
如何保障kafka消费的顺序性,宗旨就是通过将消息绑定到定向的分区或者队列来保证顺序性,通过增加分区或者线程来提升消费能力。
一、生产者
要保证生产者发消息发的是顺序性的消息,发消息的时候指定一下key相同的key会发送到一个分区中,而分区时有序的在发消息的时候多个操作(下单,支付)保证顺序的话,保证这些操作在一个topic下的同一个分区,发送的时候指定key相同的key会去到同一个分区中,kafkaTemplate.send(topic,partition,key,data)有参数可以指定key。意思就是保证发消息的时候有序,发到同一个分区中,那么消费的时候也是有序的,因为分区可以理解为一个队列,消息先进先出。
当有消息被生产出来的时候,如果没有指定分区或者指定 key ,那么消费会按照【轮询】的方式均匀地分配到所有可用分区中,但不一定按照分区顺序来分配。
在 Kafka 中消费者可以订阅一个或多个主题,并被分配一个或多个分区。
如果一个消费者消费了多个分区,某些场景下消费者需要顺序地消费消息,但消息并不是按照顺序分配给分区的,所以就不一定能够保证消息消费的全局顺序性。
如何尽可能地保证消息消费的全局顺序性?(即这些消息具有因果关系)要想消费消息 B 必须先消费消息 A。
要注意的是,Kafka 的设计目标是提供高吞吐量和低延迟,而不是强制保证全局有序性。
所以该文探讨的是需要强调全局顺序性场景下的 Kafka 应用。
二、单分区
最简单粗暴的方法,虽然 Kafka 不能保证全局消费顺序性,但是能够保证分区内的消息顺序性。
可以只创建一个分区,并让消费者消费这个分区,这样就能够保证消费的消息是有序的。
但是这样做大大降低了吞吐量和处理效率,容易使得性能出现瓶颈。
三、基于key
在 Kafka 中,基于 key 的消息分配策略是通过消息中的键(key)来确定消息发送到哪个分区。
当生产者发送消息时,可以指定一个键(key),Kafka 使用这个键通过哈希算法来确定消息被发送到哪个分区。
四、代码
实现顺序性原理:消息发送的时候保证有序,设置相同的key会把消息投递到同一个分区的topic中,再由一个消费者来消费该分区topic。
topic: "topic_query_p3r1" 分配了三个partition分区。
4.1、producer 投递顺序消息
同一组行为设置相同的key,会把这组数据投递到同一分区topic中。
/**
* 投递顺序性消息,根据用户id做取模推送到不同分区的topic中
* 相同的key推送到同一分区中
* 第一个参数:topic
* 第二个参数:key
* 第三个参数:发送的消息内容
* 三个参数全部是sring类型
*/
@RequestMapping("/kafka2")
public String testKafka2() {
for (int userId = 0; userId < 3; userId++) {
kafkaTemplate.send("topic_query_p3r1", userId + "", "insert" + userId);
kafkaTemplate.send("topic_query_p3r1", userId + "", "update" + userId);
kafkaTemplate.send("topic_query_p3r1", userId + "", "delete" + userId);
}
return null;
4.2、consumer 消费顺序消息
前提是生产者发消息的时候指定key了。
1、直接进行消费
因为投递的相同行为的消息是有序的,所以直接消费也不会有问题。
/**
* 消费topic_query_p3r1主题,ConsumerGroupId1消费组
*/
@KafkaListener(topics = "topic_query_p3r1", groupId = "ConsumerGroupId1")
public void p3r2ConsumerGroupId0(ConsumerRecord<?, ?> consumer) throws InterruptedException {
System.out.println("消费者A topic名称:" + consumer.topic() +
", key:" + consumer.key() +
", value:" + consumer.value() +
", 分区位置:" + consumer.partition() +
", 下标" + consumer.offset()+" "+Thread.currentThread().getId());
Thread.sleep(10);
2、一个消费者来指定具体分区进行消费
指定具体分区来进行消费。
/**
* 消费者,解决消息顺序性
* 注解参数:partitions=0表示:只消费该主题中0分区的数据。
*/
@KafkaListener(topicPartitions = {@TopicPartition(topic = "topic_query_p3r1", partitions = {"0"})}, groupId = "ConsumerGroupId1")
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("消费者C topic名称:" + consumer.topic() +
",key:" + consumer.key() + "," +
",value:" + consumer.value() + "," +
"分区位置:" + consumer.partition() +
", 下标" + consumer.offset());
}
3、多个消费者来指定不同分区进行消费。
写多个消费者方法来分别指向不同分区,提高消费速度,但是此方法不灵活。
/**
* 消费0分区的topic_query_p3r1主题消费者,ConsumerGroupId1消费组
*/
@KafkaListener(topicPartitions = {@TopicPartition(topic = "topic_query_p3r1", partitions = {"0"})}, groupId = "ConsumerGroupId1")
public void p3r2ConsumerGroupId0(ConsumerRecord<?, ?> consumer) throws InterruptedException {
System.out.println("消费者A topic名称:" + consumer.topic() +
", key:" + consumer.key() +
", value:" + consumer.value() +
", 分区位置:" + consumer.partition() +
", 下标" + consumer.offset()+" "+Thread.currentThread().getId());
Thread.sleep(10);
}
/**
* 消费1分区的topic_query_p3r1主题消费者,ConsumerGroupId1消费组
*/
