
一、Kafka Broker 工作流程
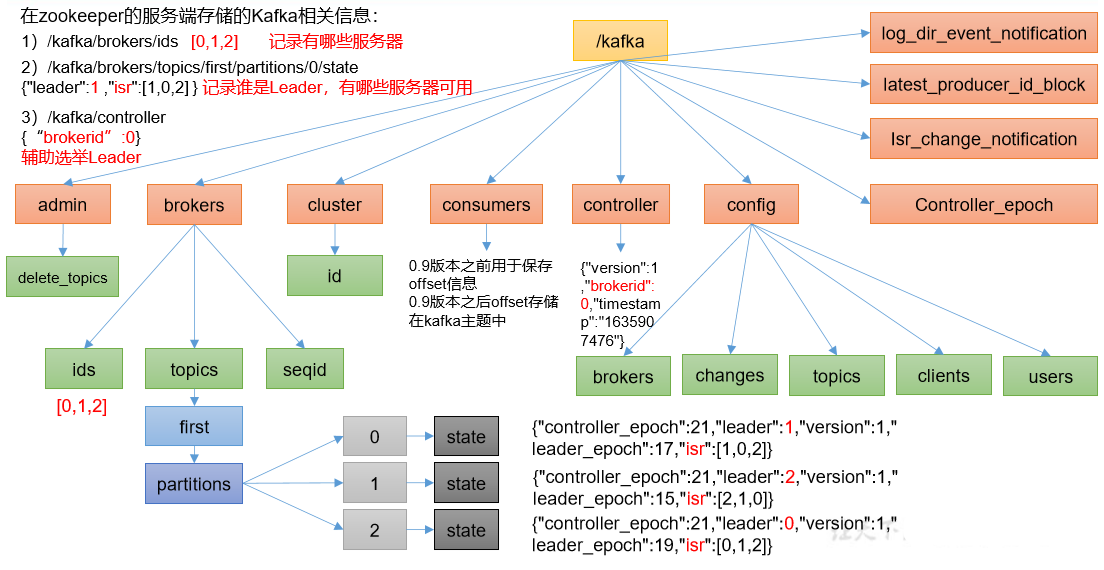
1.1、Zookeeper 存储的 Kafka 信息
(1)启动 Zookeeper 客户端。
bin/zkCli.sh
(2)通过 ls 命令可以查看 kafka 相关信息。
ls /kafka
Zookeeper 中存储的 Kafka 信息:
1.2、Kafka Broker 总体工作流程
1.2.1、模拟 Kafka 上下线,Zookeeper 中数据变化
(1)查看 /kafka/brokers/ids 路径上的节点。
[zk: localhost:2181 (CONNECTED) 2] ls /kafka/brokers/ids
[0, 1, 2]
(2)查看 /kafka/controller 路径上的数据。
[zk: localhost:2181 (CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
(3)查看 /kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181 (CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"isr":[0,1,2]}
(4)停止 hadoop104 上的 kafka。
bin/kafka-server-stop.sh
(5)再次查看 /kafka/brokers/ids 路径上的节点。
[zk: localhost:2181 (CONNECTED) 3] ls /kafka/brokers/ids [0, 1]
(6)再次查看 /kafka/controller 路径上的数据。
[zk: localhost:2181 (CONNECTED) 15] get /kafka/controller
{"version":1,"brokerid":0,"timestamp":"1637292471777"}
(7)再次查看 /kafka/brokers/topics/first/partitions/0/state 路径上的数据。
[zk: localhost:2181 (CONNECTED) 16] get /kafka/brokers/topics/first/partitions/0/state
{"controller_epoch":24,"leader":0,"version":1,"leader_epoch":18,"isr":[0,1]}
(8)启动 hadoop104 上的 kafka。
bin/kafka-server-start.sh daemon ./config/server.properties
(9)再次观察(1)、(2)、( 3)步骤中的内容。
1.3、Broker 重要参数
replica.lag.time.max.ms
ISR 中,如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值,默认 30s。auto.leader.rebalance.enable
默认是 true。 自动 Leader Partition 平衡。leader.imbalance.per.broker.percentage
默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。log.segment.bytes
Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分成块的大小,默认值 1G。log.index.interval.bytes
默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。log.retention.hours
Kafka 中数据保存的时间,默认 7 天。log.retention.minutes
Kafka 中数据保存的时间,分钟级别,默认关闭。log.retention.ms
Kafka 中数据保存的时间,毫秒级别,默认关闭。log.retention.check.interval.ms
检查数据是否保存超时的间隔,默认是 5 分钟。log.retention.bytes
默认等于 - 1,表示无穷大。超过设置的所有日志总大小,删除最早的 segment。log.cleanup.policy
默认是 delete,表示所有数据启用删除策略;如果设置值为 compact,表示所有数据启用压缩策略。num.io.threads
默认是 8。负责写磁盘的线程数。整个参数值要占总核数的 50%。num.replica.fetchers
副本拉取线程数,这个参数占总核数的 50% 的 1/3num.network.threads
