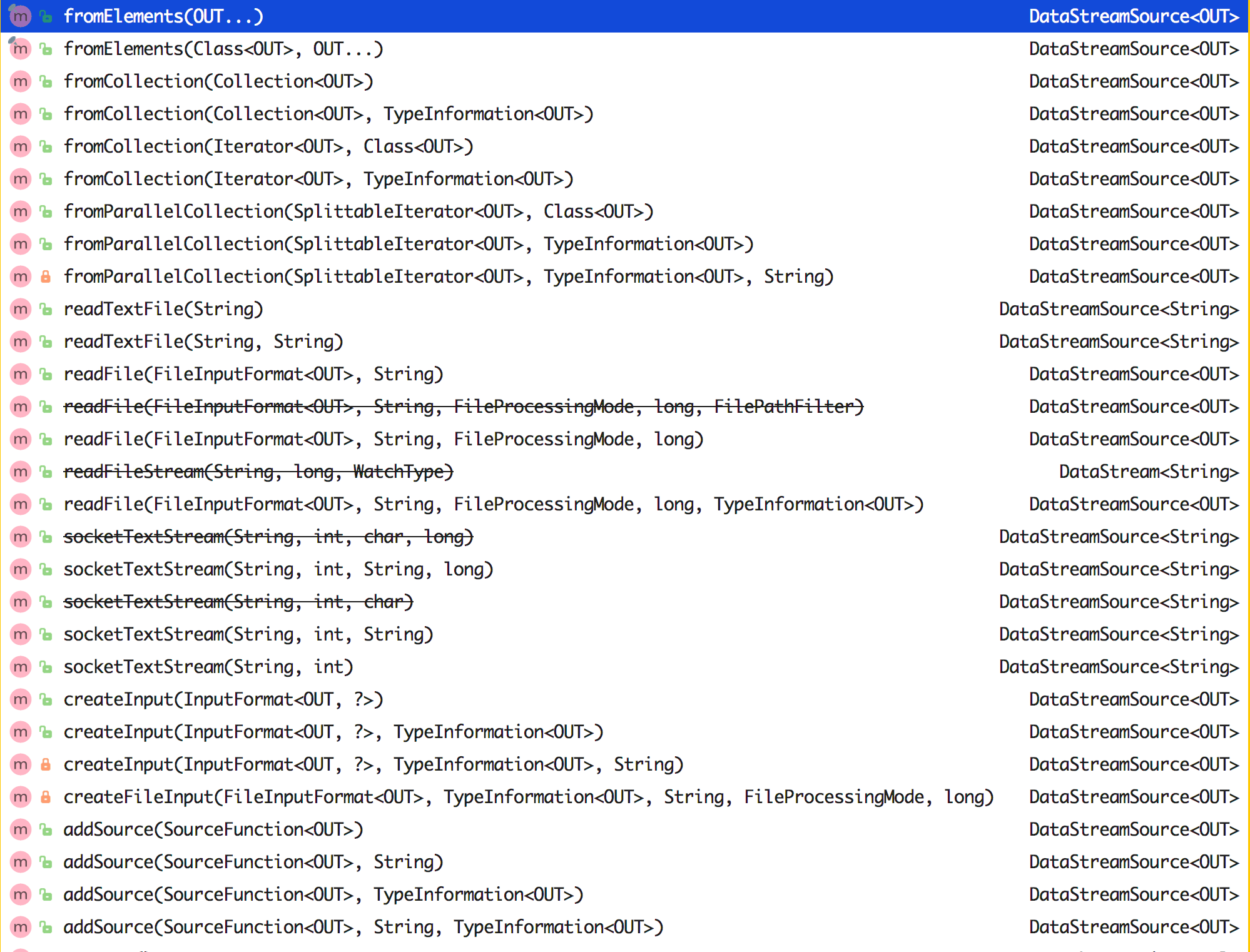
总的来说可以分为集合、文件、Socket、自定义四大类。
基于集合
基于集合的有下面五种方法:
1、fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
2、fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
3、fromElements(T ...) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
4、fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
5、generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
基于文件
基于文件的有下面三种方法:
1、readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<String> text = env.readTextFile("file:///path/to/file");
2、readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
3、readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<MyEvent> stream = env.readFile(
myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100,
FilePathFilter.createDefaultFilter(), typeInfo);
实现:
在具体实现上,Flink 把文件读取过程分为两个子任务,即目录监控和数据读取。每个子任务都由单独的实体实现。目录监控由单个非并行(并行度为1)的任务执行,而数据读取由并行运行的多个任务执行。后者的并行性等于作业的并行性。单个目录监控任务的作用是扫描目录(根据 watchType 定期扫描或仅扫描一次),查找要处理的文件并把文件分割成切分片(splits),然后将这些切分片分配给下游 reader。reader 负责读取数据。每个切分片只能由一个 reader 读取,但一个 reader 可以逐个读取多个切分片。
重要注意:
如果 watchType 设置为 FileProcessingMode.PROCESS_CONTINUOUSLY,则当文件被修改时,其内容将被重新处理。这会打破“exactly-once”语义,因为在文件末尾附加数据将导致其所有内容被重新处理。
如果 watchType 设置为 FileProcessingMode.PROCESS_ONCE,则 source 仅扫描路径一次然后退出,而不等待 reader 完成文件内容的读取。当然 reader 会继续阅读,直到读取所有的文件内容。关闭 source 后就不会再有检查点。这可能导致节点故障后的恢复速度较慢,因为该作业将从最后一个检查点恢复读取。
基于 Socket
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("localhost", 9999) // 监听 localhost 的 9999 端口过来的数据
.flatMap(new Splitter())
