
Flink 相关的组件和作业的稳定性通常是比较关键的,所以得需要对它们进行监控,如果有异常,则需要及时告警通知。本章关于如何利用现有 Flink UI 上面的信息去发现和排查问题,会指明一些比较重要和我们非常关心的指标,通过这些指标我们能够立马定位到问题的根本原因。利用现有的 Metrics Reporter 去构建一个 Flink 的监控系统,它可以收集到所有作业的监控指标,并会存储这些监控指标数据,最后还会有一个监控大盘做数据可视化,通过这个大盘可以方便排查问题。
一、实时监控 Flink 及其作业
当将 Flink JobManager、TaskManager 都运行起来了,并且也部署了不少 Flink Job,那么它到底是否还在运行、运行的状态如何、资源 TaskManager 和 Slot 的个数是否足够、Job 内部是否出现异常、计算速度是否跟得上数据生产的速度 等这些问题其实对我们来说是比较关注的,所以就很迫切的需要一个监控系统帮我们把整个 Flink 集群的运行状态给展示出来。通过监控系统我们能够很好的知道 Flink 内部的整个运行状态,然后才能够根据项目生产环境遇到的问题 ‘对症下药’。下面分别来讲下 JobManager、TaskManager、Flink Job 的监控以及最关心的一些监控指标。
1.1、监控 JobManager
JobManager 是 Flink 集群的中控节点,类似于 Apache Storm 的 Nimbus 以及 Apache Spark 的 Driver 的角色。它负责作业的调度、作业 Jar 包的管理、Checkpoint 的协调和发起、与 TaskManager 之间的心跳检查等工作。如果 JobManager 出现问题的话,就会导致作业 UI 信息查看不了,TaskManager 和所有运行的作业都会受到一定的影响,所以这也是为啥在 7.1 节中强调 JobManager 的高可用问题。
在 Flink 自带的 UI 上 JobManager 那个 Tab 展示的其实并没有显示其对应的 Metrics,那么对于 JobManager 来说常见比较关心的监控指标有哪些?
基础指标
因为 Flink JobManager 其实也是一个 Java 的应用程序,那么它自然也会有 Java 应用程序的指标,比如内存、CPU、GC、类加载、线程信息等。
1、内存:内存又分堆内存和非堆内存,在 Flink 中还有 Direct 内存,每种内存又有初始值、使用值、最大值等指标,因为在 JobManager 中的工作其实相当于 TaskManager 来说比较少,也不存储事件数据,所以通常 JobManager 占用的内存不会很多,在 Flink JobManager 中自带的内存 Metrics 指标有:
jobmanager_Status_JVM_Memory_Direct_Count
jobmanager_Status_JVM_Memory_Direct_MemoryUsed