@KafkaListener(topicPartitions = {@TopicPartition(topic = "topic_query_p3r1", partitions = {"1"})}, groupId = "ConsumerGroupId1")
public void p3r2ConsumerGroupId1(ConsumerRecord<?, ?> consumer) throws InterruptedException {
System.out.println("消费者A topic名称:" + consumer.topic() +
", key:" + consumer.key() +
", value:" + consumer.value() +
", 分区位置:" + consumer.partition() +
", 下标" + consumer.offset()+" "+Thread.currentThread().getId());
Thread.sleep(10);
}
/**
* 消费2分区的topic_query_p3r1主题消费者,ConsumerGroupId1消费组
*/
@KafkaListener(topicPartitions = {@TopicPartition(topic = "topic_query_p3r1", partitions = {"2"})}, groupId = "ConsumerGroupId1")
public void p3r2ConsumerGroupId2(ConsumerRecord<?, ?> consumer) throws InterruptedException {
System.out.println("消费者A topic名称:" + consumer.topic() +
", key:" + consumer.key() +
", value:" + consumer.value() +
", 分区位置:" + consumer.partition() +
", 下标" + consumer.offset()+" "+Thread.currentThread().getId());
Thread.sleep(10);
}
4、多线程顺序消费
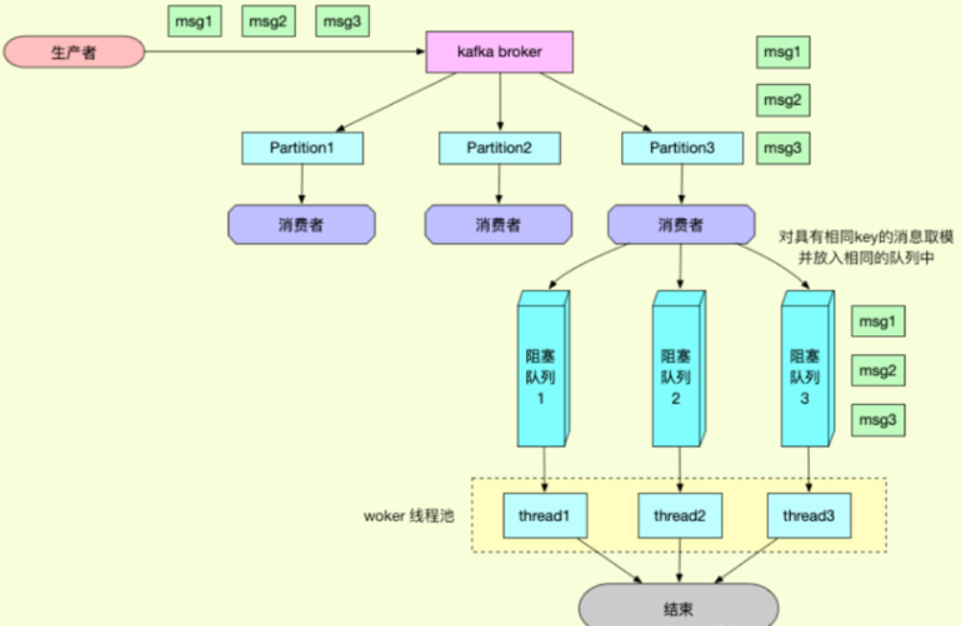
@RestController
@Slf4j
public class ShunXuConsumerMoreThread implements ApplicationRunner {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
// 使用两个内存队列
final int queueLingth = 2;
// 创建两个内存队列
Queue<Map> queueA = new ConcurrentLinkedQueue<>();
Queue<Map> queueB = new ConcurrentLinkedQueue<>();
/**
* 投递顺序性消息,根据用户id做取模推送到不同分区的topic中
* 相同的key推送到相同的分区中
*/
@RequestMapping("/kafka2")
public String testKafka2() {
for (int userId = 0; userId < 300; userId++) {
kafkaTemplate.send("topic_query_2", userId + "", "insert" + userId);
kafkaTemplate.send("topic_query_2", userId + "", "update" + userId);
kafkaTemplate.send("topic_query_2", userId + "", "delete" + userId);
}
return null;
}
/**
* 主题消费者-把相同行为的数据放到同一内存队列中
*/
@KafkaListener(topics = "topic_query_2", groupId = "ConsumerGroupId1")
public void p3r2ConsumerGroupId0(ConsumerRecord<?, ?> consumer){
// 1.封装消息参数
Map param = new HashMap();
param.put("topic", consumer.topic());
param.put("key", consumer.key());
param.put("value", consumer.value());
param.put("p", consumer.partition());
// 2.把相同行为(key)数据添加到同一内存队列中
int queueHash = consumer.key().hashCode() % queueLingth;
if (queueHash == 0) {
queueA.add(param);
}
if (queueHash == 1) {
queueB.add(param);
}
}
// 开启两个线程消费内存队列中的消息 ApplicationRunner接口常用于项目启动后,(也就是ApringApplication.run()执行结束),立马执行某些逻辑。
//这里是立即启动两个线程
@Override
public void run(ApplicationArguments args) {
new Thread() {
@Override
public void run() {
while (true) {
if (queueA.size() > 0) {
Map poll = queueA.poll();
//业务逻辑
System.out.println("Thrend-Id: " + Thread.currentThread().getId() +
" topic:" + poll.get("topic") +
" key:" + poll.get("key") +
" value:" + poll.get("value") +
" partition:" + poll.get("p"));
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}.start();
new Thread() {
@Override
public void run() {
while (true) {
if (queueB.size() > 0) {
Map poll = queueB.poll();
//业务逻辑
System.out.println("Thrend-Id: " + Thread.currentThread().getId() + " topic:" + poll.get("topic") + " key:" + poll.get("key") + " value:" + poll.get("value") + " partition:" + poll.get("p"));
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
}.start();
}
}
此时消费是按照顺序的。
评论