默认是 3。数据传输线程数,这个参数占总核数的 50% 的 2/3 。log.flush.interval.messages
强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。log.flush.interval.ms
每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。
二、生产经验 —— 节点服役和退役
2.1、服役新节点
2.1.1、新节点准备
(1)关闭 hadoop104,并右键执行克隆操作。
(2)开启 hadoop105,并修改 IP 地址。
[root@hadoop104 ~]# vim /etc/sysconfig/network-scripts/ifcfgens33
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.10.105
PREFIX=24
GATEWAY=192.168.10.2
DNS1=192.168.10.2
(3)在 hadoop105 上,修改主机名称为 hadoop105。
[root@hadoop104 ~]# vim /etc/hostname hadoop105
(4)重新启动 hadoop104、hadoop105。
(5)修改 haodoop105 中 kafka 的 broker.id 为 3。
(6)删除 hadoop105 中 kafka 下的 datas 和 logs。
[atguigu@hadoop105 kafka]$ rm -rf datas/* logs/*
(7)启动 hadoop102、hadoop103、hadoop104 上的 kafka 集群。
[atguigu@hadoop102 ~]$ zk.sh start
[atguigu@hadoop102 ~]$ kf.sh start
(8)单独启动 hadoop105 中的 kafka。
[atguigu@hadoop105 kafka]$ bin/kafka-server-start.sh daemon ./config/server.properties
2.1.2、执行负载均衡操作
(1)创建一个要均衡的主题。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{ "topics": [
{"topic": "first"}
],
"version": 1 }
(2)生成一个负载均衡的计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2,3" --generate
Current partition replica assignment {"version":1,"partitions":[{"topic":"first","partition":0,"replic as":[0,2,1],"log_dirs":["any","any","any"]},{"topic":"first","par tition":1,"replicas":[2,1,0],"log_dirs":["any","any","any"]},{"to pic":"first","partition":2,"replicas":[1,0,2],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"first","partition":0,"replic as":[2,3,0],"log_dirs":["any","any","any"]},{"topic":"first","par tition":1,"replicas":[3,0,1],"log_dirs":["any","any","any"]},{"to pic":"first","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]}]} (
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2、broker3 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{
"version": 1,
"partitions": [{
"topic": "first",
"partition": 0,
"replic as": [2, 3, 0],
"log_dirs": ["any", "any", "any"]
}, {
"topic": "first",
"par tition": 1,
"replicas": [3, 0, 1],
"log_dirs": ["any", "any", "any"]
}, {
"to pic": "first",