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
自定义
addSource - 添加一个新的 source function。例如,你可以用 addSource(new FlinkKafkaConsumer011<>(...)) 从 Apache Kafka 读取数据。
说说上面几种的特点
1、基于集合:有界数据集,更偏向于本地测试用
2、基于文件:适合监听文件修改并读取其内容
3、基于 Socket:监听主机的 host port,从 Socket 中获取数据
4、自定义 addSource:大多数的场景数据都是无界的,会源源不断过来。比如去消费 Kafka 某个 topic 上的数据,这时候就需要用到这个 addSource,可能因为用的比较多的原因吧,Flink 直接提供了 FlinkKafkaConsumer011 等类可供你直接使用。你可以去看看 FlinkKafkaConsumerBase 这个基础类,它是 Flink Kafka 消费的最根本的类。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<KafkaEvent> input = env
.addSource(
new FlinkKafkaConsumer011<>(
parameterTool.getRequired("input-topic"), //从参数中获取传进来的 topic
new KafkaEventSchema(),
parameterTool.getProperties())
.assignTimestampsAndWatermarks(new CustomWatermarkExtractor()));
Flink 目前支持的 Source 如下图所示:
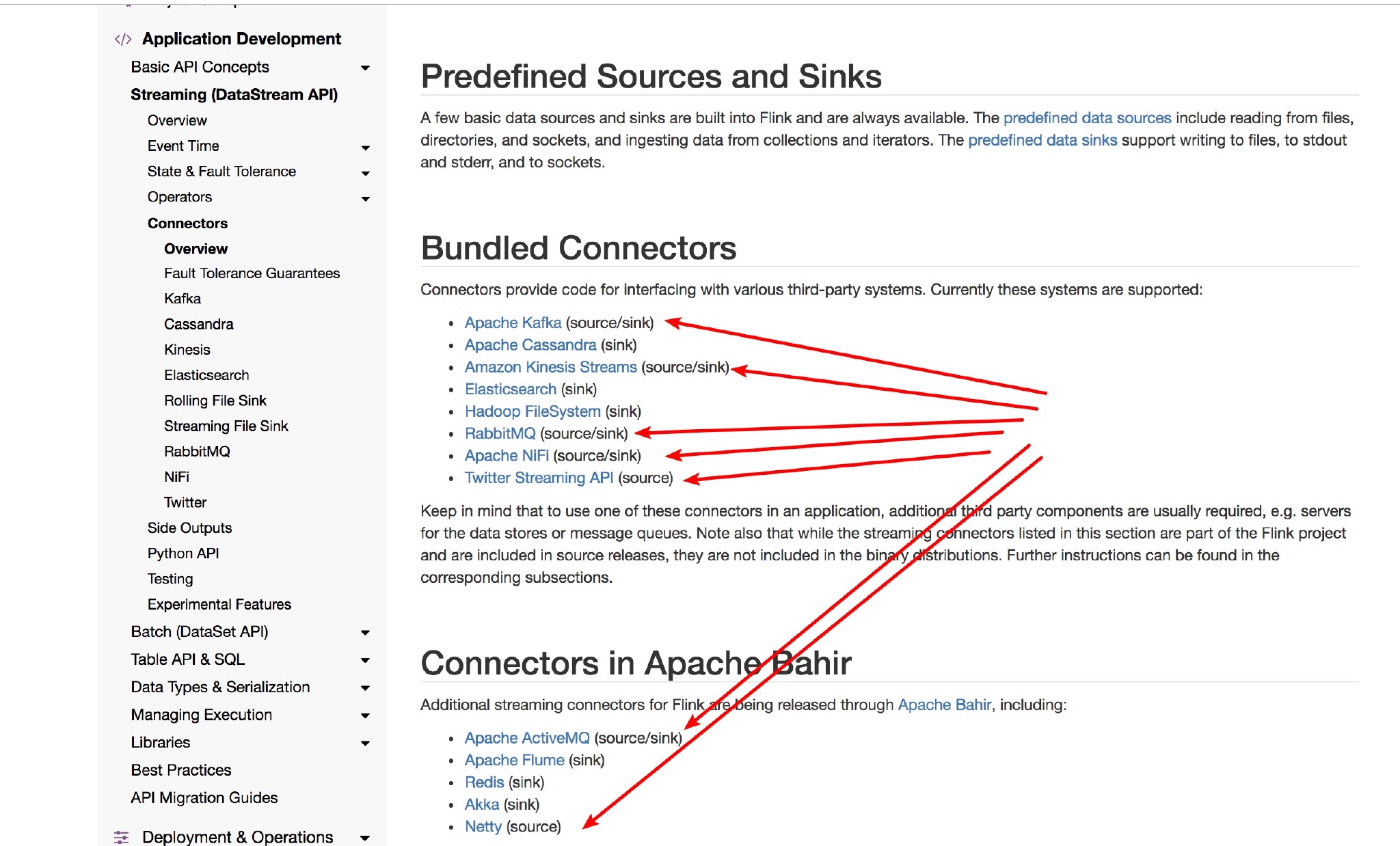
七、使用 Side Output 分流
通常,在 Kafka 的 topic 中会有很多数据,这些数据虽然结构是一致的,但是类型可能不一致,举个例子:Kafka 中的监控数据有很多种:机器、容器、应用、中间件等,如果要对这些数据分别处理,就需要对这些数据流进行一个拆分,那么在 Flink 中该怎么完成这需求呢,有如下这些方法。
7.1、使用 Filter 分流
使用 filter 算子根据数据的字段进行过滤分成机器、容器、应用、中间件等。伪代码如下:
DataStreamSource<MetricEvent> data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator<MetricEvent> machineData = data.filter(m -> "machine".equals(m.getTags().get("type"))); //过滤出机器的数据
SingleOutputStreamOperator<MetricEvent> dockerData = data.filter(m -> "docker".equals(m.getTags().get("type"))); //过滤出容器的数据
SingleOutputStreamOperator<MetricEvent> applicationData = data.filter(m -> "application".equals(m.getTags().get("type"))); //过滤出应用的数据
