
一、MM2 简介
在介绍 MM2 之前先谈一下 MM1, 这个是 kafka 很早之前就有的组件,本质来说就是实现了 consumer + producer, 从集群 A 将数据同步到集群 B, 使用的是 kafka client 的 high level api。如果网络不稳定,会有频繁 rebalance 问题。一个 MM1 实例是解决部分 topic 从集群 A—>B 的同步问题。所以如果我们有 N 个 kafka 集群, 那么为了满足所有同步需求,理论上我们要维护 N (N-1) 个实例, 如果算上每个实例只处理部分 topic 同步的话,那么需要维护的实例会更多。
MM2 是 MM1 的升级替代品,用于 kafka 集群间的数据同步,解决了 MM1 的很多问题,同时部署维护成本大大降低,以 N 个 kafka 集群为例,只需要部署 N 个 MM2 集群即可满足需求。基于更高抽象的 Kafka Connect framework 解决容错和水平扩展问题。内部基于 low level (assign) 来实现 topic 订阅, 没有频繁 rebalance 的问题, 对同步有更精准的控制。
MM2 具有如下特性:
- 基于 Kafka Connect framework 和生态
- 自动探测新 topic, partition
- 自动同步 topic 配置,自动同步 topic acl
- 支持 active-active 集群对,以及任意数量的 active 集群
- 支持跨 IDC 同步, aggregation 和其他复杂拓扑
- consumer offset 等 meta 信息的同步和翻译
- no rebalance,减少同步波动
- 提供广泛的指标,例如跨多个数据中心 / 集群的端到端复制延迟
- 容错和水平可扩展
MM2 架构如下:

MM2 基于 kafka connect framework 实现集群部署,通过 Connect Worker 来同步数据, 容错与水平扩展等由 Connect 框架保障。
MM2 主要有两种运行模式:Connector cluster 和 Driver, 我们采用的是 Driver 模式, 因为这种模式封装得更好,配置简洁,也是官方推荐的模式。
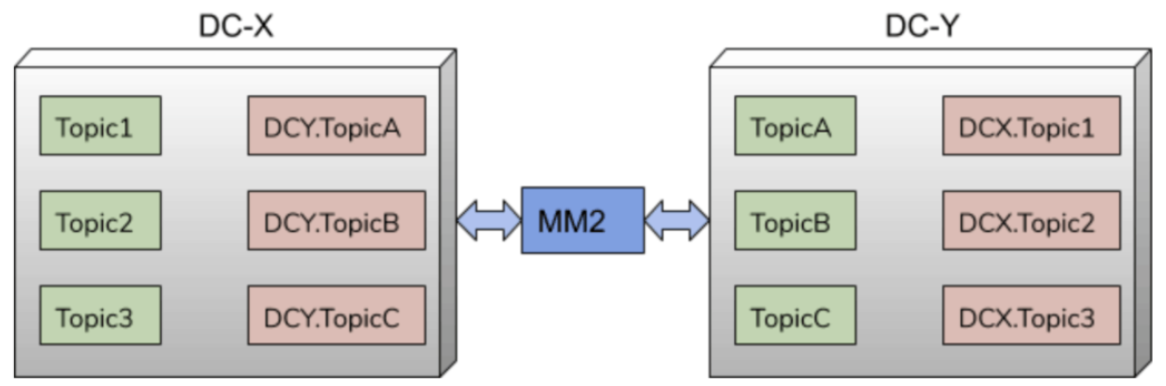
MM2 对于同步 topic 有前缀命名约定,默认情况下是 source clusterName, 当然也可以自定义,如下图所有,所有同步 topic 都包含有 source clusterName 前缀,这样做有两个好处:一是可以清楚知晓数据来源, 二是可以避免循环同步的问题。
下面介绍几个比较重要的内部 topic,可以说 MM2 的主要特性都依赖于这几个 topic:
checkpoint topic: 同步集群间 consumer group state,其中记录了 consumer offset 的映射关系,在 2.7.0 + 版本后还支持自动提交到 target cluster 的__consumer_offsets, 也可通过 translateOffsets () 接口手动翻译后提交offset_sync topic: 同步集群间 broker 端 offset 映射关系,分为 upstreamOffset 和 downstreamOffset, 其中 upstreamOffset 是上游 topic 的 offset (source 端), downstreamOffset 是下游 topic 的 offset (target 端)heartbeat topic: 用于监控 replication flows, 可以动态发现 replication topology,便于 MM2 动态分配同步任务