jobmanager_Status_JVM_Memory_Direct_TotalCapacity
jobmanager_Status_JVM_Memory_Heap_Committed
jobmanager_Status_JVM_Memory_Heap_Max
jobmanager_Status_JVM_Memory_Heap_Used
jobmanager_Status_JVM_Memory_Mapped_Count
jobmanager_Status_JVM_Memory_Mapped_MemoryUsed
jobmanager_Status_JVM_Memory_Mapped_TotalCapacity
jobmanager_Status_JVM_Memory_NonHeap_Committed
jobmanager_Status_JVM_Memory_NonHeap_Max
jobmanager_Status_JVM_Memory_NonHeap_Used
2、CPU:JobManager 分配的 CPU 使用情况,如果使用类似 K8S 等资源调度系统,则需要对每个容器进行设置资源,比如 CPU 限制不能超过多少,在 Flink JobManager 中自带的 CPU 指标有:
jobmanager_Status_JVM_CPU_Load
jobmanager_Status_JVM_CPU_Time
3、GC:GC 信息对于 Java 应用来说是避免不了的,每种 GC 都有时间和次数的指标可以供参考,提供的指标有:
jobmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Count
jobmanager_Status_JVM_GarbageCollector_PS_MarkSweep_Time
jobmanager_Status_JVM_GarbageCollector_PS_Scavenge_Count
jobmanager_Status_JVM_GarbageCollector_PS_Scavenge_Time
Checkpoint 指标
因为 JobManager 负责了作业的 Checkpoint 的协调和发起功能,所以 Checkpoint 相关的指标就有表示 Checkpoint 执行的时间、Checkpoint 的时间长短、完成的 Checkpoint 的次数、Checkpoint 失败的次数、Checkpoint 正在执行 Checkpoint 的个数等,其对应的指标如下:
jobmanager_job_lastCheckpointAlignmentBuffered
jobmanager_job_lastCheckpointDuration
jobmanager_job_lastCheckpointExternalPath
jobmanager_job_lastCheckpointRestoreTimestamp