"partition": 2,
"replicas": [0, 1, 2],
"log_dirs": ["any", "any", "any"]
}]
}
(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
Status of partition reassignment:
Reassignment of partition first-0 is complete.
Reassignment of partition first-1 is complete.
Reassignment of partition first-2 is complete.
Clearing broker-level throttles on brokers 0,1,2,3
Clearing topic-level throttles on topic first
2.2、退役旧节点
2.2.1、执行负载均衡操作
先按照退役一台节点,生成执行计划,然后按照服役时操作流程执行负载均衡。
(1)创建一个要均衡的主题。
[atguigu@hadoop102 kafka]$ vim topics-to-move.json
{ "topics": [
{"topic": "first"}
],
"version": 1 }
(2)创建执行计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --topics-to-move-json-file topics-to-move.json --broker-list "0,1,2" --generate
(3)创建副本存储计划(所有副本存储在 broker0、broker1、broker2 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
{"version":1,"partitions":[{"topic":"first","partition":0,"replic as":[2,0,1],"log_dirs":["any","any","any"]},{"topic":"first","par tition":1,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"to pic":"first","partition":2,"replicas":[1,2,0],"log_dirs":["any","any","any"]}]}
(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
2.2.2、执行停止命令
在 hadoop105 上执行停止命令即可。
[atguigu@hadoop105 kafka]$ bin/kafka-server-stop.sh
三、Kafka 副本
3.1、副本基本信息
(1)Kafka 副本作用:提高数据可靠性。
(2)Kafka 默认副本 1 个,生产环境一般配置为 2 个,保证数据可靠性;太多副本会增加磁盘存储空间,增加网络上数据传输,降低效率。
(3)Kafka 中副本分为:Leader 和 Follower。Kafka 生产者只会把数据发往 Leader,然后 Follower 找 Leader 进行同步数据。
(4)Kafka 分区中的所有副本统称为 AR(Assigned Repllicas)。
AR = ISR + OSR
ISR,表示和 Leader 保持同步的 Follower 集合。如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms 参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。
OSR,表示 Follower 与 Leader 副本同步时,延迟过多的副本。
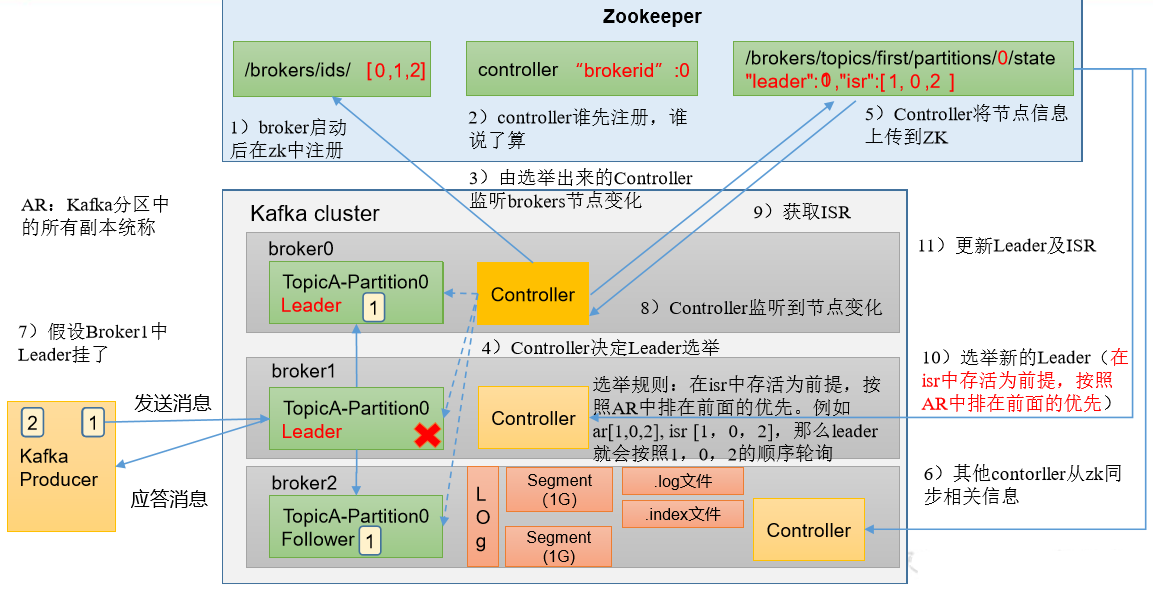
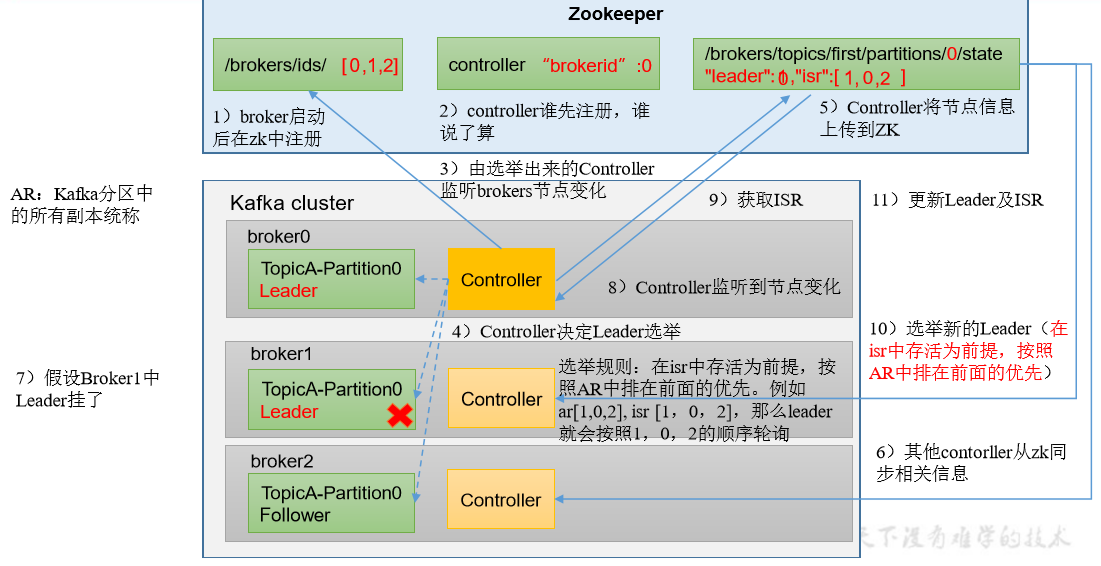
3.2、Leader 选举流程
Kafka 集群中有一个 broker 的 Controller 会被选举为 Controller Leader,负责管理集群 broker 的上下线,所有 topic 的分区副本分配和 Leader 选举等工作。
Controller 的信息同步工作是依赖于 Zookeeper 的。
(1)创建一个新的 topic,4 个分区,4 个副本
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic atguigu1 --partitions 4 --replication-factor 4 Created topic atguigu1.