关于 MM2 的部署我们采用的方案是:每个 kafka 集群 (作为 target cluster) 部署一个 MM2 集群实例,部署在 k8s 上方便运维管理, 通过 jmx_prometheus_javaagent 将 metrics 暴露成 exporter 供 prometheus server 抓取, 然后通过 grafana 展示。

二、跨 IDC kafka 热备多活
在没有跨 IDC kafka 热备方案之前, 我们只有冷备方案,就是在集群 A 出现问题的情况下,手动将业务迁移到集群 B 上, 这种操作的代价是巨大的, 而且短时间内无法恢复,离线业务可能还好,实时业务是完全无法接受的。
下面列举了在冷备的情况下业务迁移面临的问题:
- 业务上下游的依赖问题,因为涉及到生产和消费的先后问题,各业务必须协调好顺序
- 沟通上下游各个业务做迁移,沟通成本很高
- 数据安全得不到保障,在生产端没有及时切换的情况下可能会丢数据,下游 pipeline 是否能处理完整数据也要打个问号
- 数据恢复时间过长,对于实时业务是无法容忍的
所以我们想是不是可以做到跨 IDC 的热备多活, 在一个 IDC 集群出问题的情况下, 业务可以快速切换恢复。
在没有 MM2 之前, 要实现两个集群的实时同步,特别是 consumer group state 的实时同步是比较困难的, 一个是日志的实时同步稳定性,之前已经说过 MM1 的稳定性和可维护性是比较差的,还有就是 offset 信息 (分为 broker offset, consumer offset) 两个集群是完全独立的, 需要一个 offset mapping 实时映射。之前 uber 自己实现过一个多 kafka 集群热备的方案,基于 uReplication 和自研组件,但是实现上有点复杂,需要维护的组件也较多。 在 MM2 发布之后,我们发现已经比较完美地解决了以上问题, 所以我们觉得基于 M2 实现热备是一个很好的方案, 当然在实现的过程中也遇到了很多问题, 下面也会逐一讲解。
三、设计目标
- 跨 IDC 容灾,在一个 IDC 不可用的情况下,业务可快速恢复
- 业务上下游 pipeline 可以解耦,各个业务切换完全独立,不需要协调上下游
- 切换代价尽量小,最好能不重启业务情况下切换集群
- 产品流程使用上尽量简单,将复杂度对业务屏蔽掉
这个是我们要实现的一个总体目标,主要是为了解决冷备情况下的痛点问题, 同时我们想通过产品化流程化将这个热备切换的过程对业务使用尽量简单。
四、设计方案
为了实现 Kafka 集群跨 IDC 容灾,首先要考虑的是如何同步,做单向同步还是双向同步,我们的需求是两个集群的 topic 数据是一致,且要上下游模块完全解耦, 显然单向同步不能满足我们的需求,因为对于在集群 A 的 producer 写入 topicT, 在 B 集群也必须要有 topicT, 否则 producer 就是无法迁移的, 所以我们只能使用双向同步的方案:即在集群 A, 集群 B 都有 topicT,然后双向同步。双向同步后无论 producer 写入的是哪个集群, 两个集群的 topic 数据是一致的。