jobmanager_job_lastCheckpointSize
jobmanager_job_numberOfCompletedCheckpoints
jobmanager_job_numberOfFailedCheckpoints
jobmanager_job_numberOfInProgressCheckpoints
jobmanager_job_totalNumberOfCheckpoints
重要的指标
另外还有比较重要的指标就是 Flink UI 上也提供的,类似于 Slot 总共个数、Slot 可使用的个数、TaskManager 的个数(通过查看该值可以知道是否有 TaskManager 发生异常重启)、正在运行的作业数量、作业运行的时间和完成的时间、作业的重启次数,对应的指标如下:
jobmanager_job_uptime
jobmanager_numRegisteredTaskManagers
jobmanager_numRunningJobs
jobmanager_taskSlotsAvailable
jobmanager_taskSlotsTotal
jobmanager_job_downtime
jobmanager_job_fullRestarts
jobmanager_job_restartingTime
1.2、监控 TaskManager
taskmanager_Status_JVM_CPU_Load
taskmanager_Status_JVM_CPU_Time
taskmanager_Status_JVM_ClassLoader_ClassesLoaded
taskmanager_Status_JVM_ClassLoader_ClassesUnloaded
taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Count
taskmanager_Status_JVM_GarbageCollector_G1_Old_Generation_Time
taskmanager_Status_JVM_GarbageCollector_G1_Young_Generation_Count
taskmanager_Status_JVM_GarbageCollector_G1_Young_Generation_Time
taskmanager_Status_JVM_Memory_Direct_Count
taskmanager_Status_JVM_Memory_Direct_MemoryUsed
taskmanager_Status_JVM_Memory_Direct_TotalCapacity
taskmanager_Status_JVM_Memory_Heap_Committed
taskmanager_Status_JVM_Memory_Heap_Max