(2)查看 Leader 分布情况
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu1
(3)停止掉 hadoop105 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop105 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu1
(4)停止掉 hadoop104 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop104 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu1
(5)启动 hadoop105 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop105 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu1
(6)启动 hadoop104 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop104 kafka]$ bin/kafka-server-start.sh -daemon config/server.properties
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu1
(7)停止掉 hadoop103 的 kafka 进程,并查看 Leader 分区情况
[atguigu@hadoop103 kafka]$ bin/kafka-server-stop.sh
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic atguigu1
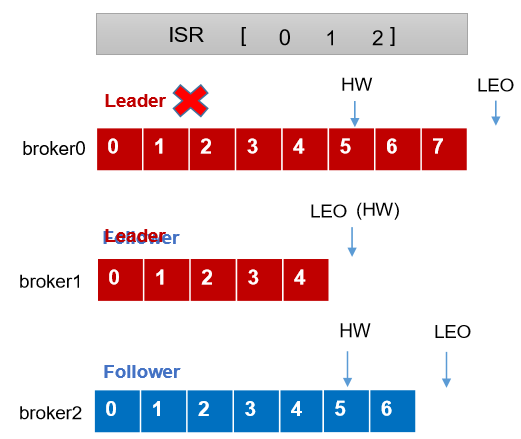
3.3、Leader 和 Follower 故障处理细节
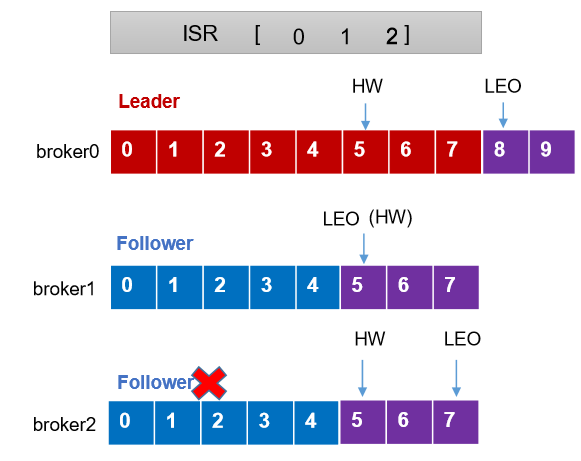
LEO(Log End Offset):每个副本的最后一个 offset,LEO 其实就是最新的 offset + 1。
HW(High Watermark):所有副本中最小的 LEO 。
3.3.1、Follower 故障
(1) Follower 发生故障后会被临时踢出 ISR。
(2) 这个期间 Leader 和 Follower 继续接收数据。
(3)待该 Follower 恢复后,Follower 会读取本地磁盘记录的 上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 Leader 进行同步。
(4)等该 Follower 的 LEO 大于等于该 Partition 的 HW,即 Follower 追上 Leader 之后,就可以重新加入 ISR 了。
3.3.2、Leader 故障
(1) Leader 发生故障之后,会从 ISR 中选出一个新的 Leader
(2)为保证多个副本之间的数据一致性,其余的 Follower 会先 将各自的 log 文件高于 HW 的部分截掉,然后从新的 Leader 同步数据。
注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
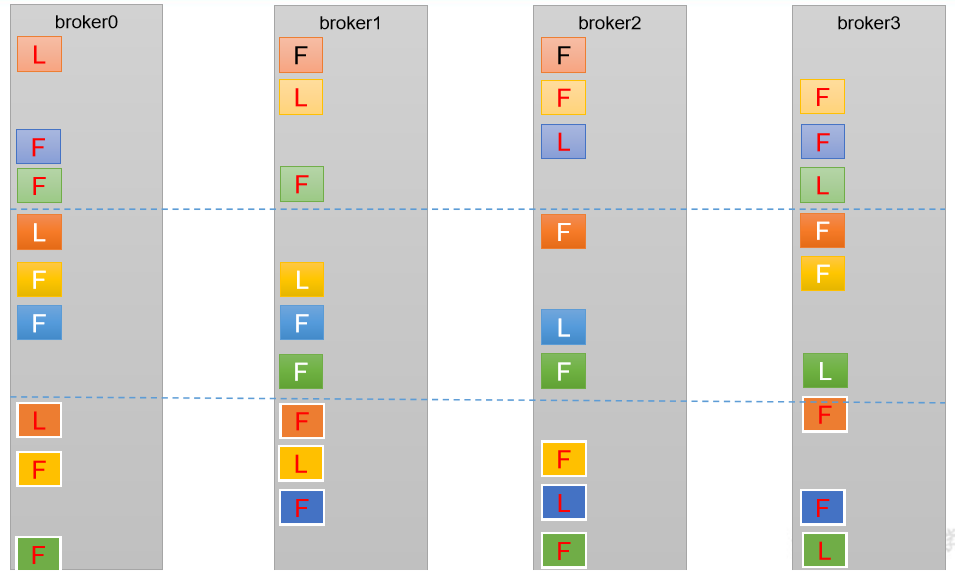
3.4、分区副本分配
如果 kafka 服务器只有 4 个节点,那么设置 kafka 的分区数大于服务器台数,在 kafka 底层如何分配存储副本呢?