下图以 IDC1 与 IDC2 的两个 Kafka 集群 Cluster A 与 Cluster B 之间双向同步 topicT 为例,consumer 消费 A 集群,其 offset 信息会通过 checkpoint topic 被实时同步给 B 集群, 这样当 A 集群不可用时就可以切换到 B 集群的 consumer 继续消费。对于 producer 的切换更加简单,只要切换写入 B 集群 topicT 即可,两个集群数据是一致的。
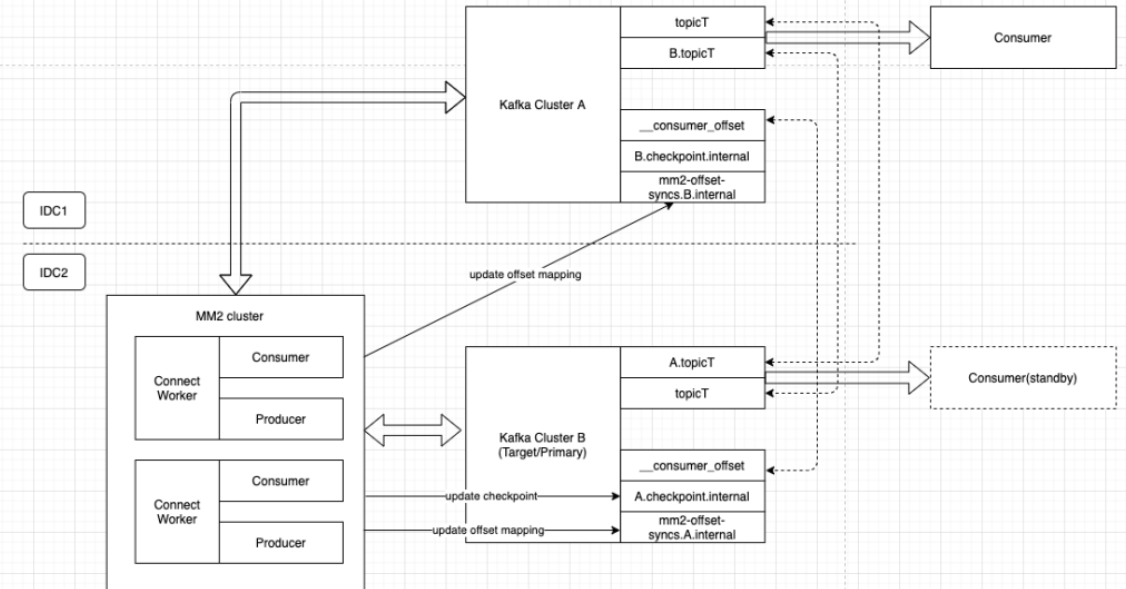
以下是我们热备多活方案简单示意图, producer 只要写成功一个集群即为成功, consumer 因为 group state 实时同步,所以 standby 的 consumer 随时可以切换消费。

3.1、MM2 支持动态修改同步配置
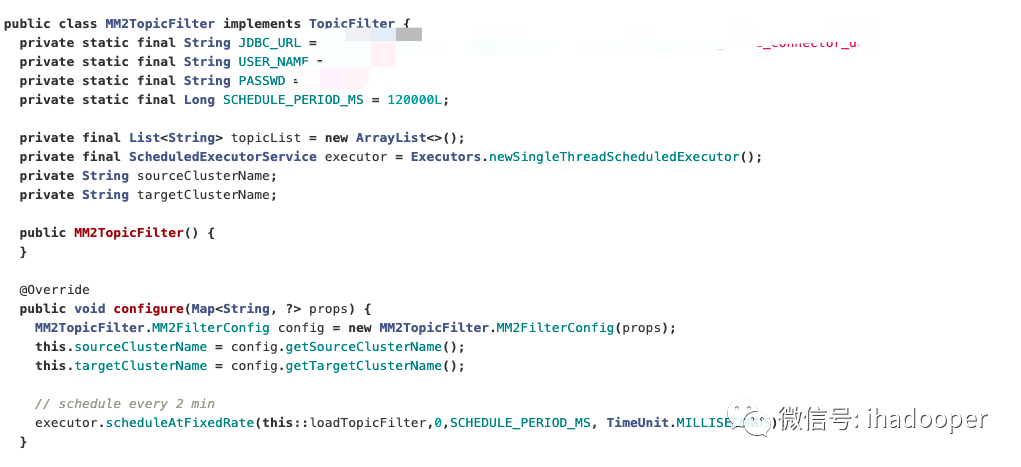
目前 MM2 不支持动态修改同步配置,但业务有对 topic 动态增减的需求,如果每次修改都需要重启 MM2 来实现的话,那么代价太大了。我们发现可以通过实现 TopicFilter,GroupFilter 接口来解决这个问题。我们使用 mysql 来存储 MM2 的同步 meta 信息, 那么在接口中动态查询获取 mysql 的信息即可满足动态加载同步信息的需求。重载 configure 方法,定期 update 数据库中同步配置信息,以下是代码片段:
3.2、MM2 不支持反向同步 consumer group state
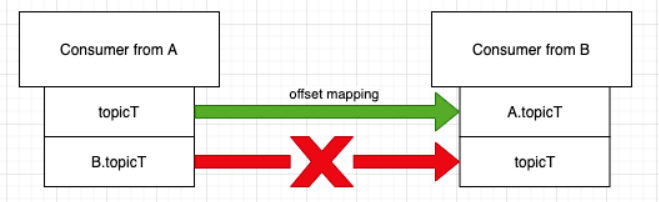
如上所示,对于 B.topicT 到 topicT 的 offset mapping 是不支持的,也就是 mm2 的 checkpoint 同步是单向的。比如 topicT 从 cluster A 同步到 cluster B, consumer c 在 cluster A 消费 topicT. cluster B 会通过 A.checkpoints.internel topic 获取 consumer c 的 state 信息,其中有 topicT —>A.topicT 的映射关系,但 B.topicT --> topicT 的反向映射关系是没有的, 但为了做 consumer offset 实时同步,这个反向映射也是要支持的,否则就是不完整的。
那么如何获得 offset 反向映射呢, 我们要利用 B 集群的 mm2-offset-syncs.A.internal 这个 topic, 里面记录的是 A 集群同步到 B 集群的 topic 的 broker offset mapping 信息。 我们可以从 B.topicT 的 offset 信息加上两个集群的 broker offset 的差值 delta 来计算出 B 集群中 topicT 对应的 offset 信息,计算方法如下:
现在我们假设 B.topicT 的 offset 为 offset,upstreamOffset 与 downstreamOffset 是 mm2-offset-syncs.A.internal 这个 topic 中记录的 broker offset 映射关系
delta = upstreamOffset - downstreamOffset
reverseOffset = offset + delta
3.3、业务触发式切换集群实现
默认情况下,在集群切换的过程中还是需要业务介入的, 需要修改 target 集群的配置信息,起码 bootstrap.servers, topic 列表是要变更的, 然后重启恢复业务。 但重启业务对线上服务总是会有影响的,有没有办法可以在不重启业务的情况下完成切换呢?