taskmanager_Status_JVM_Memory_Heap_Used
taskmanager_Status_JVM_Memory_Mapped_Count
taskmanager_Status_JVM_Memory_Mapped_MemoryUsed
taskmanager_Status_JVM_Memory_Mapped_TotalCapacity
taskmanager_Status_JVM_Memory_NonHeap_Committed
taskmanager_Status_JVM_Memory_NonHeap_Max
taskmanager_Status_JVM_Memory_NonHeap_Used
taskmanager_Status_JVM_Threads_Count
taskmanager_Status_Network_AvailableMemorySegments
taskmanager_Status_Network_TotalMemorySegments
taskmanager_Status_Shuffle_Netty_AvailableMemorySegments
taskmanager_Status_Shuffle_Netty_TotalMemorySegments
1.3、监控 Flink 作业
taskmanager_job_task_Shuffle_Netty_Input_Buffers_outPoolUsage
taskmanager_job_task_Shuffle_Netty_Input_Buffers_outputQueueLength
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inPoolUsage
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inputExclusiveBuffersUsage
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inputFloatingBuffersUsage
taskmanager_job_task_Shuffle_Netty_Output_Buffers_inputQueueLength
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInLocal
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInLocalPerSecond
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInRemote
taskmanager_job_task_Shuffle_Netty_Output_numBuffersInRemotePerSecond
taskmanager_job_task_Shuffle_Netty_Output_numBytesInLocal