3.4.1、创建 16 分区,3 个副本
(1)创建一个新的 topic,名称为 second。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 16 --replication-factor 3 -topic second
(2)查看分区和副本情况。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic second
分区副本分配
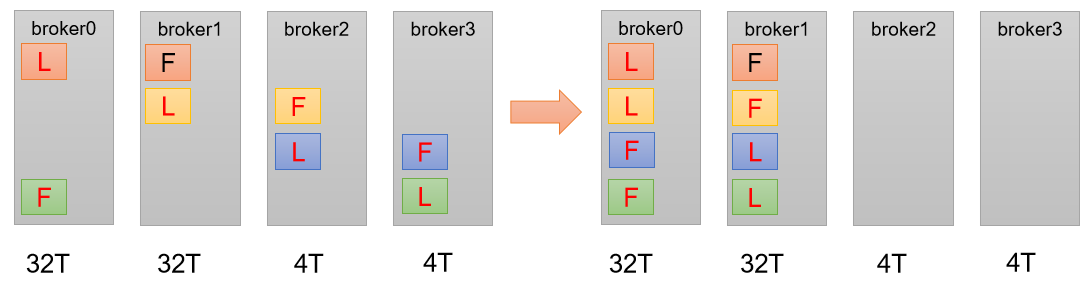
3.5、生产经验 —— 手动调整分区副本存储
在生产环境中,每台服务器的配置和性能不一致,但是 Kafka 只会根据自己的代码规则创建对应的分区副本,就会导致个别服务器存储压力较大。所有需要手动调整分区副本的存储。
需求:创建一个新的 topic,4 个分区,两个副本,名称为 three。将该 topic 的所有副本都存储到 broker0 和 broker1 两台服务器上。
手动调整分区副本存储的步骤如下:
(1)创建一个新的 topic,名称为 three。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 4 --replication-factor 2 -topic three
(2)查看分区副本存储情况。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic three
(3)创建副本存储计划(所有副本都指定存储在 broker0、broker1 中) 。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{
"version": 1,
"partitions": [{
"topic": "three",
"partition": 0,
"replicas": [0, 1]
}, {
"topic": "three",
"partition": 1,
"replicas": [0, 1]
}, {
"topic": "three",
"partition": 2,
"replicas": [1, 0]
}, {
"topic": "three",
"partition": 3,
"replicas": [1, 0]
}]
}
(4)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
(5)验证副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --verify
(6)查看分区副本存储情况。
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic three
3.6、生产经验 ——Leader Partition 负载平衡
正常情况下,Kafka 本身会自动把 Leader Partition 均匀分散在各个机器上,来保证每台机器的读写吞吐量都是均匀的。但是如果某 些 broker 宕机,会导致 Leader Partition 过于集中在其他少部分几台 broker 上,这会导致少数几台 broker 的读写请求压力过高,其他宕机的 broker 重启之后都是 follower partition,读写请求很低,造成集群负载不均衡。
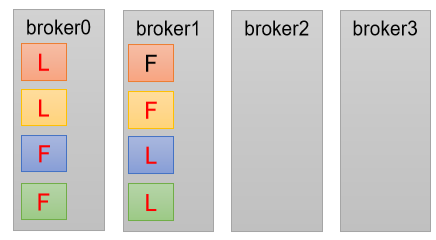