我们基于 librdkafka/kafka clients 封装了 c++, java 的客户端, 可以在客户端框架层面完成对切换动作的封装,这样上层业务就不需要做重启了。具体做法是基于 “客户端框架 + 配置中心” 的方式来实现。目前配置中心我们支持 apollo, mysql 的触发方式。业务在我们 ultron 平台发起切换流程,审批通过后触发切换集群,业务无需重启业务。
产品化
为了让业务容易理解使用热备方案,将双向同步,offset 映射等概念封装屏蔽掉, 我们在产品化过程中引入了热备属性的概念。
热备的属性与定义如下:
- 热备 topic:topic 在两个集群间双向同步
- 热备 producer:只生产热备 topic 的 producer, 且所有 topic 热备的 target 集群是需要一致的
- 热备 consumer:只消费热备 topic 的 consumer, 且所有 topic 热备的 target 集群是需要一致的, 两个热备 consumer group state 实时同步
业务申请热备 topic, producer,consumer 之后,我们 ultron 平台会完成如下动作: - 对热备 topic 配置双向同步
- 两个集群热备的 consumer group state 实时同步
- 授权每个项目用户对应的 topic, group 读写权限
四、产品化
为了让业务容易理解使用热备方案,将双向同步,offset 映射等概念封装屏蔽掉, 在产品化过程中引入了热备属性的概念。
热备的属性与定义如下:
- 热备 topic:topic 在两个集群间双向同步
- 热备 producer:只生产热备 topic 的 producer, 且所有 topic 热备的 target 集群是需要一致的
- 热备 consumer:只消费热备 topic 的 consumer, 且所有 topic 热备的 target 集群是需要一致的, 两个热备 consumer group state 实时同步
业务申请热备 topic, producer,consumer 之后,平台会完成如下动作:
- 对热备 topic 配置双向同步
- 两个集群热备的 consumer group state 实时同步
- 授权每个项目用户对应的 topic, group 读写权限
对于热备 topic, 我们支持业务级别的切换,即 producer, consumer 级别的切换,因为有时候业务可能是写入部分 partition 或消费某个 group 有问题,这个时候只需要某个模块的按需切换即可。 如果是整个 kafka 集群的不可用或 IDC 不可用这种情况, 那么各个业务独立完成切换即可。
如果某个 IDC 的 kafka 集群不可用了,那么业务只需要在界面上申请切换集群,审批通过后,当前生效集群及配置会动态改变,由于我们的 consumer offset 信息是实时同步的, 业务修改参数后重启即可。如果业务基于我们的客户端框架则可实现触发式切换,业务无需重启。
五、需要注意的风险
这里主要考虑数据完整性风险。首先依赖于 producer 端的设置:
- producer 端有 retries=Long.MAX_VALUE,acks=ALL 设置, 在 send fail 情况下有持久化机制, 在切换集群后可以恢复发送。
- 如果 producer 没有 retry 机制,也没有持久化机制,那么 producer 端就会丢数据,那么数据保障性就无从谈起
其次是 MM2 日志同步的完整性,以上述集群 A (主集群), 集群 B (备集群) 为例:
- 如果集群 A 宕机且无法恢复, 那么 MM2 是会有少量日志丢失的。
- 如果集群 A 宕机且能恢复那么 MM2 能接着同步完,这时候 MM2 支持 at least once 语义。
评论