SingleOutputStreamOperator<MetricEvent> middlewareData = data.filter(m -> "middleware".equals(m.getTags().get("type"))); //过滤出中间件的数据
7.2、使用 Split 分流
先在 split 算子里面定义 OutputSelector 的匿名内部构造类,然后重写 select 方法,根据数据的类型将不同的数据放到不同的 tag 里面,这样返回后的数据格式是 SplitStream,然后要使用这些数据的时候,可以通过 select 去选择对应的数据类型,伪代码如下:
DataStreamSource<MetricEvent> data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SplitStream<MetricEvent> splitData = data.split(new OutputSelector<MetricEvent>() {
@Override
public Iterable<String> select(MetricEvent metricEvent) {
List<String> tags = new ArrayList<>();
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
tags.add("machine");
break;
case "docker":
tags.add("docker");
break;
case "application":
tags.add("application");
break;
case "middleware":
tags.add("middleware");
break;
default:
break;
}
return tags;
}
});
DataStream<MetricEvent> machine = splitData.select("machine");
DataStream<MetricEvent> docker = splitData.select("docker");
DataStream<MetricEvent> application = splitData.select("application");
DataStream<MetricEvent> middleware = splitData.select("middleware");
7.3、使用 Side Output 分流
要使用 Side Output 的话,首先需要做的是定义一个 OutputTag 来标识 Side Output,代表这个 Tag 是要收集哪种类型的数据,如果是要收集多种不一样类型的数据,那么你就需要定义多种 OutputTag。要完成本节前面的需求,需要定义 4 个 OutputTag,如下:
//创建 output tag
private static final OutputTag<MetricEvent> machineTag = new OutputTag<MetricEvent>("machine") {
};
private static final OutputTag<MetricEvent> dockerTag = new OutputTag<MetricEvent>("docker") {
};