auto.leader.rebalance.enable,默认是 true。 自动 Leader Partition 平衡leader.imbalance.per.broker.percentage, 默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。leader.imbalance.check.interval.seconds, 默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
下面拿一个主题举例说明,假设集群只有一个主题如下图所示:

针对 broker0 节点,分区 2 的 AR 优先副本是 0 节点,但是 0 节点却不是 Leader 节点, 所以不平衡数加 1,AR 副本总数是 4 所以 broker0 节点不平衡率为 1/4>10%,需要再平衡。
broker2 和 broker3 节点和 broker0 不平衡率一样,需要再平衡。 Broker1 的不平衡数为 0,不需要再平衡。
auto.leader.rebalance.enable
默认是 true。 自动 Leader Partition 平衡。生产环境中,leader 重选举的代价比较大,可能会带来性能影响,建议设置为 false 关闭。leader.imbalance.per.broker.percentage
默认是 10%。每个 broker 允许的不平衡的 leader 的比率。如果每个 broker 超过了这个值,控制器会触发 leader 的平衡。leader.imbalance.check.interval.seconds
默认值 300 秒。检查 leader 负载是否平衡的间隔时间。
3.7、生产经验 —— 增加副本因子
在生产环境当中,由于某个主题的重要等级需要提升,我们考虑增加副本。副本数的增加需要先制定计划,然后根据计划执行。
1)创建 topic
[atguigu@hadoop102 kafka]$ bin/kafka-topics.sh --bootstrap-server hadoop102:9092 --create --partitions 3 --replication-factor 1 -topic four
2)手动增加副本存储
(1)创建副本存储计划(所有副本都指定存储在 broker0、broker1、broker2 中)。
[atguigu@hadoop102 kafka]$ vim increase-replication-factor.json
输入如下内容:
{
"version": 1,
"partitions": [{
"topic": "four",
"partition": 0,
"replicas": [0, 1, 2]
}, {
"topic": "four",
"partition": 1,
"replicas": [0, 1, 2]
}, {
"t opic": "four",
"partition": 2,
"replicas": [0, 1, 2]
}]
}
(2)执行副本存储计划。
[atguigu@hadoop102 kafka]$ bin/kafka-reassign-partitions.sh -bootstrap-server hadoop102:9092 --reassignment-json-file increase-replication-factor.json --execute
四、文件存储