taskmanager_job_task_Shuffle_Netty_Output_numBytesInLocalPerSecond
taskmanager_job_task_Shuffle_Netty_Output_numBytesInRemote
taskmanager_job_task_Shuffle_Netty_Output_numBytesInRemotePerSecond
taskmanager_job_task_buffers_inPoolUsage
taskmanager_job_task_buffers_inputExclusiveBuffersUsage
taskmanager_job_task_buffers_inputFloatingBuffersUsage
taskmanager_job_task_buffers_inputQueueLength
taskmanager_job_task_buffers_outPoolUsage
taskmanager_job_task_buffers_outputQueueLength
taskmanager_job_task_checkpointAlignmentTime
taskmanager_job_task_currentInputWatermark
taskmanager_job_task_numBuffersInLocal
taskmanager_job_task_numBuffersInLocalPerSecond
taskmanager_job_task_numBuffersInRemote
taskmanager_job_task_numBuffersInRemotePerSecond
taskmanager_job_task_numBuffersOut
taskmanager_job_task_numBuffersOutPerSecond
taskmanager_job_task_numBytesIn
taskmanager_job_task_numBytesInLocal
taskmanager_job_task_numBytesInLocalPerSecond
taskmanager_job_task_numBytesInPerSecond
taskmanager_job_task_numBytesInRemote
taskmanager_job_task_numBytesInRemotePerSecond
taskmanager_job_task_numBytesOut
taskmanager_job_task_numBytesOutPerSecond
taskmanager_job_task_numRecordsIn
taskmanager_job_task_numRecordsInPerSecond
taskmanager_job_task_numRecordsOut