private static final OutputTag<MetricEvent> applicationTag = new OutputTag<MetricEvent>("application") {
};
private static final OutputTag<MetricEvent> middlewareTag = new OutputTag<MetricEvent>("middleware") {
};
定义好 OutputTag 后,可以使用下面几种函数来处理数据:
- ProcessFunction
- KeyedProcessFunction
- CoProcessFunction
- ProcessWindowFunction
- ProcessAllWindowFunction
在利用上面的函数处理数据的过程中,需要对数据进行判断,将不同种类型的数据存到不同的 OutputTag 中去,如下代码所示:
DataStreamSource<MetricEvent> data = KafkaConfigUtil.buildSource(env); //从 Kafka 获取到所有的数据流
SingleOutputStreamOperator<MetricEvent> sideOutputData = data.process(new ProcessFunction<MetricEvent, MetricEvent>() {
@Override
public void processElement(MetricEvent metricEvent, Context context, Collector<MetricEvent> collector) throws Exception {
String type = metricEvent.getTags().get("type");
switch (type) {
case "machine":
context.output(machineTag, metricEvent);
case "docker":
context.output(dockerTag, metricEvent);
case "application":
context.output(applicationTag, metricEvent);
case "middleware":
context.output(middlewareTag, metricEvent);
default:
collector.collect(metricEvent);
}
}
});
好了,既然上面已经将不同类型的数据放到不同的 OutputTag 里面了,那么该如何去获取呢?可以使用 getSideOutput 方法来获取不同 OutputTag 的数据,比如:
DataStream<MetricEvent> machine = sideOutputData.getSideOutput(machineTag);
DataStream<MetricEvent> docker = sideOutputData.getSideOutput(dockerTag);
DataStream<MetricEvent> application = sideOutputData.getSideOutput(applicationTag);
DataStream<MetricEvent> middleware = sideOutputData.getSideOutput(middlewareTag);
评论