4.1、文件存储机制
4.1.1、Topic 数据的存储机制
Topic 是逻辑上的概念,而 partition 是物理上的概念,每个 partition 对应于一个 log 文件,该 log 文件中存储的就是 Producer 生产的数据。Producer 生产的数据会被不断追加到该 log 文件末端,为防止 log 文件过大导致数据定位效率低下,Kafka 采取了分片和索引机制, 将每个 partition 分为多个 segment。每个 segment 包括:“.index” 文件、“.log” 文件和“.timeindex” 等文件。这些文件位于一个文件夹下,该 文件夹的命名规则为:topic 名称 + 分区序号,例如:first-0。
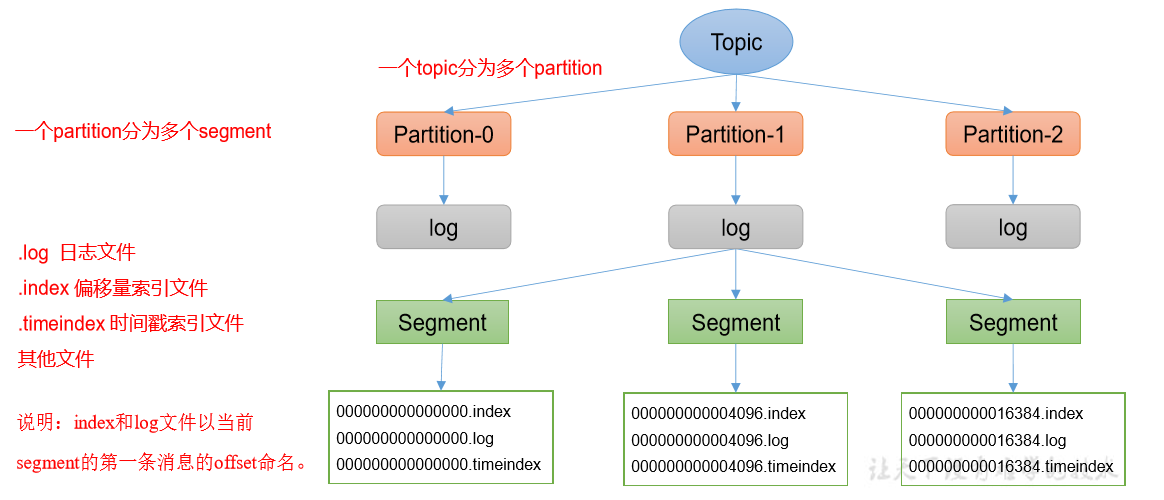
4.1.2、思考:Topic 数据到底存储在什么位置?
(1)启动生产者,并发送消息。
[atguigu@hadoop102 kafka]$ bin/kafka-console-producer.sh -bootstrap-server hadoop102:9092 --topic first >hello world
(2)查看 hadoop102(或者 hadoop103、hadoop104)的 /opt/module/kafka/datas/first-1(first-0、first-2)路径上的文件。
[atguigu@hadoop104 first-1]$ ls
00000000000000000092.index
00000000000000000092.log
00000000000000000092.snapshot
00000000000000000092.timeindex
leader-epoch-checkpoint
partition.metadata
(3)直接查看 log 日志,发现是乱码。
[atguigu@hadoop104 first-1]$ cat 00000000000000000092.log
\CYnF|©|©ÿ"ÿÿÿÿÿÿÿÿÿÿÿÿÿhello world
(4)通过工具查看 index 和 log 信息。
[atguigu@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.index
Dumping ./00000000000000000000.index
offset: 3 position: 152
[atguigu@hadoop104 first-1]$ kafka-run-class.sh kafka.tools.DumpLogSegments --files ./00000000000000000000.log
4.1.3、index 文件和 log 文件详解
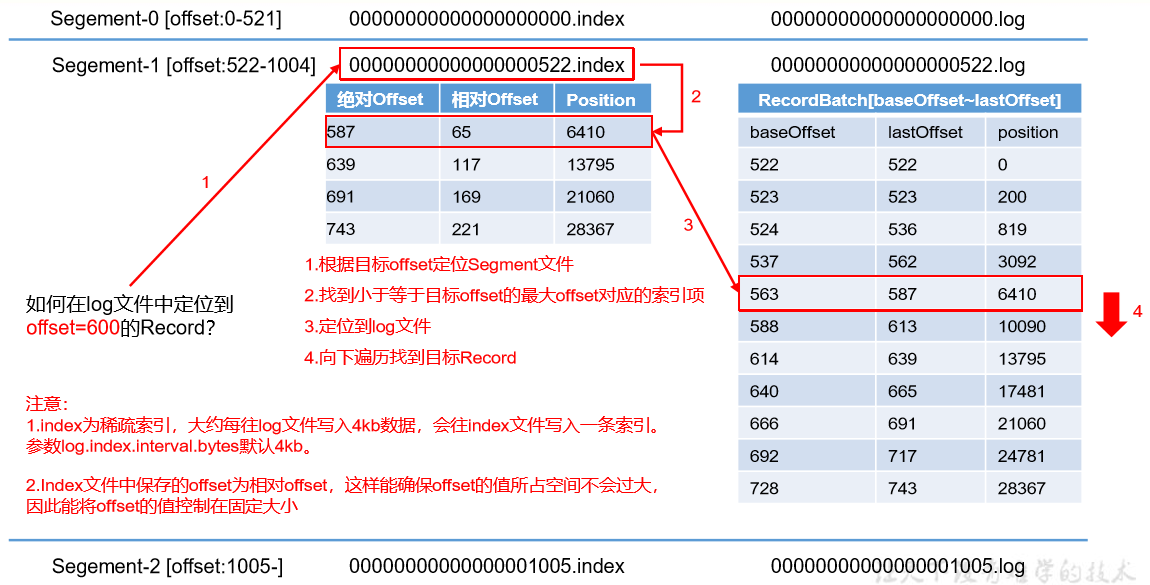
说明:日志存储参数配置
log.segment.bytes
Kafka 中 log 日志是分成一块块存储的,此配置是指 log 日志划分 成块的大小,默认值 1G。log.index.interval.bytes
默认 4kb,kafka 里面每当写入了 4kb 大小的日志(.log),然后就往 index 文件里面记录一个索引。 稀疏索引。
4.2、文件清理策略
Kafka 中默认的日志保存时间为 7 天,可以通过调整如下参数修改保存时间。