taskmanager_job_task_numRecordsOutPerSecond
taskmanager_job_task_operator_currentInputWatermark
taskmanager_job_task_operator_currentOutputWatermark
taskmanager_job_task_operator_numLateRecordsDropped
taskmanager_job_task_operator_numRecordsIn
taskmanager_job_task_operator_numRecordsInPerSecond
taskmanager_job_task_operator_numRecordsOut
taskmanager_job_task_operator_numRecordsOutPerSecond
二、Flink 监控系统搭建
2.1、利用 API 获取监控数据
这里通过 Chrome 浏览器的控制台来查看一下有哪些 REST API 是用来提供监控数据的。
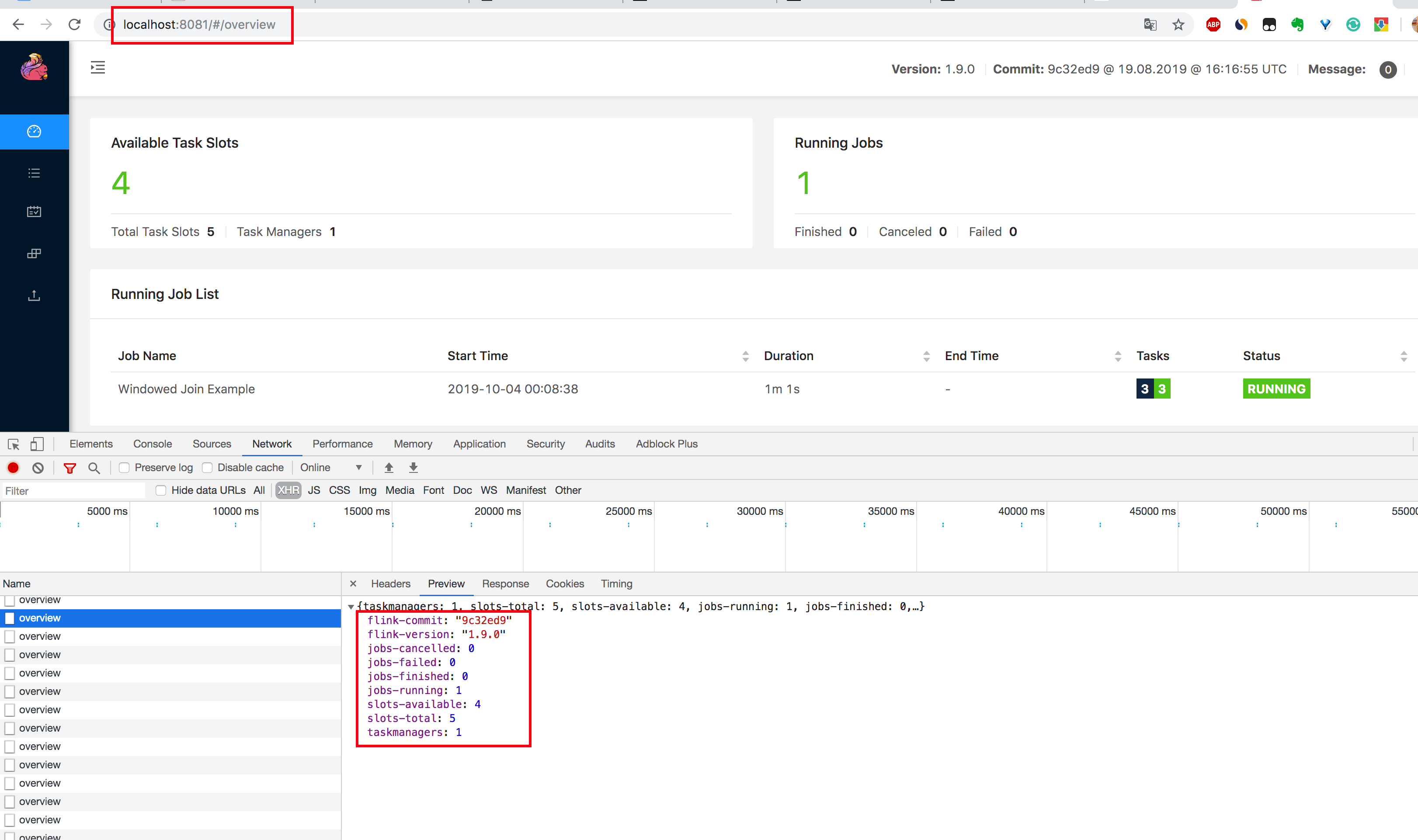
1、在 Chrome 浏览器中打开 http://localhost:8081/overview 页面,可以获取到整个 Flink 集群的资源信息:TaskManager 个数(TaskManagers)、Slot 总个数(Total Task Slots)、可用 Slot 个数(Available Task Slots)、Job 运行个数(Running Jobs)、Job 运行状态(Finished 0 Canceled 0 Failed 0)等,如下图所示。
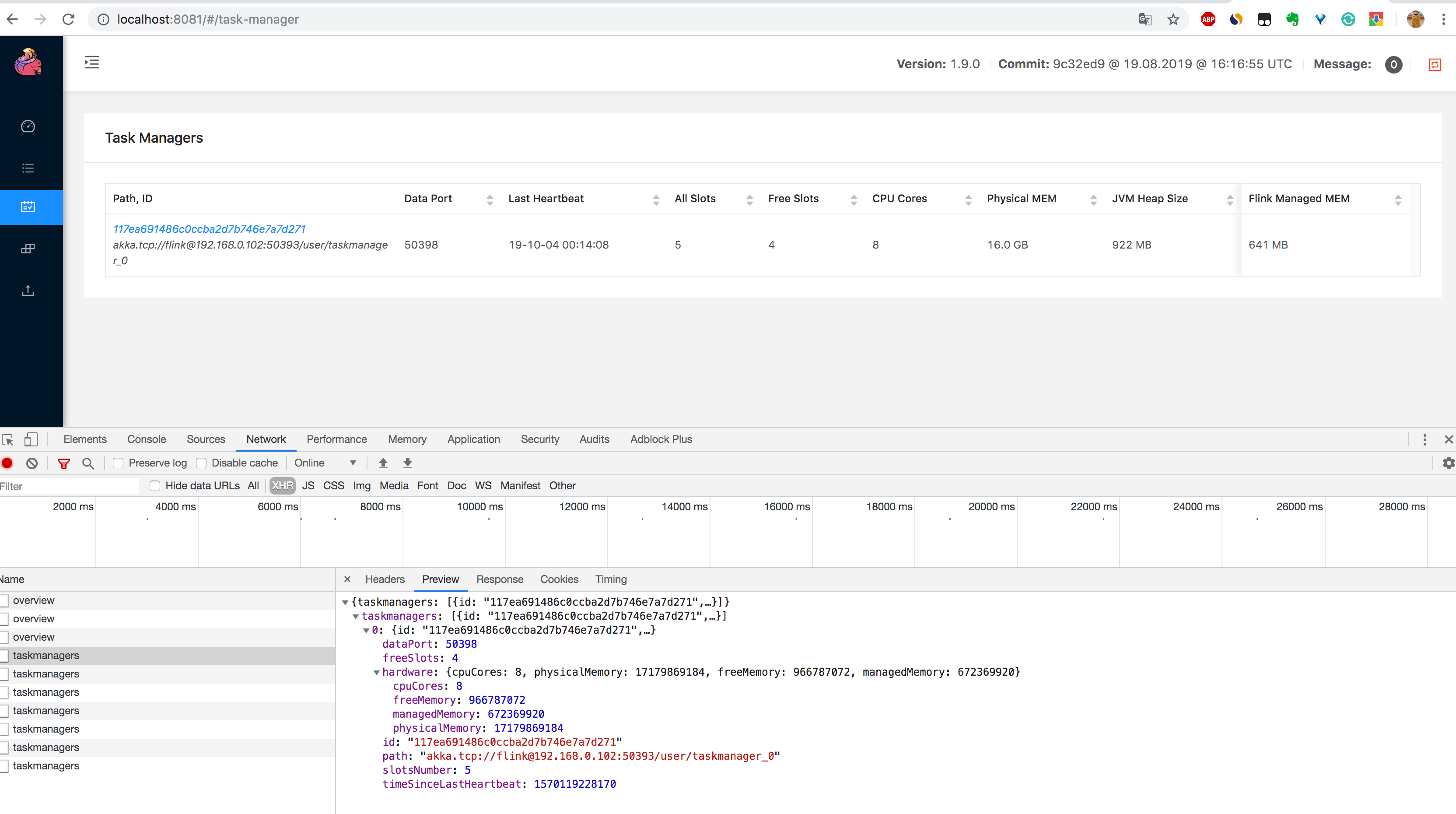
2、通过 http://localhost:8081/taskmanagers 页面查看 TaskManager 列表,可以知道该集群下所有 TaskManager 的信息(数据端口号(Data Port)、上一次心跳时间(Last Heartbeat)、总共的 Slot 个数(All Slots)、空闲的 Slot 个数(Free Slots)、以及 CPU 和内存的分配使用情况,如下图所示。
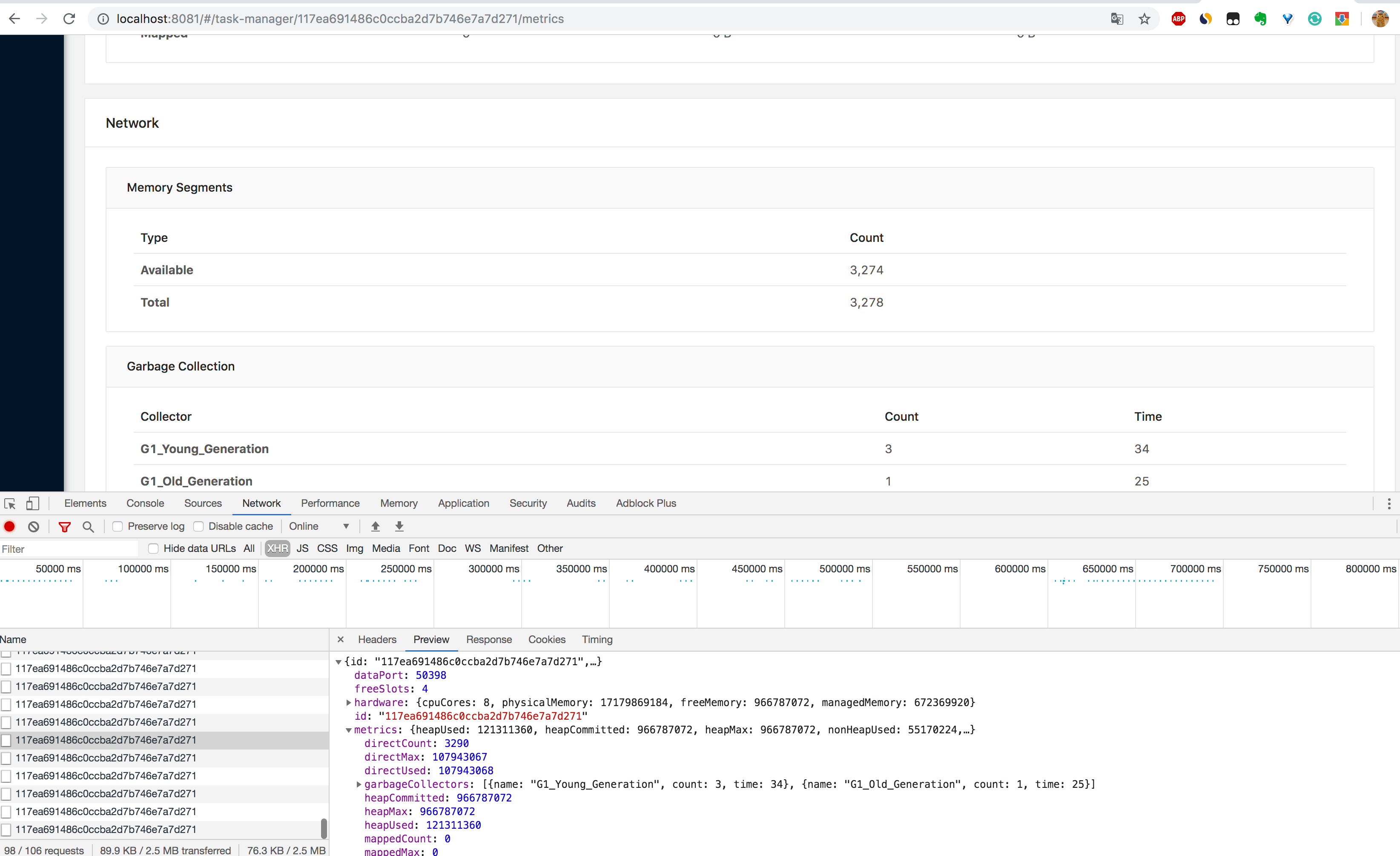
3、通过 http://localhost:8081/taskmanagers/tm_id 页面查看 TaskManager 的具体情况(这里的 tm_id 是个随机的 UUID 值)。在这个页面上,除了上一条的监控信息可以查看,还可以查看该 TaskManager 的 JVM(堆和非堆)、Direct 内存、网络、GC 次数和时间,如下图所示。内存和 GC 这些信息非常重要,很多时候 TaskManager 频繁重启的原因就是 JVM 内存设置得不合理,导致频繁的 GC,最后使得 OOM 崩溃,不得不重启。
