
一、数据仓库设计
1.1、数据仓库分层规划
优秀可靠的数仓体系,需要良好的数据分层结构。合理的分层,能够使数据体系更加清晰,使复杂问题得以简化。以下是该项目的分层规划。

1.2、数据仓库构建流程
以下是构建数据仓库的完整流程。
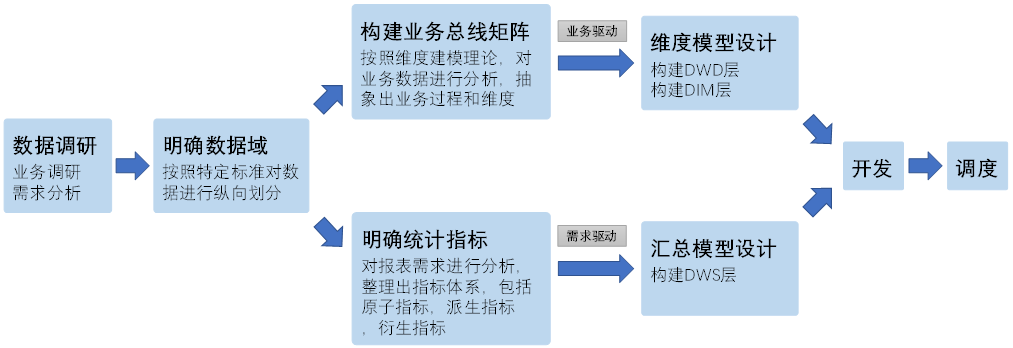
1、数据调研
数据调研重点要做两项工作,分别是业务调研和需求分析。这两项工作做的是否充分,直接影响着数据仓库的质量。
1)业务调研
业务调研的主要目标是熟悉业务流程、熟悉业务数据。
熟悉业务流程要求做到,明确每个业务的具体流程,需要将该业务所包含的每个业务过程一一列举出来。
熟悉业务数据要求做到,将数据(包括埋点日志和业务数据表)与业务过程对应起来,明确每个业务过程会对哪些表的数据产生影响,以及产生什么影响。产生的影响,需要具体到,是新增一条数据,还是修改一条数据,并且需要明确新增的内容或者是修改的逻辑。
2)需求分析
典型的需求指标如,最近一天各省份手机品类订单总额。
分析需求时,需要明确需求所需的业务过程及维度,例如该需求所需的业务过程就是买家下单,所需的维度有日期,省份,商品品类。
3)总结
做完业务分析和需求分析之后,要保证每个需求都能找到与之对应的业务过程及维度。若现有数据无法满足需求,则需要和业务方进行沟通,例如某个页面需要新增某个行为的埋点。
2、明确数据域
数据仓库模型设计除横向的分层外,通常也需要根据业务情况进行纵向划分数据域。
划分数据域的意义是便于数据的管理和应用。
通常可以根据业务过程或者部门进行划分,本项目根据业务过程进行划分,需要注意的是一个业务过程只能属于一个数据域。
3、构建业务总线矩阵
业务总线矩阵中包含维度模型所需的所有事实(业务过程)以及维度,以及各业务过程与各维度的关系。矩阵的行是一个个业务过程,矩阵的列是一个个的维度,行列的交点表示业务过程与维度的关系。
一个业务过程对应维度模型中一张事务型事实表,一个维度则对应维度模型中的一张维度表。所以构建业务总线矩阵的过程就是设计维度模型的过程。但是需要注意的是,总线矩阵中通常只包含事务型事实表,另外两种类型的事实表需单独设计。
按照事务型事实表的设计流程,选择业务过程声明粒度确认维度确认事实。