log.retention.hours,最低优先级小时,默认 7 天。log.retention.minutes,分钟。log.retention.ms,最高优先级毫秒。log.retention.check.interval.ms,负责设置检查周期,默认 5 分钟。
那么日志一旦超过了设置的时间,怎么处理呢?
Kafka 中提供的日志清理策略有 delete 和 compact 两种。
4.2.1、delete 日志删除:将过期数据删除
log.cleanup.policy = delete所有数据启用删除策略。
(1)基于时间:默认打开。以 segment 中所有记录中的最大时间戳作为该文件时间戳。
(2)基于大小:默认关闭。超过设置的所有日志总大小,删除最早的 segment。log.retention.bytes,默认等于 - 1,表示无穷大。
思考:如果一个 segment 中有一部分数据过期,一部分没有过期,怎么处理?
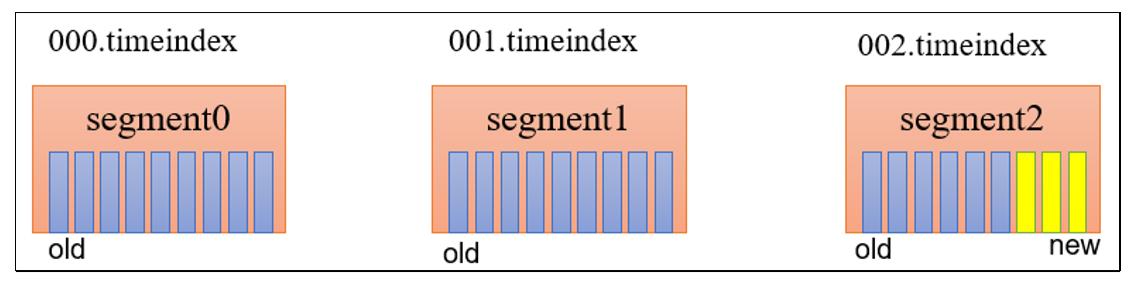
Kafka 的过期策略是以 segment 为单位,而不是以单条消息为单位。
只有当一个 segment 文件内所有消息都过期,这个 segment 才会被删除。
4.2.2、compact 日志压缩
compact 日志压缩:对于相同 key 的不同 value 值,只保留最后一个版本。
log.cleanup.policy = compact 所有数据启用压缩策略

压缩后的 offset 可能是不连续的,比如上图中没有 6,当从这些 offset 消费消息时,将会拿到比这个 offset 大 的 offset 对应的消息,实际上会拿到 offset 为 7 的消息,并从这个位置开始消费。
这种策略只适合特殊场景,比如消息的 key 是用户 ID,value 是用户的资料,通过这种压缩策略,整个消息集里就保存了所有用户最新的资料。
五、高效读写数据
1)Kafka 本身是分布式集群,可以采用分区技术,并行度高。
2)读数据采用稀疏索引,可以快速定位要消费的数据。
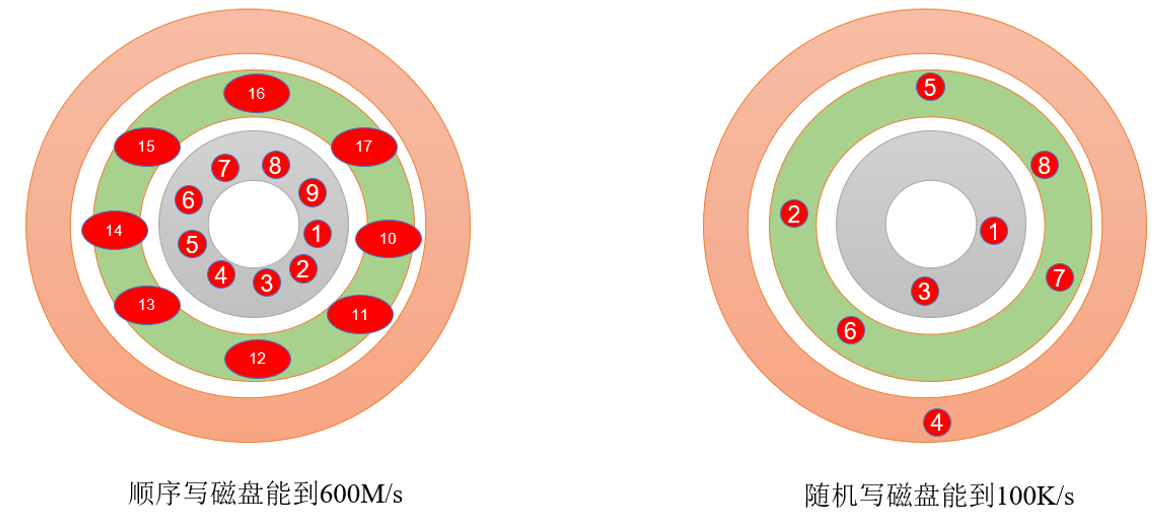
3)顺序写磁盘。
Kafka 的 producer 生产数据,要写入到 log 文件中,写的过程是一直追加到文件末端,为顺序写。官网有数据表明,同样的磁盘,顺序写能到 600M/s,而随机写只有 100K/s。这与磁盘的机械机构有关,顺序写之所以快,是因为其省去了大量磁头寻址的时间。
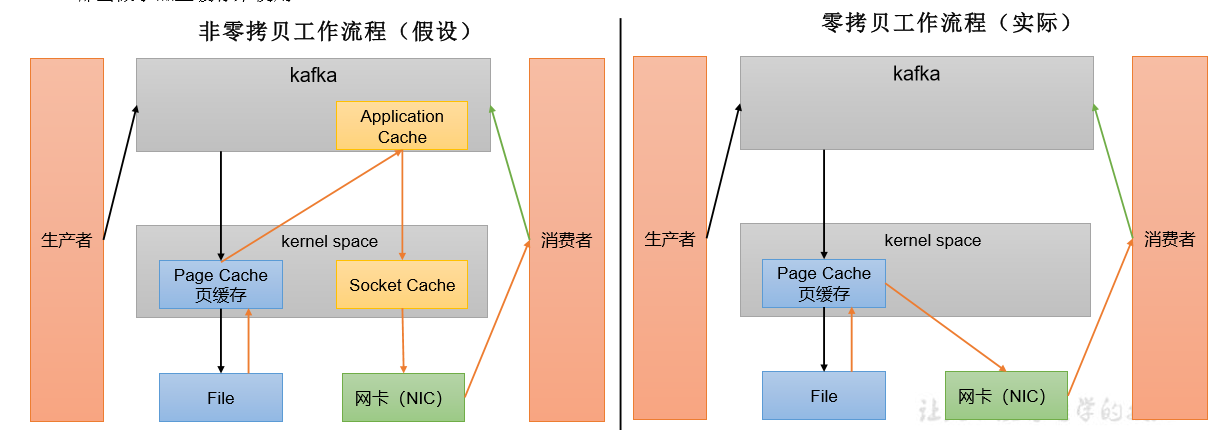
4)页缓存 + 零拷贝技术
零拷贝:Kafka 的数据加工处理操作交由 Kafka 生产者和 Kafka 消费者处理。Kafka Broker 应用层不关心存储的数据,所以就不用走应用层,传输效率高。
PageCache 页缓存:Kafka 重度依赖底层操作系统提供的 PageCache 功能。当上层有写操作时,操作系统只是将数据写入 PageCache。当读操作发生时,先从 PageCache 中查找,如果找不到,再去磁盘中读取。实际上 PageCache 是把尽可能多的空闲内存都当做了磁盘缓存来使用。
log.flush.interval.messages
强制页缓存刷写到磁盘的条数,默认是 long 的最大值,9223372036854775807。一般不建议修改,交给系统自己管理。log.flush.interval.ms
每隔多久,刷数据到磁盘,默认是 null。一般不建议修改,交给系统自己管理。
评论