另外如果你在 /taskmanagers/tm_id 接口后面加个 /log 就可以查看该 TaskManager 的日志,注意,在 Flink 中的日志和平常自己写的应用中的日志是不一样的。在 Flink 中,日志是以 TaskManager 为概念打印出来的,而不是以单个 Job 打印出来的,如果你的 Job 在多个 TaskManager 上运行,那么日志就会在多个 TaskManager 中打印出来。如果一个 TaskManager 中运行了多个 Job,那么它里面的日志就会很混乱,查看日志时会发现它为什么既有这个 Job 打出来的日志,又有那个 Job 打出来的日志。
对于这种设计是否真的好,不同的人有不同的看法,在 Flink 的 Issue 中就有人提出了该问题,Issue 中的描述是希望日志可以是 Job 与 Job 之间的隔离,这样日志更方便采集和查看,对于排查问题也会更快。对此国内有公司也对这一部分做了改进。
4、通过 http://localhost:8081/#/job-manager/config 页面可以看到可 JobManager 的配置信息,另外通过 http://localhost:8081/jobmanager/log 页面可以查看 JobManager 的日志详情。
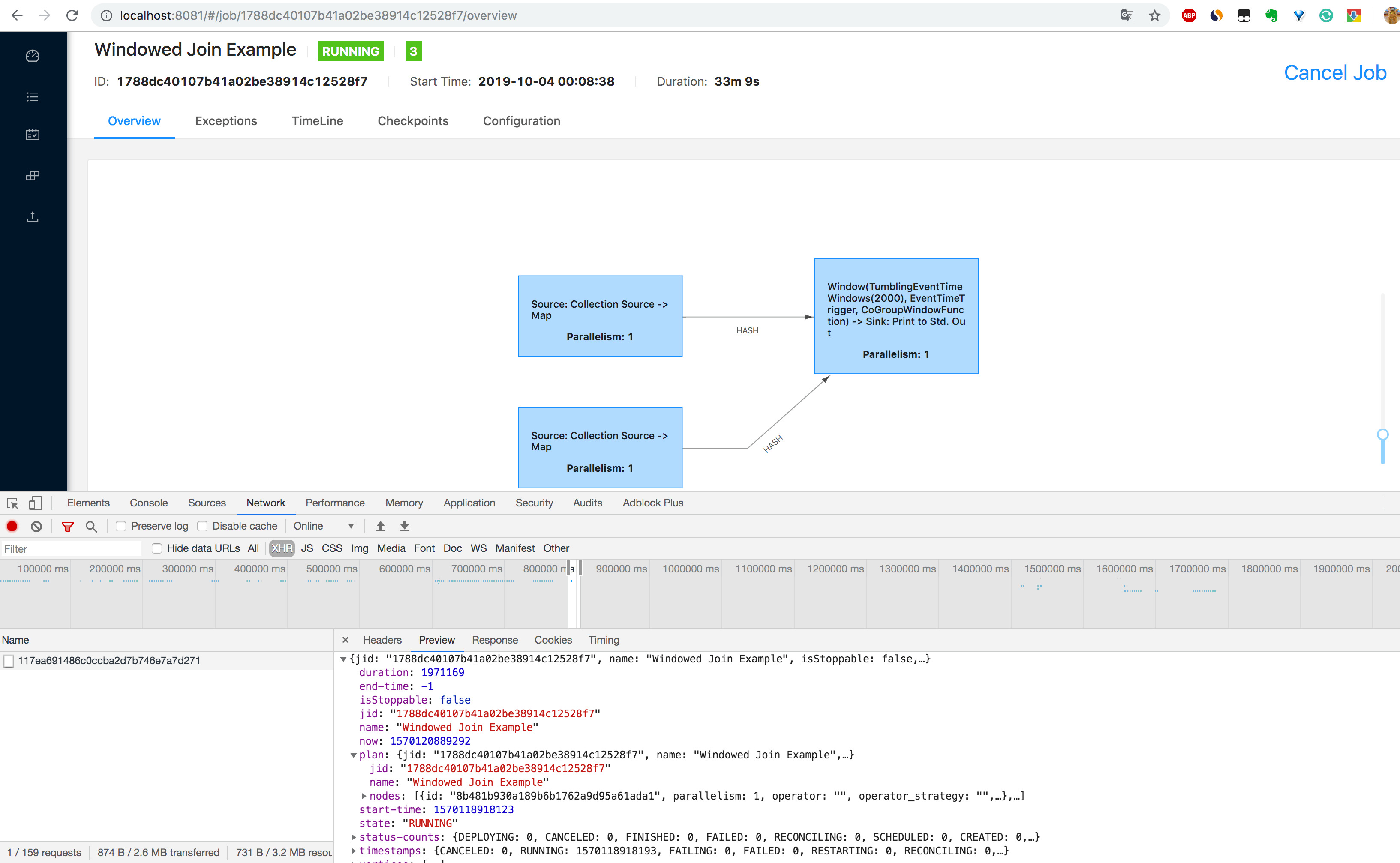
5、通过 http://localhost:8081/jobs/job_id 页面可以查看 Job 的监控数据,如下图所示,由于指标(包括了 Job 的 Task 数据、Operator 数据、Exception 数据、Checkpoint 数据等)过多,可以自己在本地测试查看。
上面列举了几个 REST API(不是全部),主要是为了告诉大家,其实这些接口我们都知道,那么我们也可以利用这些接口去获取对应的监控数据,然后绘制出更酷炫的图表,用更直观的页面将这些数据展示出来,这样就能更好地控制。
除了利用 Flink UI 提供的接口去定时获取到监控数据,其实 Flink 还提供了很多的 reporter 去上报监控数据,比如 JMXReporter、PrometheusReporter、PrometheusPushGatewayReporter、InfluxDBReporter、StatsDReporter 等,这样就可以根据需求去定制获取到 Flink 的监控数据,下面教大家使用几个常用的 reporter。
相关 Rest API 可以查看官网链接:rest-api-integration
2.2、Metrics 类型简介
可以在继承自 RichFunction 的函数中通过 getRuntimeContext().getMetricGroup() 获取 Metric 信息,常见的 Metrics 的类型有 Counter、Gauge、Histogram、Meter。
评论