4、明确统计指标
明确统计指标具体的工作是,深入分析需求,构建指标体系。构建指标体系的主要意义就是指标定义标准化。所有指标的定义,都必须遵循同一套标准,这样能有效的避免指标定义存在歧义,指标定义重复等问题。
1)指标体系相关概念
(1)原子指标
原子指标基于某一业务过程的度量值,是业务定义中不可再拆解的指标,原子指标的核心功能就是对指标的聚合逻辑进行了定义。我们可以得出结论,原子指标包含三要素,分别是业务过程、度量值和聚合逻辑。
例如订单总额就是一个典型的原子指标,其中的业务过程为用户下单、度量值为订单金额,聚合逻辑为sum()求和。需要注意的是原子指标只是用来辅助定义指标一个概念,通常不会对应有实际统计需求与之对应。
(2)派生指标
派生指标基于原子指标,其与原子指标的关系如下图所示。
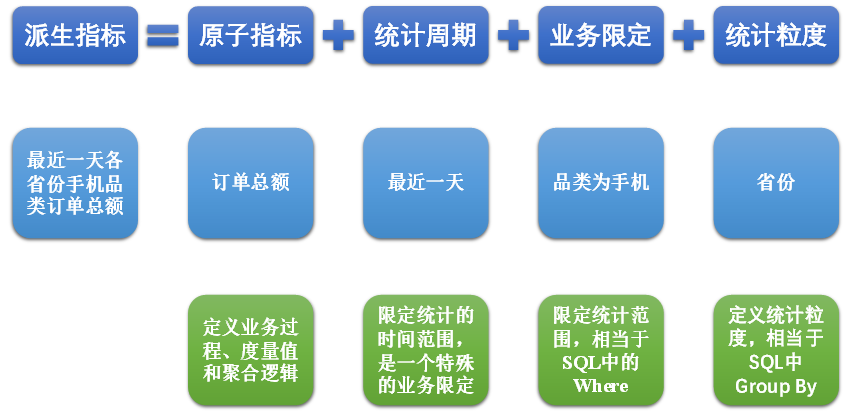
与原子指标不同,派生指标通常会对应实际的统计需求。请从图中的例子中,体会指标定义标准化的含义。
(3)衍生指标
衍生指标是在一个或多个派生指标的基础上,通过各种逻辑运算复合而成的。例如比率、比例等类型的指标。衍生指标也会对应实际的统计需求。
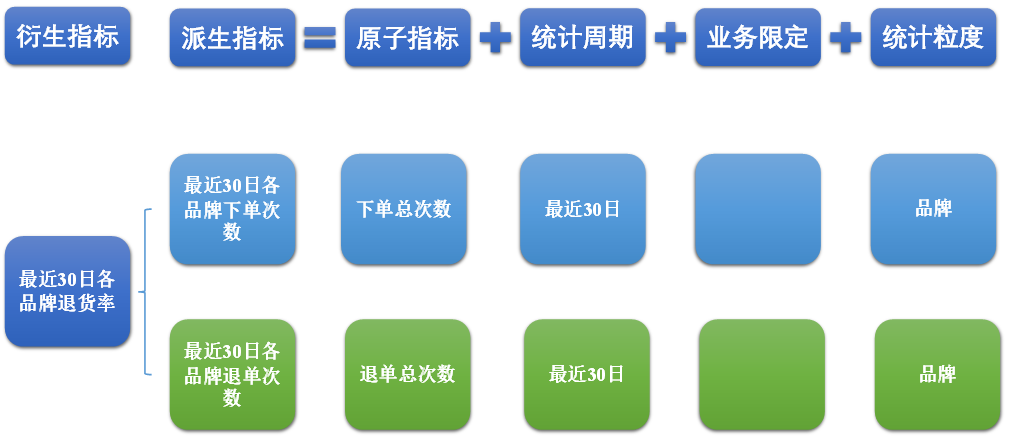
2)指标体系对于数仓建模的意义
通过上述两个具体的案例可以看出,绝大多数的统计需求,都可以使用原子指标、派生指标以及衍生指标这套标准去定义。同时能够发现这些统计需求都直接的或间接的对应一个或者是多个派生指标。
当统计需求足够多时,必然会出现部分统计需求对应的派生指标相同的情况。这种情况下,我们就可以考虑将这些公共的派生指标保存下来,这样做的主要目的就是减少重复计算,提高数据的复用性。
这些公共的派生指标统一保存在数据仓库的DWS层。因此DWS层设计,就可以参考我们根据现有的统计需求整理出的派生指标。
4、维度模型设计
维度模型的设计参照上述得到的业务总线矩阵即可。事实表存储在DWD层,维度表存储在DIM层。
5、汇总模型设计
汇总模型的设计参考上述整理出的指标体系(主要是派生指标)即可。汇总表与派生指标的对应关系是,一张汇总表通常包含业务过程相同、统计周期相同、统计粒度相同的多个派生指标。
评论